Download as PDF, PPTX






























![Prof. Pier Luca Lanzi
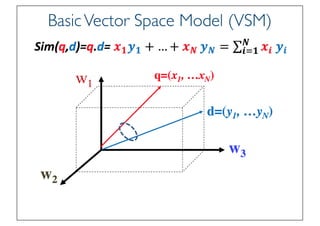
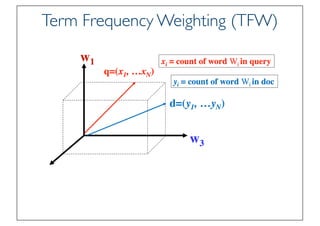
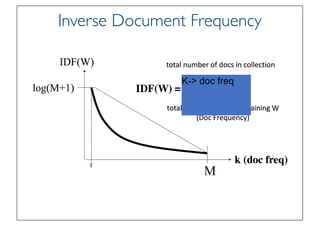
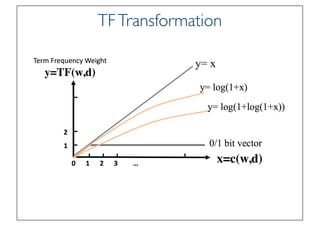
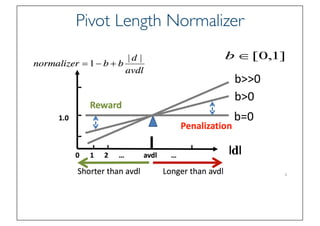
State of the Art VSM Ranking
Function
• Pivoted Length Normalization VSM [Singhal et al 96]
• BM25/Okapi [Robertson & Walker 94]
47](https://image.slidesharecdn.com/dmtm2017-17-textmining-170902110930/85/DMTM-Lecture-17-Text-mining-47-320.jpg)

















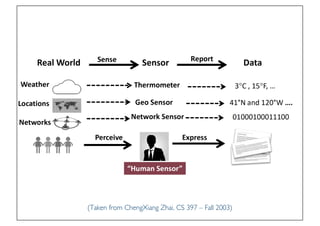
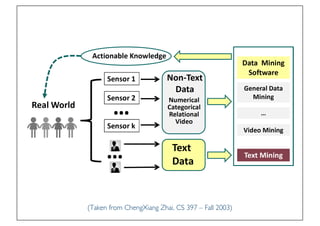
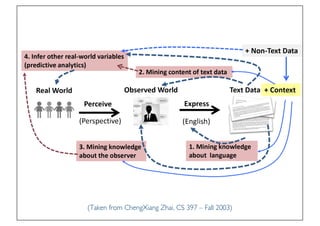
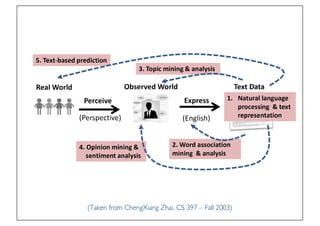
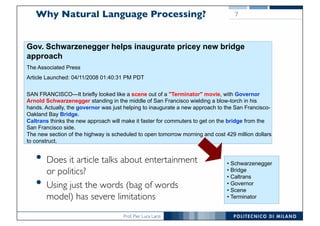
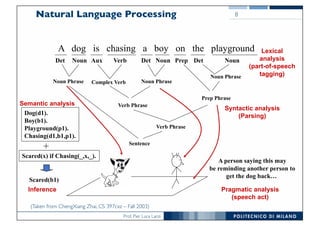
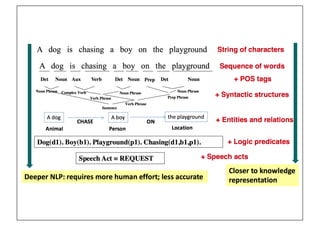
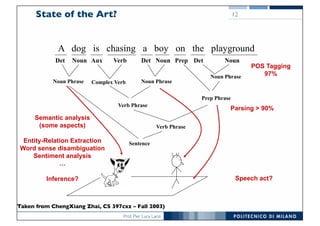
The document discusses various topics related to natural language processing (NLP) and text mining, including challenges like ambiguity and the complexities of semantic analysis. It also covers information retrieval systems, different text access modes, document ranking methods, and techniques for text classification and clustering. Key approaches mentioned include the vector space model, naive Bayes classifiers, and dimensionality reduction techniques like latent semantic indexing.























![[KDD 2018 tutorial] End to-end goal-oriented question answering systems](https://cdn.slidesharecdn.com/ss_thumbnails/kdd2018tutorialend-to-endgoal-orientedquestionansweringsystems-180821081440-thumbnail.jpg?width=640&height=640&fit=bounds)































































