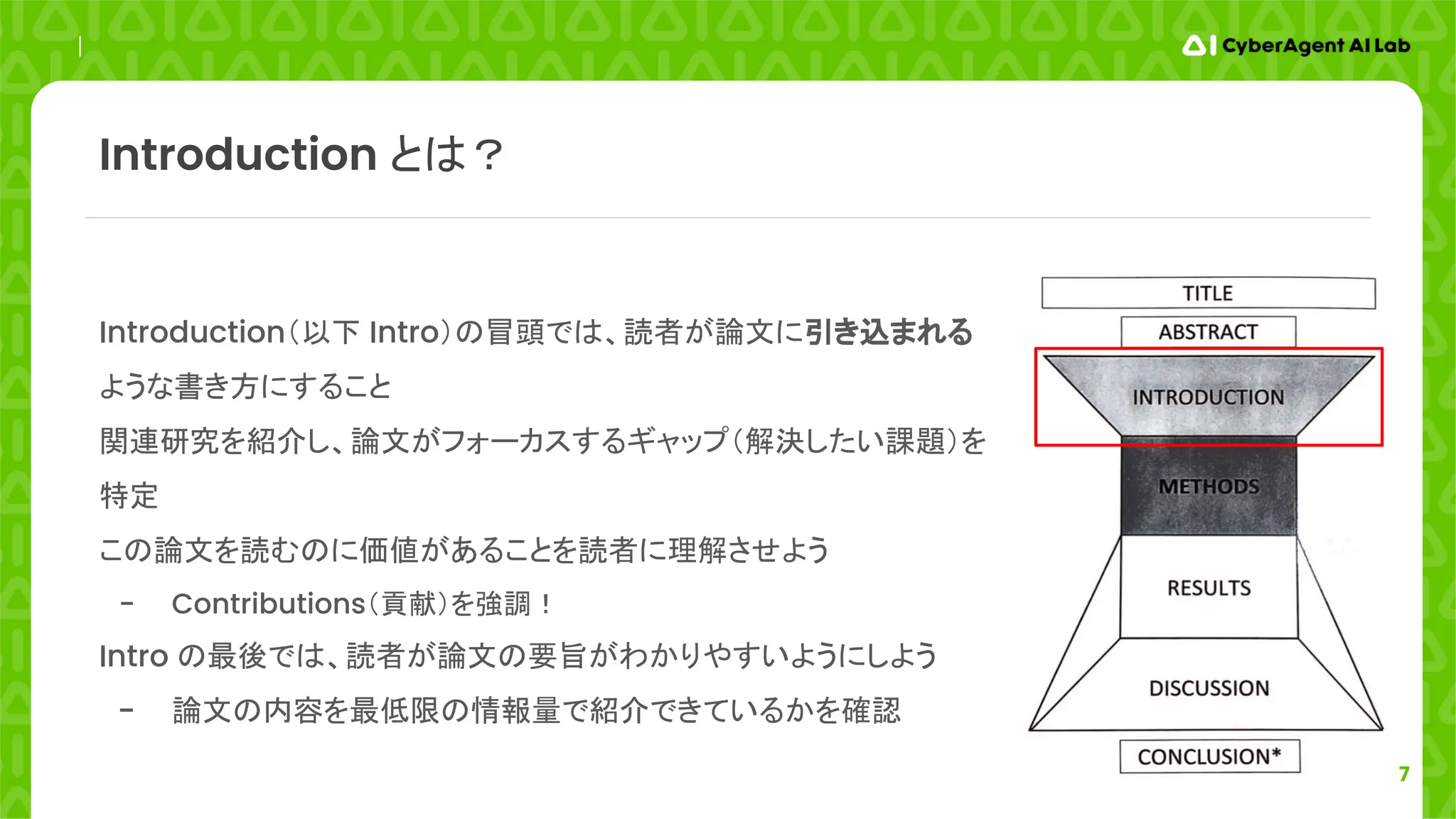
8
Recognition of humanactions in videos is a challenging task which has received a significant amount
of attention in the research community [11, 14, 17, 26].
