Download as PDF, PPTX














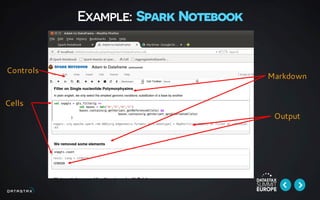

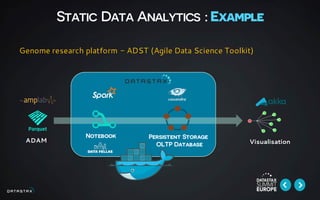









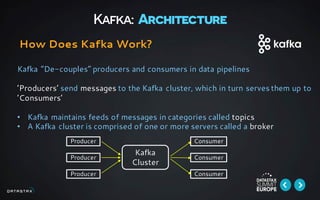
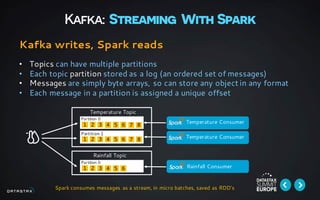
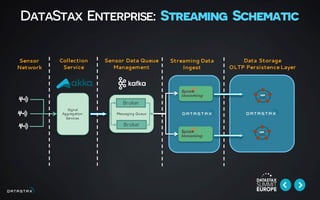
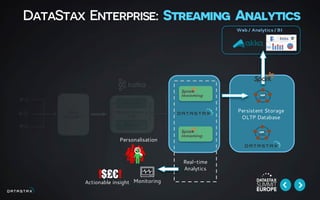
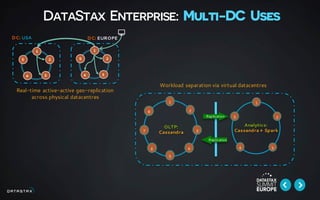
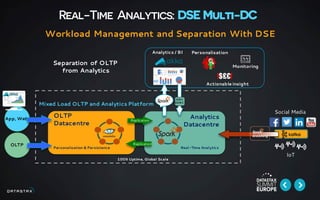




This document discusses building data pipelines for both static and streaming data using Apache Spark and DataStax Enterprise (DSE). For static data, it recommends using optimized data storage formats, distributed and scalable technologies like Spark, interactive analysis tools like notebooks, and DSE for persistent storage. For streaming data, it recommends using scalable distributed technologies, Kafka to decouple producers and consumers, and DSE for real-time analytics and persistent storage across datacenters.











































































































