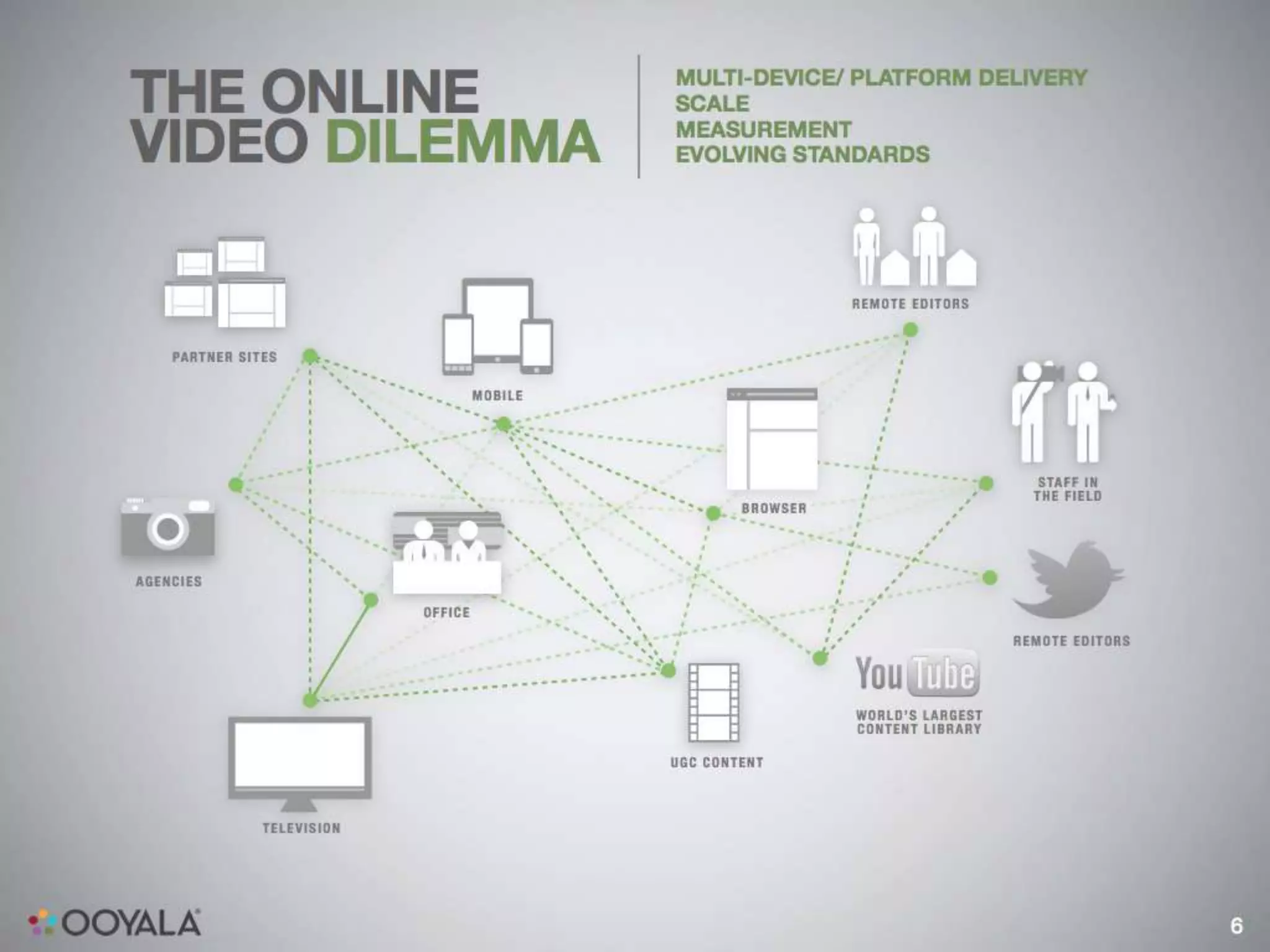
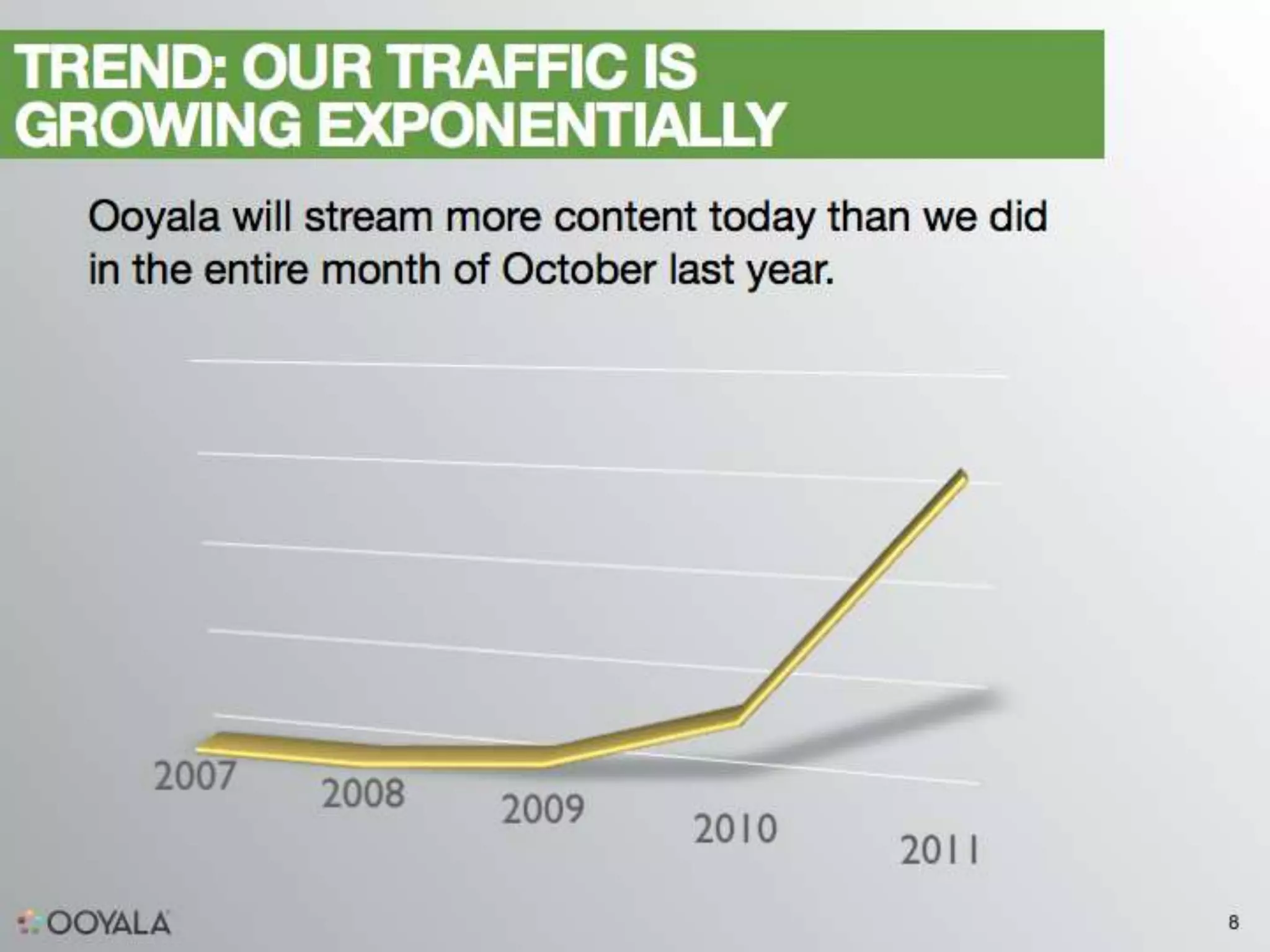
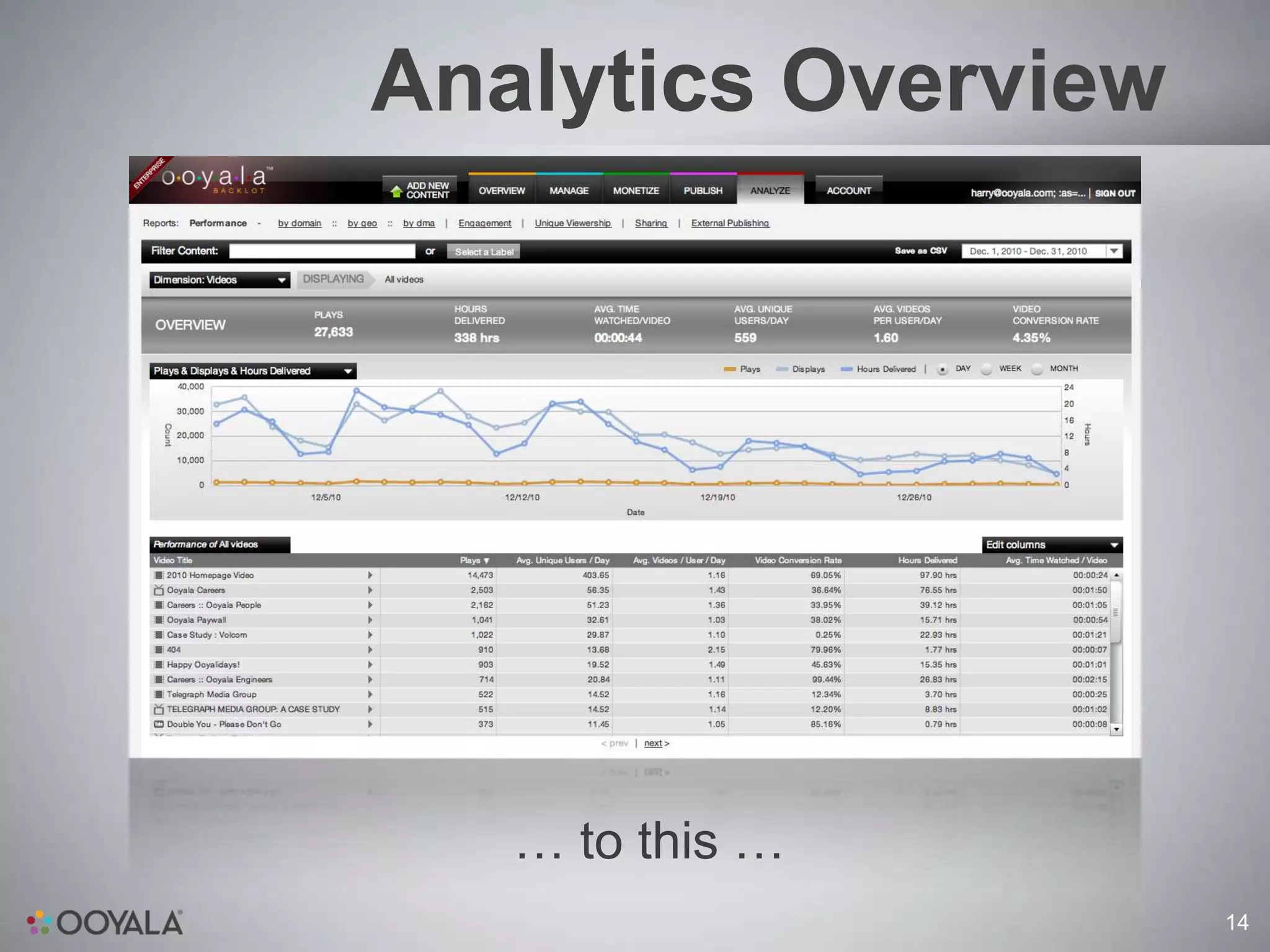
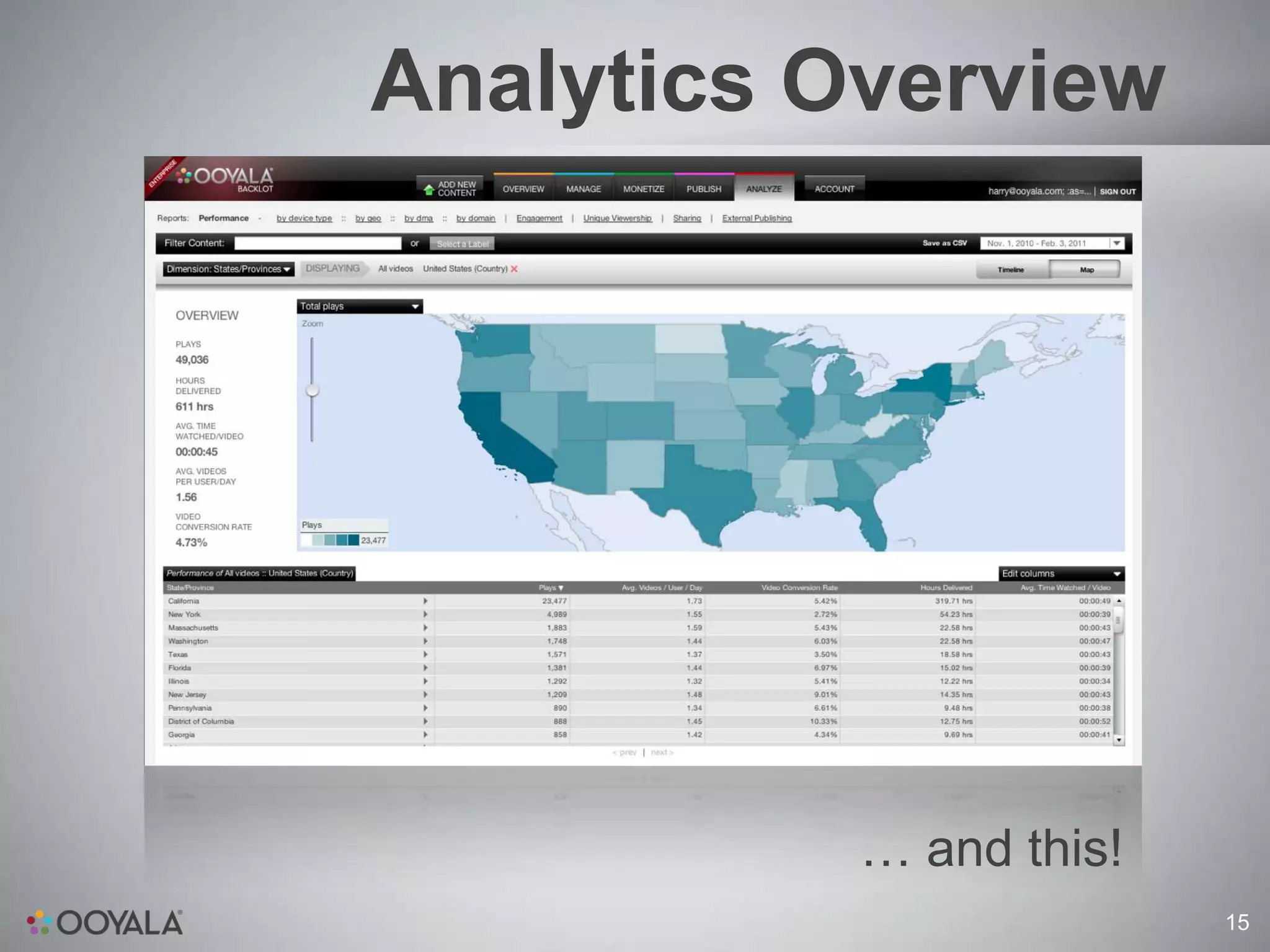
