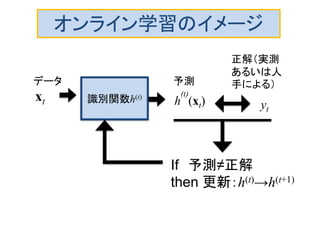
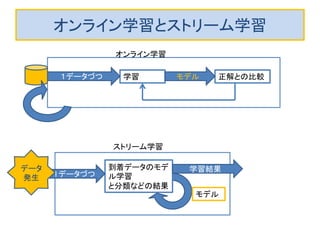
オンライン学習の評価法
仮説hのなす空間をH, tラウンドの予測値をh
(t)
(xt)
累積損失 (最小化したい):
Mistake(失敗回数)のupperbound
以後は識別に失敗しなくなるまでの学習回数=学習
データ数
T
t ttt
t
yh1
)(
,, xxl
T
t tt
h
T
t ttt
t
h
T
t tt
T
t ttt
t
yxhyxh
h
hyxhyxhh
1
*
1
)(
*
TT
*
1
*
1
)(*
T
,,min,,
RegretmaxRegret
:,,,,Regret
*
*
ll
H
Hll
H
H
x
x
6.
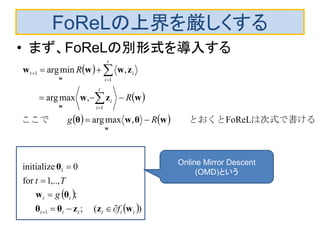
オンライン学習をオンライン凸最適化の観点から定式化
By Shai Shalev-Shwartz
以下では L(w ,(xi , yi )) をfi (w)と略記することに留意。
最も簡単なオンライン学習は、過去の全roundの損失を最小
化するようなwを選ぶ方法:Follow-The-Leader(FTL)
T
t
tttt
T
t
tttT
t
i
i
Sw
t
ffff
S
FTL
Sft
1
1
1
21
1
1
Regret
,10Lemma
minarg
(FTL)LeaderTheFollow
wwuwu
u
ww
www
トルで生成された重みベクを
の取り得る範囲で凸は
7.
より。 □の定義最後の等式は
でも成り立つで成立し、この式は
を加えると両辺に
仮定する。つまりで不等式が成立すると
を選べる。より、式の成立するの定義の場合は
を帰納法で導く。 そこのこの不等式
き移項するとの不等式の両辺から引を
T
t
t
S
TT
T
t
t
S
T
t
Tt
T
t
tt
T
T
t
tTT
T
t
tt
TT
T
t
t
T
t
tt
t
T
t
t
T
t
tt
t tt
f
fff
S
fff
fffS
Tt
fT
ff
f
1
11
11
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
121
11
1
minarg
min
1:stepinduction
minarg1:casebase
10Lemma
Proof
www
uww
wuu
uww
wuwu
uwww
uw
w
w
u
w
数学的ツールの準備
• Bregman Divergence:DR
)1(
2
,
22
2
,
2
21
212
2
2
2
121
*
2
*
*
DR
D
RR
RRRD
R
R
zz
zzzzzzz
zz
z
z
uwuuwuw
だと
uwRD
17.
T
t
t
i
i
t
i
iRtt
T
t
t
i
i
t
i
iRtt
T
t
t
T
t
t
T
t
t
i
i
t
i
iRtt
T
t
t
i
i
t
i
i
T
t
t
t
i
itt
T
t
t
T
t
t
T
t
t
T
t
t
i
i
t
i
iR
T
t
tt
DRR
DRRRR
RRRR
DR
RRRR
Rg
RRR
DRR
Rg
1
1
11
1
1
1
1111
1
1
1
11
1
1
111
1
1
111
1
1
11
1
1
||,
||,0,
)4(min,0max0
)3(||,0
0
DivergenceBregman
)2(
)1(,,
Young-Fenchel
Proof
||,
DescentMirrorOnline:OML1
zzzwwu
zzzwuzuzu
wwww
zzzw
zzz
zθw
zzuuzuu
zzwuzuw
ww これらを合わせるとなお、
の定義より
不等式から
であるならで 補題
18.
