Download to read offline







.filter(a => broadcastListEventAll.value.map(r => a._2.matches(r)).foldLeft(false)(_ || _))
.map(a => (a._1, dateBucket, a._2))
.repartitionByCassandraReplica("instametrics", "events_raw_5m", 100)
.joinWithCassandraTable("instametrics", "events_raw_5m").cache()
• Write limiting
• cassandra.output.throughput_mb_per_sec not necessary as writes << reads
8](https://image.slidesharecdn.com/instaclustrwebinar50000transactionspersecondfeb17-170306061739/85/Instaclustr-Webinar-50-000-Transactions-Per-Second-with-Apache-Spark-on-Apache-Cassandra-8-320.jpg)


.filter(a => broadcastListEventAll.value.map(r =>
a._2.matches(r)).foldLeft(false)(_ || _))
.map(a => (a._1, dateBucket, a._2))
.repartitionByCassandraReplica("instametrics", "events_raw_5m",
100)
.joinWithCassandraTable("instametrics", "events_raw_5m",
SomeColumns("time", "state", FunctionCallRef("avg",
Seq(Right("metric")), Some("avg")), FunctionCallRef("max",
Seq(Right("metric")), Some("max")), FunctionCallRef("min",
Seq(Right("metric")), Some("min")))).cache()
• 50% reduction in roll-up job runtime (from 5-6 mins to 2.5-3mins) with reduced CPU usage
10](https://image.slidesharecdn.com/instaclustrwebinar50000transactionspersecondfeb17-170306061739/85/Instaclustr-Webinar-50-000-Transactions-Per-Second-with-Apache-Spark-on-Apache-Cassandra-10-320.jpg)


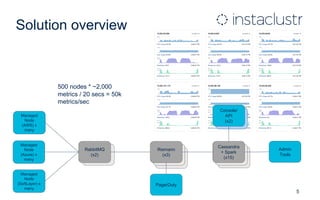
This document describes Instaclustr's implementation of using Apache Spark on Apache Cassandra to monitor over 600 servers running Cassandra and collect metrics over time for tuning, alerting, and automated response systems. Key aspects of the implementation include writing data in 5 minute buckets to Cassandra, using Spark to efficiently roll up the raw data into aggregated metrics on those time intervals, and presenting the data. Optimizations that improved performance included upgrading Cassandra version and leveraging its built-in aggregates in Spark, reducing roll-up job times by 50%.





























































