このような文章は情報量がないため、最近はあまり使われない
Compared to still image classification, the temporal component of videos provides an additional (and
important) clue for recognition
論文のタスクを、より一般的なシナリオ(画像分類)と比較しながら導入し、動画データの特性を述べ
る(一般的 → 具体的)
In this work, we aim at extending deep Convolutional Networks [19] to action recognition in video
問題を明確にした後、研究の目的を指摘
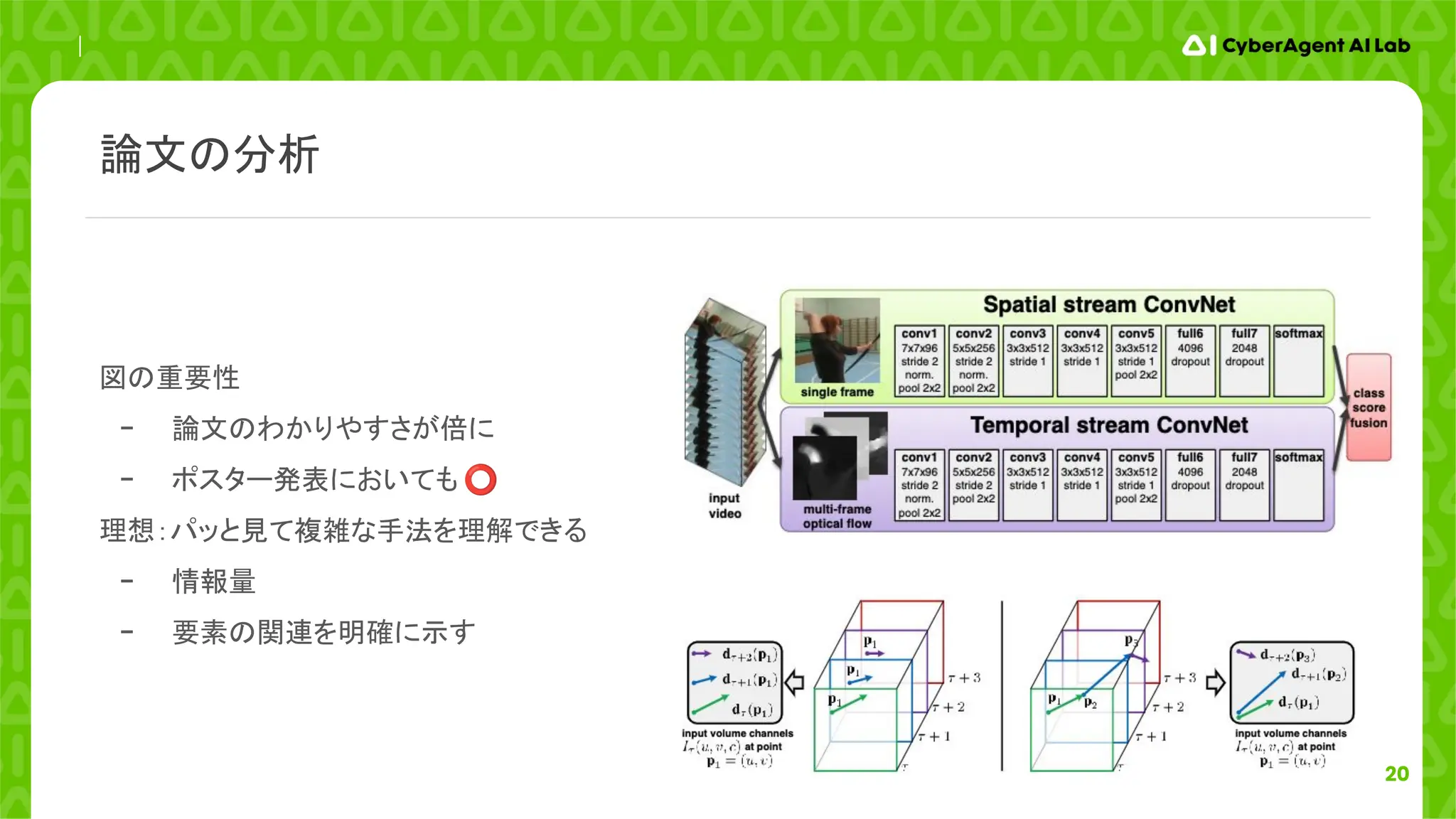
論文の分析
9.