20,
1
1OMD1Proof
10
22
,
2
,
2
DescentMirrorOnline
1
1
22
1
2
2
1
2
*
2
OMDTBL
B
TL
B
T
L
DR
OMD
RR
T
t
tt
T
t
t
T
t
t
T
t
tt
zuw
uz
z
u
zuw
θ
θ
w
w
とするとただし かつ
より明らか ■ と 補題
とする。であるつまり
において
定理 OMD2
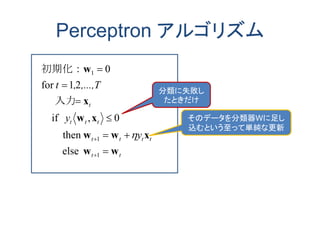
Perceptronアルゴリズムの分析
ttyt
t
tttt
T
t
t
T
t
t
T
t
ttT
y
f
yf
ff
ttt
x1z
xw
zuuwu
xw 0,
1
2
2
2
2
11
gradient-sub
],1[
(60)
22
1
Regret
は
界は甘くなる。)より必ず大きいので上(もとの
で近似する。ためここで解析の容易さの
Wt,Xtをスケール変換し
て、最も0に近い正例で
𝑤𝑡, 𝑥 𝑡 =1となったと見
なしたと考えてもよい
FoReLの別形式として導入したOnline Mirror
Descentとみれば、(OMD20)の上界が使える
24.
Perceptronアルゴリズムの分析
ータと境界面の距離は境界面に最も近いデ線形分離できる場合
データが線形分離可能
のときなので=の右辺の最小値は
とおくとの形より明らかに
回数、の集合をを起こした判定の失敗
u
uu
uxuu
uuu
u
xw
x
1
:0then1,if
(70)
22
1
)60(
max
mistakemistake:
2
2
22
1
22
1
1
R
RR
fy
RRf
R
Rff
T
t
ttt
T
t
t
t
t
T
t
ttt
t
MMM
MMM
M
M
MM
25.
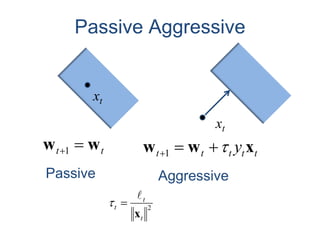
Passive Aggressive Algorithm
K.Crammer et.al. Online Passive-Aggressive Algorithms
Journal of Machine Learning Research 7 (2006) 551–585
識別(あるいは分類)の問題設定
round t でn次元データ が到着
の正負は のように与えられる
重みベクトル:
正しい(誤った)判定:
wtはデータが到着するたびに更新されている
n
t Rx
tx 負 正 :1,:1 ty
正負を表すので:, xwsignRw n
00, 、 ttt xwy
0..*
tlttsuTheorem 2では次の制約が厳しい。
この制約は、uで完全な識別ができること。
この制約を外す定理を考える
2
1
2*
1
2
*2
2
,;1
1Lemma
3Theorem
T
t t
T
t
t
n
tttt
u
Ruyxuxt
に対してであるような このとき
と同じ設定。
Proofは次ページ
40.
■
を使うと
ほうの解。とした2次式の大きなをは上式での最大値
とおくと ここで
だからより
2
1
2*
1
2
1
2*
1
2
2
1
2*
1
2*
2
1
2*2
1
22
1
2*
1
2
1
2
1
2*
1
2
1
*
2
1
*
1
2
1
2*2
2
2max
2maxmax
max
max
02
2
Schwartz-Cauchy
222
1
u
uLTbaba
uLT
LTLT
ulLTLT
LTlulll
llll
ulllulxτlτ
lx
T
t
t
T
t
t
T
t
t
T
t
t
T
t
t
T
t
t
T
t
t
T
t
t
T
t
t
T
t
t
T
t
t
T
t
t
T
t
t
T
t
tt
T
t
tt
T
t
t
T
t
ttttt
ttt
Proof
Pegasos:
Primal Estimated sub-GrAdientSOlverfor SVM
L2正則化+L1損失のSVM
Pegasosの更新は次式による
更新の後、wを半径 の球にproject
以上を収束するまで繰り返す。データ集合Aごとな
ので、onlineというよりはmini-batch
AkAy
k
Bf
Bi
T
i
は学習に使うデータ、1,0max
1
2
;min
2
2
xwww
w
は繰り返し回数の次元、,はベクトル
の要素の劣微分は
tl
t
yAiiAy
A
Afwhere
AffAfAf
i
i
T
i
Ai
iit
ttttt
xw
xwxww
wwwww
,
1
,01,|
1
;
;;;2/1
/1,1min
www 2
/1,1min
48.
