Download as PDF, PPTX














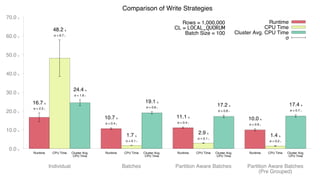

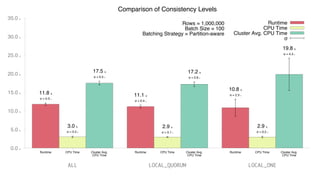



- Micro-batching involves grouping statements into small batches to improve throughput and reduce network overhead when writing to Cassandra. - A benchmark was conducted to compare individual statements, regular batches, and partition-aware batches when inserting 1 million rows into Cassandra. - The results showed that partition-aware batches had shorter runtime, lower client and cluster CPU usage, and was more performant overall compared to individual statements and regular batches. However, it may have higher latency which is better suited for bulk data processing rather than real-time workloads.

























































