9
This task hasrecently been addressed in [14] by (...) but the results were significantly worse than
hand-crafted shallow representations [20, 26].
対比の言葉(but, however, although, …)を用いて関連研究の「弱点」を簡潔に述べる
(present perfect)。すべての主張には引用が伴う
We investigate a different architecture based on two separate recognition streams (spatial and
temporal), which are then combined by late fusion (...) Both streams are implemented as ConvNets.
Decoupling the spatial and temporal nets also allows us to exploit (...)
提案手法とそのメリットを簡潔に説明
- 「ポジティブ」な言葉を使用(capable of, allows us to, …)
論文の分析
10.
10
The rest ofthe paper is organised as follows. In Sect. 1.1 we (...)
このような段落はかなりスペースを取るのに、読者にとってはそんな魅力がないため、最近は使わ
れなくなってきた
Our experiments on two challenging datasets show that the two recognition streams are
complementary, and our deep architecture significantly outperforms that of [14] and is competitive with
the state of the art shallow representations [20, 21, 26]
提案手法の強みを強調し、論文の結論を一言で述べる。また、上記に紹介された関連研究を(論理
的に!)引用
- 「ポジティブ」な言葉を使用(significantly, competitive, outperforms, …)
論文の分析
11.
11
簡潔で直感的な(わかりやすい)intro は、より好まれ、読者に「もっと読みたい」と思わせる。一般的
な方法として、intro の最後に主な貢献点(約3つ)を示すことが多い。例:
Ourmain contributions are:
- We define a new task/scenario/etc. to…
- To solve it, we propose a method that uses…
- We evaluate our implementation on several datasets, and outperform the state-of-the-art by…
Intro では、論文が提案するコアアイデアの概要/パイプラインを示すシンプルな図を使用。これは
機械学習の論文で一般的であり、注目を引く手法として、図1として論文の1ページ目に置くことが多
い。パイプラインを説明する際には、ストーリーの論理性を保つことが重要。
論文の分析
12.
12
段落の最初の一文を読むことでその内容を把握できるようにすること
- 段落構成は「1つのアイデアにつき1つの段落」を基本とする
1. Recognitionof human actions in videos is… ← 分野の紹介
2. In this work, we aim at extending ConvNets… ← 提案手法の紹介
3. The rest of the paper (...) Our experiments show that… ← Contributions/conclusions のまとめ
留意点:
- 価値があるか: この問題を解決することがなぜ重要なのか?誰が嬉しいのか?
- 挑戦する意義: 技術的なチャレンジや contributions は何か?
- 面白さ: この研究を行うことで何が明らかになるのか?
ただし、contributions を誇張しすぎないで!(安易な誇張はレビュワーに見抜かれる)
論文の分析
14
A large familyof video action recognition methods is based on shallow high-dimensional encoding (...)
従来に効果的であるアプローチを紹介
There has also been a number of attempts to develop a deep architecture for video recognition. The
model is expected to implicitly learn spatio-temporal features in the first layers, which is difficult (...)
提案手法に近いアプローチを紹介し、そのチャレンジを明確に述べる
A network operating on individual video frames performs similarly to the networks which input is a
stack of frames. This might indicate that the learnt spatio-temporal features do not capture the motion
well. The learnt representation turned out to be 20% less accurate than traditional shallow features.
例を挙げて既存手法の limitations を具体的に述べる
論文の分析
15.