Pegasos:Primal Estimated sub-GrAdient
SOlverfor SVM のアルゴリズム
1
2/1
2/1
1
2/1
1
:Output
1
,1min
1
1
0,1|
T,1,2,......For t
0:
T
t
t
t
Ai
ii
t
t
t
t
t
t
ititt
tt
t
y
A
t
yAiA
kAAD
w
w
w
w
xww
xw
w
を選ぶ。から全データ
初期化
49.
f(w)の評価
という。が凸のとき、は、また、関数
とする。まず
convexstrongly
2
minarg
2
*
ww
ww
w
ff
f
T
TG
f
T
f
T
BG
ttB
f
Bff
T
t
t
T
t
tt
tt
ttttt
B
t
ttT
T
2
ln111
1minarg1,
,...,
convexstrongly-,...,Lemma1.
2
11
11
11
1
uw
uw
wwwww
ww
w
つに対して次式が成り立のとき、
ただし
の劣微分の要素はルの列とする:を以下のようなベクト
を閉凸集合とする。とし、を
50.
T
G
t
GT
t
G
tt
t
G
tt
Gff
Tt
Gff
G
tG
B
projectionB
ff
f
T
t
t
T
t
T
t
tt
T
t
T
t
t
tt
t
T
t
t
T
t
t
t
tt
T
t
ttt
t
t
t
tt
ttt
t
t
tt
tt
tt
ttttttttt
tt
tttttt
tttttt
tt
ln1
2
1
22
1
2
1
1
222
401
40
222
,130
30
222
20)10(
20
22
,
)15(1
)15(2
)10(
2
convex-strongly:Proof
2
1
2
2
1
1
2
1
2
1
2
1
2
1
2
2
1
2
1
2
1
2
2
1
2
1
22
2
1
2
2
2
1
2
22222
1
2
2
1
2
1
2
uwuwuw
uw
uwuw
uw
uwuw
uw
uw
uwuw
uw
uwuw
uw
uwuwuwuwuw
uwuwu
wwww
uwuwuw
を代入すると
まで総和をとるとを
を組み合わせるとと
によりなのでかつ
である。よって なので
でありへののは とおき、
内積
は劣微分の要素なのでで、は
51.
Lemma1を拡張するとさらに強力な次の定理が得られる。
詳細は:Mathematical Programming 127(1),2011, pp.3-30
Pegasos:primal estimated sub-gradient solver for SVM. Shai
Shalev-Schwarts, et.al.
。から選ばれた部分集合は全データ
に対して
とするとしないときは
したときは かつ
入力データ
DA
T
Tc
Af
T
Af
T
T
Rcprojection
Rcprojection
fR
t
T
t
t
T
t
tt
f
2
ln1
;
1
;
1
3
4
minarg,:)(:1Theorem
1
*
1
2
2
*
ww
wwxx
w
R
y
At
y
A
y
A
y
A
y
A
y
A
y
A
yAiA
y
Att
y
A
Ry
A
AfR
t
t
j Ai
ii
j
t
Ai
ii
Ai
ii
Ai
ii
Ai
ii
Ai
ii
Ai
ii
i
t
itt
Ai
ii
t
t
Ai
ii
t
t
ttt
Ai
ii
t
ttt
t
j
tt
1
1
321
4
21
3
1
21
1
11
3
111
2
1
3
2
2
11
2
11
0
01|where
11
11then
stepprojectionif
1
;1then
stepprojectionif
2
dcont':Proof
321
211
w
xw
xxxw
xxwxww
xw
xwxww
xwwxw
ここで
が実行されなかった
かつ
が実行された
の上界を求める。次に
ここの導出は初等的が
だちょっとした計算
54.
とすると、双対問題の解を主問題の解を
題を導く。とおき、以下の双対問
の主問題は以下の形式ここで対象にしている
を示す。した場合は、
と言える。
により しない場合は、
を示す。最後に
***
2
11
1
2
*
*
1
*
,
)50(0:m1,is.t.
2
1
min
1
1,0:m1,is.t.
