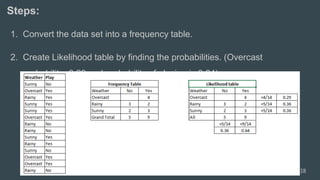
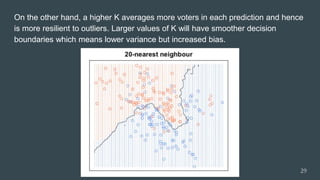
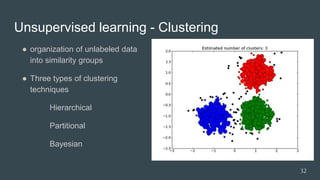
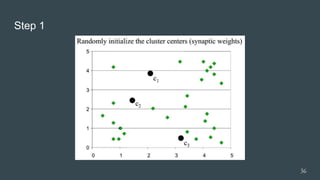
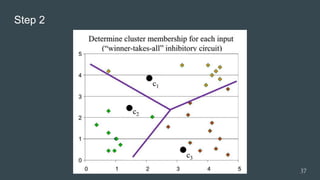
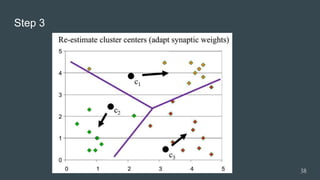
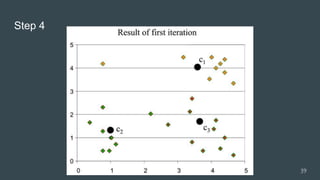
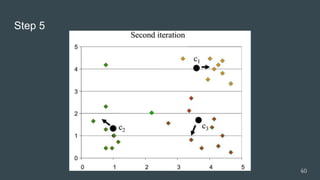
The document provides an overview of machine learning, focusing on key concepts and algorithms such as supervised learning, decision trees, naive Bayes, and k-nearest neighbors. It explains the differences between machine learning and conditional programming, and describes how various algorithms work through examples and Python code. It also covers clustering techniques and the k-means algorithm for organizing unlabeled data.





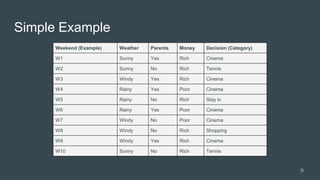
![How prediction works
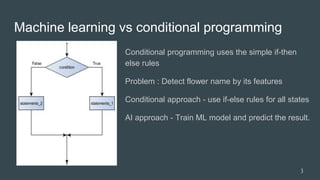
Today is windy. I have money and parents not
at home. Predict what I will do??
Weather = “Windy” 1
Parent = “No” 0
Money = “Rich” 1
classified=[0, 1, 0, 0] I may start shopping!
12](https://image.slidesharecdn.com/machinelearningalgorithms-170807034401/85/Machine-learning-algorithms-12-320.jpg)





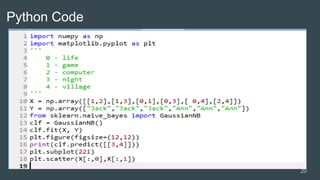
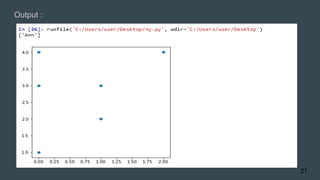







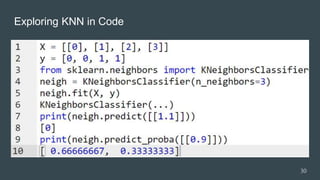




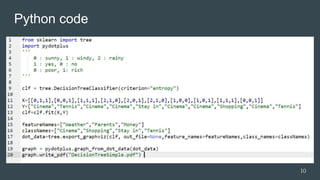
![Python Code
Output Labels [0 0 1 1]
Predicted Label [0]
41](https://image.slidesharecdn.com/machinelearningalgorithms-170807034401/85/Machine-learning-algorithms-41-320.jpg)
![Output Labels [1 1 0 0]
Predicted Label [1]
42](https://image.slidesharecdn.com/machinelearningalgorithms-170807034401/85/Machine-learning-algorithms-42-320.jpg)



































