15
Our temporal streamConvNet operates on multiple-frame dense optical flow (...). We used a popular
method [2], which formulates the energy based on constancy assumptions for intensity and its gradient,
as well as smoothness of the displacement field.
前述の前提に基づいて、提案手法を簡潔に紹介し、その強みを強調。例えば:
- X手法は従来は効果的だった
- Y手法は有望であるが、理由RによりXを上回ることができない
- 我々はYの改善案としてZ手法を提案し、Rを解決することにより、XとYを両方上回る結果を示
す
論文の分析
17
「提案手法」という論文のコアとなるセクション
呼び名は色々
- Model, Methodology,Architecture, “Method Name”, etc.
Intro などに比べて読むのに気力が必要
- → 最近は information-surfing approach という読み方を取られることが多い
Information-Surfing Approach
- Intro と Conclusion をさっと読んで、必要あればMethods などの細部を読む
“The aim is not simply to make it possible for the reader to understand;
- The aim is make it IMPOSSIBLE for the reader NOT to understand.”
トップダウン方向: 全体→細部
- ゴール、背景、気持ち→ 使用ツール、モデルの構造、パラメータetc.
技術的なチャレンジはどこにあったのかを明確にするのが MUST!
Methodology とは?
18.
18
1. 最初に
a. 提案手法の全体像(i.e., pipeline)
b. Intro で述べた目的・関連研究との差改めて述べる
2. 手法の詳細を説明
a. Pipeline のモジュールごとの存在に 妥当な理由を述べる
3. 必要あれば図表について触れる
4. 関連研究に言及
a. 比較のため
b. 手法の妥当性を示すため
5. 英語の「現在形」が使われる (e.g., “module A extracts/filters/learns/etc.)
6. 手法の問題点を示す → Limitations
Methodology の一般的な書き方
19.
19
セクションの構造
● Optical flowConvNets(貢献1:ネットワーク構造)
○ ConvNet input configurations
○ Relation of the temporal ConvNet architecture to previous representations
● Multi-task learning(貢献2:学習方法)
● Implementation details(提案手法に依存しない詳細・再現性の保証 )
論文の分析
21
We describe aConvNet model, which forms the temporal recognition stream of our architecture.
提案手法とその目的の紹介
Unlike the ConvNet models, the input to our model is formed by stacking optical flow displacement
fields between several consecutive frames.
関連研究との違いを強調
Such input explicitly describes the motion between video frames, which makes the recognition easier,
as the network does not need to estimate motion implicitly.
各コンポーネントの設計上の決定(design decisions)を正当化
We consider several variations of the optical flow-based input, which we describe below.
実装の詳細と ablation study
論文の分析
22.
22
Optical flow stacking.A dense optical flow can be seen as a set of displacement vector fields (...)
Formally, let w and h be the width and height of a video; a ConvNet input volume for an arbitrary
frame τ is then constructed as follows: (数式)
手法の技術的な説明(理論に基づく数式も含め)
In this section, we put our temporal ConvNet architecture in the context of prior art, drawing
connections to the video representations, reviewed in the related work
関連研究との違いを強調し、design decisions を正当化
(レビューでされたのコメントをきっかけに?)
This provides further evidence that our representation generalises hand-crafted features.
Design decisions を正当化/検証
論文の分析
23.
23
Unlike the spatialstream ConvNet, which can be pre-trained on a large image dataset, the
available datasets for training the temporal ConvNet are still rather small (...) One could consider
combining two datasets; however, this is not straightforward (...) A more principled way of combining
several datasets is based on multi-task learning, where additional tasks act as a regulariser (...)
他の使えそうなアプローチに対して、design decisions を正当化
(レビューでされたのコメントをきっかけに?)
In our case, a ConvNet architecture is modified so that it has two softmax classification layers (...)
提案手法の技術的な説明
Architecture (...) Hyperparameters (...) Pre-processing (...) Train/test (...) GPU hardware (...)