2
1
min
1projection
minargprojection
3
dcont':Proof
w
x
xww
w
w
wwww
w
w
Cy
mC
yC
SVM
B
B
i
m
i
iii
m
i
i
iiii
m
i
i
tttt
B
t
ここで双対問題を思い
つくところがいかにも
SVM的
55.
られる。 □ に適用すれば定理が得を以上の結果
が成り立つのでの問題では強双対定理
る。は次のように書き直せであり
とすると、双対問題の解を主問題の解を
Lemma1321
1
2
11
2
1
2
1
2
1
11max
2
1
2
1
2
1
50
,
dcont':Proof
*
2*2*
1
*
1
*2*2*
1
1
***
2*
1
*
1
*2*
2*
1
*
1
**
***
w
wwww
ww
wxw
w
C
CmmC
C
SVM
y
m
i
ii
m
i
iii
強双対定理の実に
賢い使い方だ
56.
Coordinate Descent
C.-J. Hsieh,et.al. ICML2008
Target: L1損失- L2正則化のSVM 双対化し
て解く。下に定義
,where
,...,10subject to
2
1
min
jijiij
i
TTD
yyQ
liC
Qf
xx
αeααα
α
57.
Coordinate Descent
Coordinate Descentは順番に1変数づつ選
び、他の変数は固定して最適化。
10,0,maxmin
0,...0,1,0,..0where0subject to
2
1
min
1
2
CDC
Q
f
d
eCd
ffdfdQfdef
ii
D
i
ii
i
T
i
ii
DD
iii
D
i
D
d
α
ααα
の更新式は下式を計算することによる
の双対は
58.
Coordinate Descent つづき
(CD10)のQiiはαiの最適化の中で1回計算すれ
ばよいが
(CD10)(CD10)
CD30
(CD20)1,1
,..,1,1,1
1
1
の更新後の更新前、
+
でうれしい。以下の計算のためのとなり計算コストは
を保持しておけば
ででうれしくない。そこの計算コストが
は
ii
iiii
iii
D
i
l
t
ttt
tit
l
t
titii
D
i
y
nO
yQf
y
nlO
ltyyQf
xuu
xuαα
xu
xxxxαα
59.
L1損失-L2正則化のSVMの
Coordinate Descent アルゴリズム
iiii
ii
ii
ii
ii
ii
l
i
iii
y
C
Q
G
yG
li
liQ
y
xuu
xu
α
xuα
,0,maxmin
1,(CD20)
,..1For
optimalnotiswhile
,...,1
1
の計算により
の計算
の初期化、および
Online Mirror Descent:OMD
11
1
:1
:111
1:1
2.
1.
FoReL,maxarg
,maxarg
,minarg,minarg
FoReL
,FoReL
tt
ttt
t
t
t
i tt
t
i it
tt
g
Rg
R
RR
RS
RRf
θw
zθθ
wθwθ
wzw
zwwzwww
zz
ww
wwzww
w
w
ww
はとおくと
はと略記すると
とするだと なお、
は正則化関数とする で
79.
2*2
1
2
*
1
1
1
2
1
2
1
(OMD100)minRegret
where
),maxarg(
,...2,1for
0
(OMD)DescentMirrorOnline
θww
zvuuwu
wzzθθ
wθwθw
θ
v
w
RR
RRff
f
Rg
t
Sg:R
T
t
t
S
T
t
tttT
tttttt
tt
d
ここで以下が言える
80.
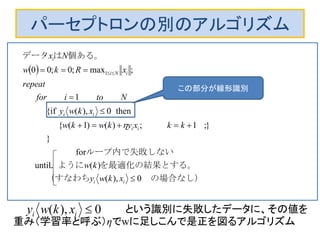
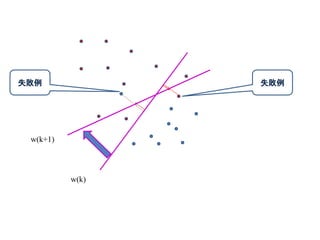
パーセプトロンの別のアルゴリズム
),(
0)(
for
until
}
};1;1;)()1({
then0)({if
1
;max;0;00;00
2
1
。を最適化の結果とするように
の場合なし)(すなわち
ループ内で失敗しない
個ある。はデータ
kbkw
kbxkwy
kkRykbkbxykwkw
kbxkwy
Ntoifor
repeat
xRkbw
Nx
i
T
i
iii
i
T
i
iNi
i
という識別に失敗したデータに、その値を
重み(学習率と呼ぶ)ηでwに足しこんで是正を図るアルゴリズム
0)( kbxkwy i
T
i
この部分が線形識別
81.
