


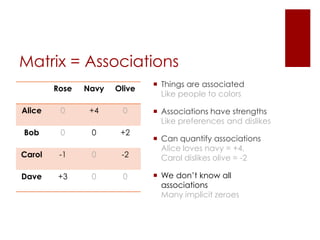

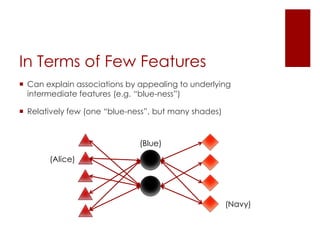
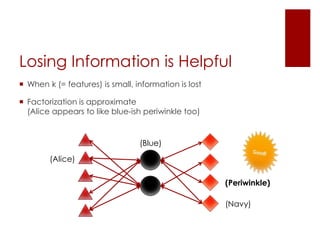
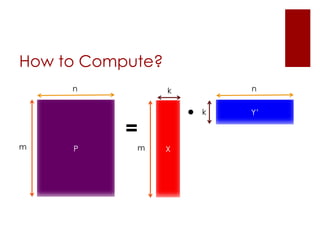
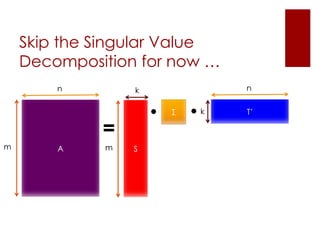

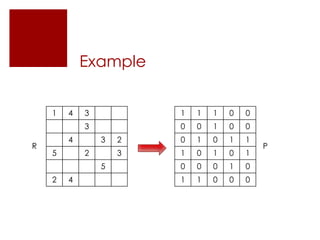
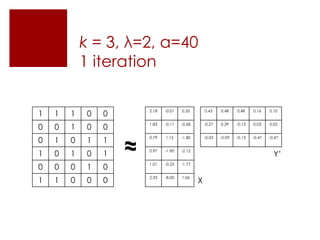
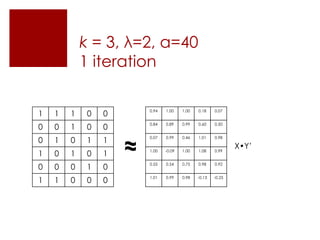
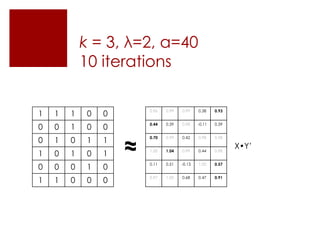





This document discusses matrix factorization techniques for recommendation systems. It explains that user-item interaction data can be represented as a matrix and decomposed into two lower-rank matrices that capture latent features. One matrix represents users and the other represents items. The document outlines an alternating least squares algorithm to compute the decomposed matrices and discusses how the technique can be implemented in Apache Mahout and Myrrix for scalable recommendations.

















































![Big Data [sorry] & Data Science: What Does a Data Scientist Do?](https://cdn.slidesharecdn.com/ss_thumbnails/dslatcloudmsevent20130125-130126065651-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


























![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)