実装の詳細
論文の分析
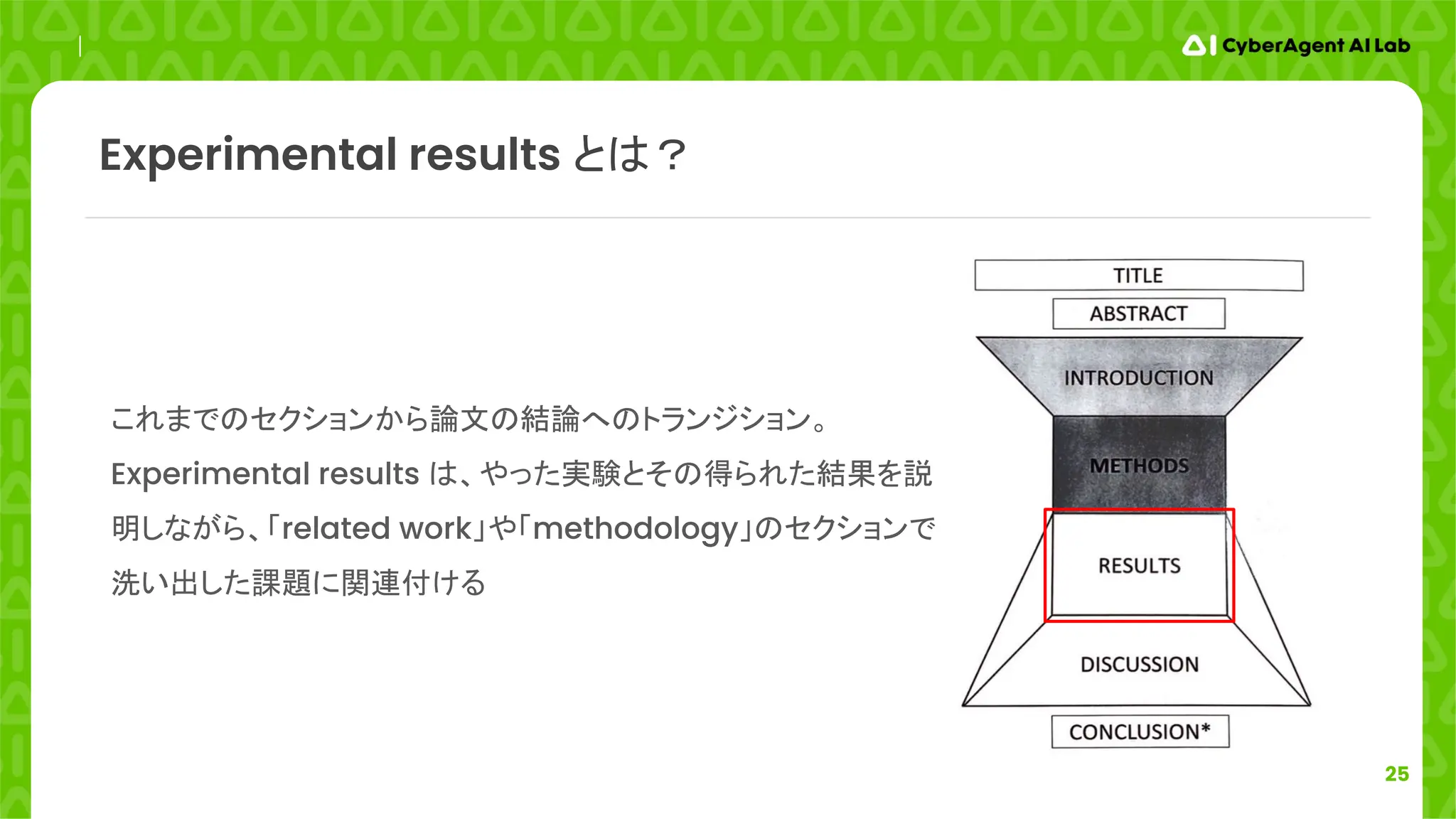
27
論文の分析
セクションの構造
● Evaluation
○ Datasetsand evaluation protocol(再現性のため)
○ Spatial ConvNets(モジュール1のアブレーション)
○ Temporal ConvNets(モジュール2のアブレーション)
○ Multi-task learning(学習方法のアブレーション)
○ Two-stream ConvNets(モジュールの組み合わせのアブレーション)
○ Comparison with the state of the art(提案手法と関連研究の比較)
提案手法の各モジュールを個別で評価し、結果を解析
その解析に基づいて手法全体を評価し、結果を解析
因果関係に一貫性
28.