は改善していく。い方向にしたがって、失敗しな
よって、
項は必ず正第
みる更新後の判定式を見て
w
kbxkwykbxkwy
xxykbxkwy
Rxykbxkwy
Ryxyykbxkwy
kbxkwy
i
T
ii
T
i
iiii
T
i
iii
T
i
iiiii
T
i
i
T
i
)(1)1(
2
max)(
)(
)(
1)1(
222
222
2
証明
Ry
R
b
R
b
Rybb
xywRxy
R
b
w
R
b
ww
yx
bxwyxwy
wt
R
b
ww
RxxR
i
tt
itt
iit
TT
ii
T
tT
t
T
tT
tt
titiiti
t
T
iT
ii
TT
ii
12
1
1
1
1
111
1
)2(ˆˆ,,,ˆ
0ˆˆ
ˆ
,ˆ
,ˆ1
、なぜなら
このとき
は内積 る。 のとき起こ
更新は、
重みを回目の失敗 に先立つ
とする。
とする。次元加え、となる入力ベクトルに値
85.
証明 つづき
■
より
項は負は負例なので第
より
を繰り返し用いてとすれば
より
2
2
2
2
2
222
222
1
2222
1
222
1
22
1
2
1
2
0
11
1
1
1
2
1||ˆ||2||ˆ||2
ˆˆ||ˆ||||ˆ||2||ˆ||54
52||ˆ||2||ˆ||
2||ˆ||||||||ˆ||||ˆ||||ˆ||
2ˆ
||ˆ||ˆˆ2||ˆ||||ˆ||2
4ˆˆ30ˆ
3ˆˆˆˆˆˆˆˆ)1(
)2(ˆˆ,,,ˆ
R
w
R
w
R
t
twwwwRtw
RtwRtw
RwRxwxw
x
xxwyww
twww
wwwxywwww
xywRxy
R
b
w
R
b
ww
optopt
optttoptopt
tt
titit
i
iititt
optt
opttoptiiopttoptt
iit
TT
ii
T
tT
t
T
tT
tt



















![Perceptronアルゴリズムの分析
ttyt
t
tttt
T
t
t
T
t
t
T
t
ttT
y
f
yf
ff
ttt
x1z
xw
zuuwu
xw 0,
1
2
2
2
2
11
gradient-sub
],1[
(60)
22
1
Regret
は
界は甘くなる。)より必ず大きいので上(もとの
で近似する。ためここで解析の容易さの
Wt,Xtをスケール変換し
て、最も0に近い正例で
𝑤𝑡, 𝑥 𝑡 =1となったと見
なしたと考えてもよい
FoReLの別形式として導入したOnline Mirror
Descentとみれば、(OMD20)の上界が使える](https://image.slidesharecdn.com/online-l1-140313094911-phpapp02/85/7-23-320.jpg)












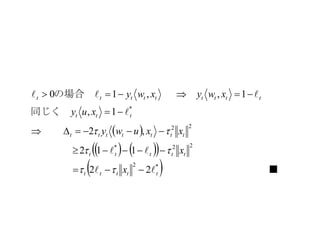






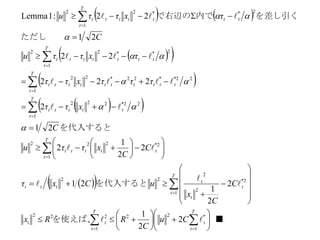



































































![[読会]Long tail learning via logit adjustment](https://cdn.slidesharecdn.com/ss_thumbnails/long-taillearningvialogitadjustment-211229095016-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSO] Machine Learning Seminar Vol.2 Chapter 3](https://cdn.slidesharecdn.com/ss_thumbnails/chapter3slides-200226170409-thumbnail.jpg?width=640&height=640&fit=bounds)




