28
The evaluation isperformed on UCF-101 and HMDB-51 action recognition benchmarks (...) UCF-101
contains 13K videos (...) The datasets provide three splits into training and test data (...)
データセットの詳細と評価手順を紹介
Performance of the spatial stream ConvNet. Three scenarios are considered: (i) (...)
モジュールの ablation の仕方を説明
From the results, it is clear that training the ConvNet solely on the UCF-101 dataset leads to
over-fitting (...). Interestingly, fine-tuning the whole network gives only marginal improvement (...)
定性的な結果から、提案手法に関する結論を導き出す
We assess the effect of different input configurations, and conclude that stacking multiple displacement
fields in the input is highly beneficial, as it provides the network with long-term motion information.
各設定で得られた結果について議論すること(議論されていない実験があってはいけない)
論文の分析
29.
29
Training temporal ConvNetson UCF-101 is challenging due to the small size of the training set. Here we
evaluate different options for increasing effectiveness: (i) fine-tuning a temporal network (...); (ii)...
Ablation や実験の設定の目的を明確にするために、改めて述べる
The results are reported in Table 2. As expected, it is beneficial to utilise all splits combined (...) Multi-task
learning performs the best, as it allows the training procedure to exploit all available data.
得られた結果から仮説を裏付ける結論を導き出す
From Table 3 we conclude that: (i) temporal and spatial recognition streams are complementary, as their fusion
significantly improves on both; (ii) …
Ablation と同様に、full-pipeline の実験から得られた結論を説明
As can be seen from Table 4, both our spatial and temporal nets alone outperform deep architectures. The
combination of the two nets further improves the results (in line with the experiments above)
他の結果と整合性を保ちながら、提案手法の強みを強調する
論文の分析
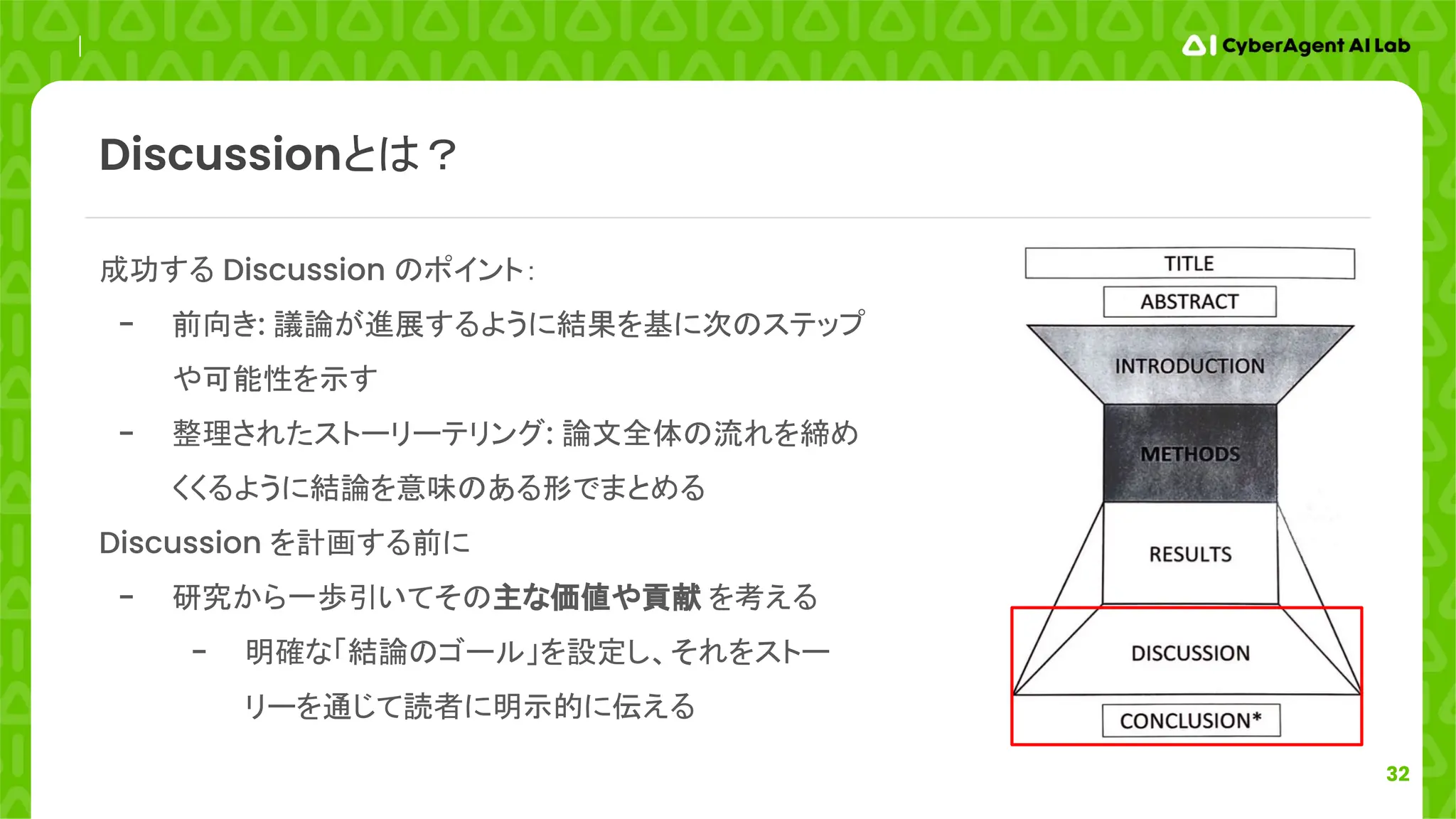
33
Incorporating such assumptionsinto a ConvNet framework might be able to boost the performance of
end-to-end ConvNet-based methods, and is an interesting direction for future research.
提案手法をなどの limitations を述べる。Limitations は論文の範囲外
(out-of-the-scope, future work)かもしれないがカバーしてはNG(怪しく見える)
代わりに問題を軽くするような言葉を使ったり、解決策を提案したりするなど、前向きなスタンスを取
るのが良い
論文の分析
38
Incorporating such assumptionsinto a ConvNet framework might be able to boost the performance of
end-to-end ConvNet-based methods, and is an interesting direction for future research.
論文の全体概要(モチベーションや目標)を簡潔に要約
The challenge is to capture the complementary information on appearance from still frames and motion
between frames. We also aim to generalise the best performing hand-crafted features within a
data-driven learning framework.
論文のチャレンジや工夫などを指摘
論文の分析
39.
39
Our contribution isthree-fold. First, we propose a two-stream ConvNet architecture which incorporates
spatial and temporal networks. Second, we demonstrate that a ConvNet trained on multi-frame dense
optical flow is able to achieve very good performance in spite of limited training data. Finally, we show
that multitask learning, applied to two different action classification datasets, can be used to increase
the amount of training data and improve the performance on both
Contributionsを具体的に述べる
Our architecture is trained and evaluated on the standard video actions benchmarks of UCF-101 and
HMDB-51, where it is competitive with the state of the art. It also exceeds by a large margin previous
attempts to use deep nets for video classification.
提案手法の評価の仕方やその結果を簡潔に述べ、成果を強調
論文の分析
40.
40
研究論文 title の変化
-オンラインの推薦システムなどで読むことが多い
- Title は、Abstract よりも読まれる
- 検索結果の最初に表示されるものだけが読まれる傾向
- ターゲットとする読者層の多様性:高度専門的/学際的
Title の重要性
- 良い title は適切な読者を引きつける
- 逆にいうと、悪い title はターゲットとなる読者層に届かない
研究が完了し、結果が得られてから title を決めるのが大事
Titleとは?






![8
Recognition of human actions in videos is a challenging task which has received a significant amount
of attention in the research community [11, 14, 17, 26].
このような文章は情報量がないため、最近はあまり使われない
Compared to still image classification, the temporal component of videos provides an additional (and
important) clue for recognition
論文のタスクを、より一般的なシナリオ(画像分類)と比較しながら導入し、動画データの特性を述べ
る(一般的 → 具体的)
In this work, we aim at extending deep Convolutional Networks [19] to action recognition in video
問題を明確にした後、研究の目的を指摘
論文の分析](https://image.slidesharecdn.com/2-howtowriteapapertoni-public-250313035656-67d2e4b1/75/How-to-write-a-scientific-paper-8-2048.jpg)
![9
This task has recently been addressed in [14] by (...) but the results were significantly worse than
hand-crafted shallow representations [20, 26].
対比の言葉(but, however, although, …)を用いて関連研究の「弱点」を簡潔に述べる
(present perfect)。すべての主張には引用が伴う
We investigate a different architecture based on two separate recognition streams (spatial and
temporal), which are then combined by late fusion (...) Both streams are implemented as ConvNets.
Decoupling the spatial and temporal nets also allows us to exploit (...)
提案手法とそのメリットを簡潔に説明
- 「ポジティブ」な言葉を使用(capable of, allows us to, …)
論文の分析](https://image.slidesharecdn.com/2-howtowriteapapertoni-public-250313035656-67d2e4b1/75/How-to-write-a-scientific-paper-9-2048.jpg)
![10
The rest of the paper is organised as follows. In Sect. 1.1 we (...)
このような段落はかなりスペースを取るのに、読者にとってはそんな魅力がないため、最近は使わ
れなくなってきた
Our experiments on two challenging datasets show that the two recognition streams are
complementary, and our deep architecture significantly outperforms that of [14] and is competitive with
the state of the art shallow representations [20, 21, 26]
提案手法の強みを強調し、論文の結論を一言で述べる。また、上記に紹介された関連研究を(論理
的に!)引用
- 「ポジティブ」な言葉を使用(significantly, competitive, outperforms, …)
論文の分析](https://image.slidesharecdn.com/2-howtowriteapapertoni-public-250313035656-67d2e4b1/75/How-to-write-a-scientific-paper-10-2048.jpg)




![15
Our temporal stream ConvNet operates on multiple-frame dense optical flow (...). We used a popular
method [2], which formulates the energy based on constancy assumptions for intensity and its gradient,
as well as smoothness of the displacement field.
前述の前提に基づいて、提案手法を簡潔に紹介し、その強みを強調。例えば:
- X手法は従来は効果的だった
- Y手法は有望であるが、理由RによりXを上回ることができない
- 我々はYの改善案としてZ手法を提案し、Rを解決することにより、XとYを両方上回る結果を示
す
論文の分析](https://image.slidesharecdn.com/2-howtowriteapapertoni-public-250313035656-67d2e4b1/75/How-to-write-a-scientific-paper-15-2048.jpg)




































![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]Weight Agnostic Neural Networks](https://cdn.slidesharecdn.com/ss_thumbnails/dl0906-190906002243-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]World Models](https://cdn.slidesharecdn.com/ss_thumbnails/20180427-180427003856-thumbnail.jpg?width=640&height=640&fit=bounds)




