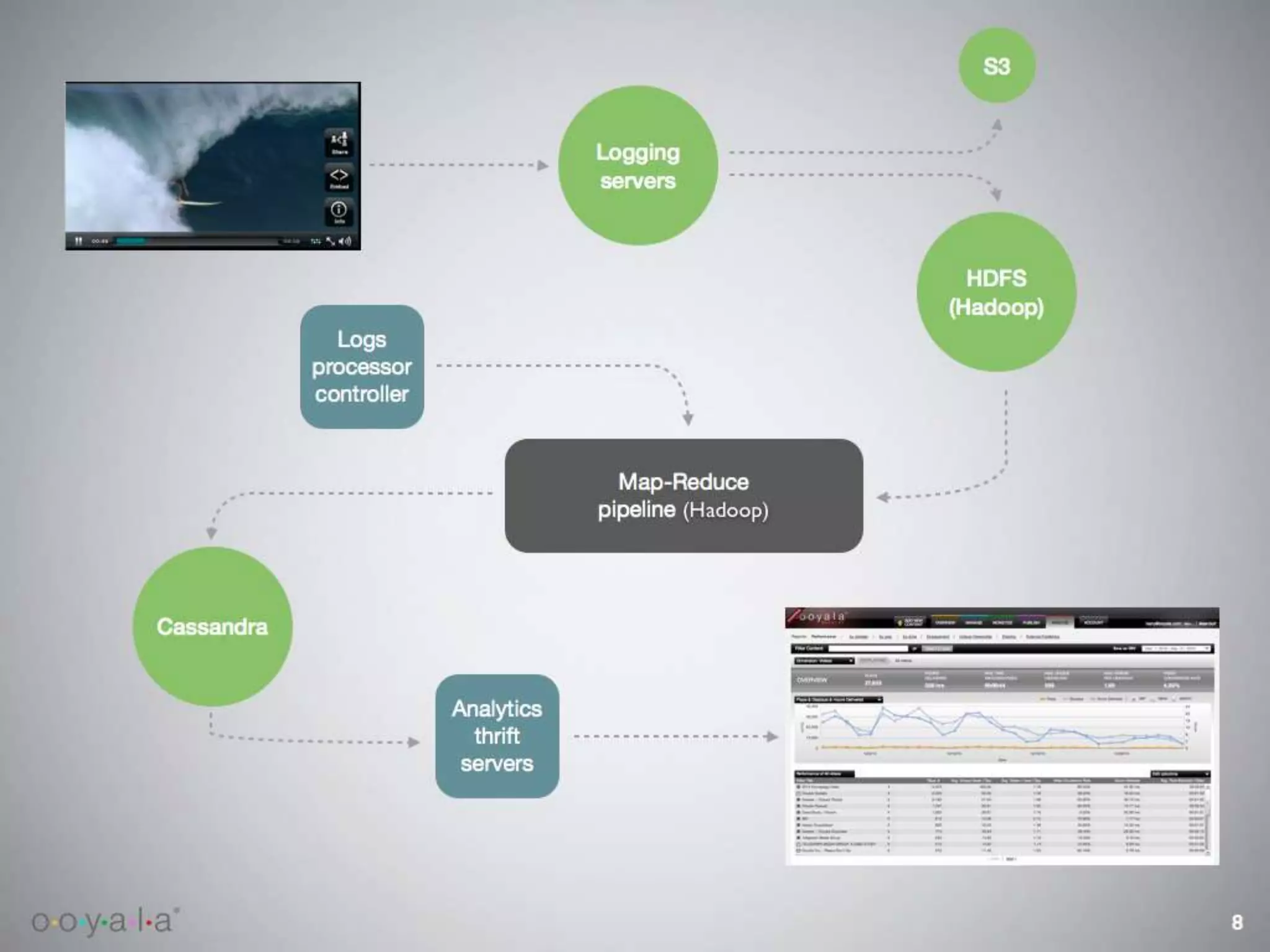
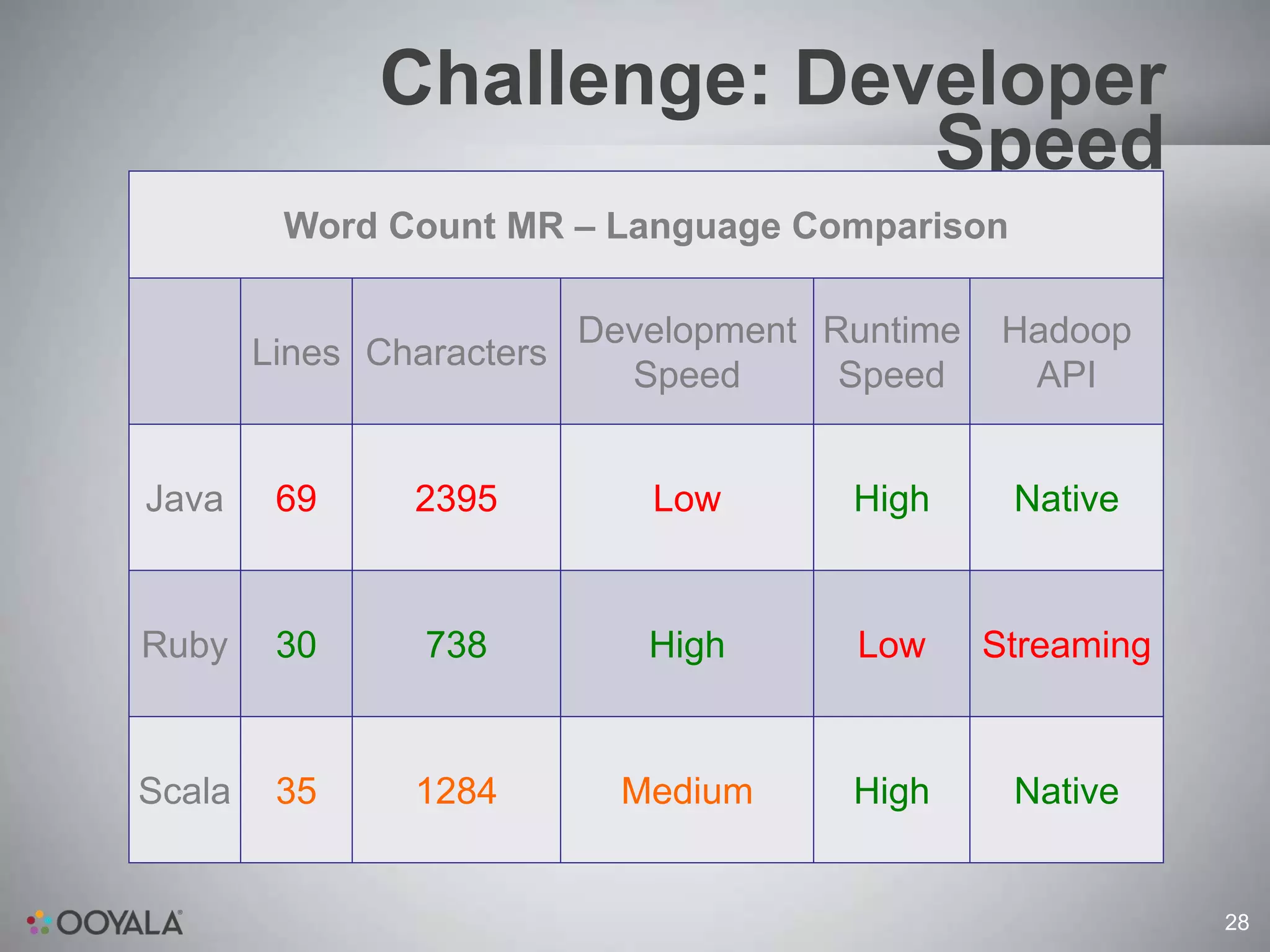
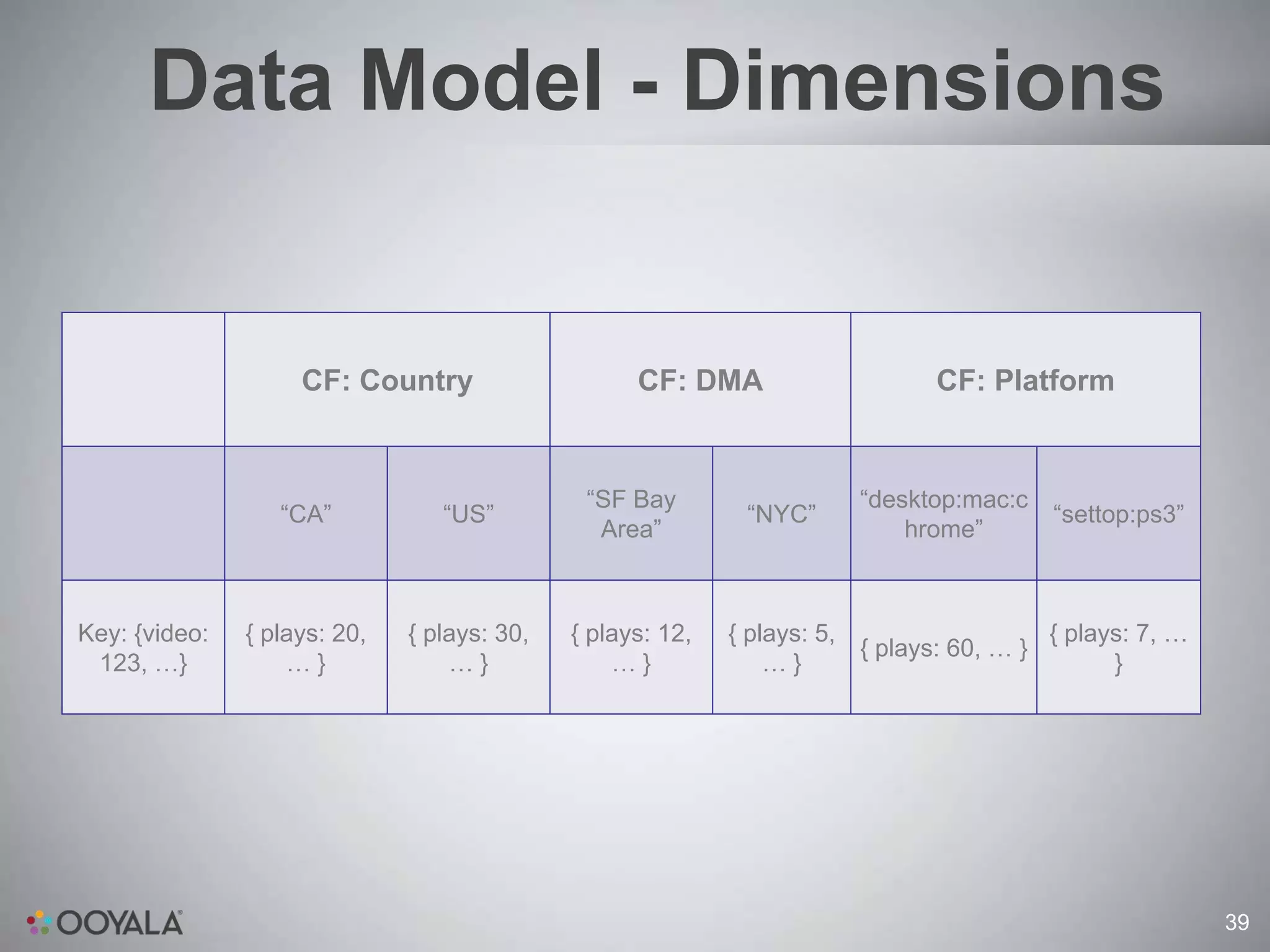
This document discusses scaling video analytics using Apache Cassandra. It provides an overview of Ooyala's video analytics platform and the challenges of scaling to support billions of log pings and terabytes of data daily. Cassandra is used to store over 10 terabytes of historical analytics data covering 4 years of growth. The key challenges addressed are scaling to handle enormous data volumes, providing fast processing and query speeds, supporting deep queries over many dimensions of data, ensuring accuracy, and allowing for rapid developer iteration. The document explains how Cassandra's data model and capabilities help meet these challenges through features like linear scalability, tunable consistency, and a rich data model.


































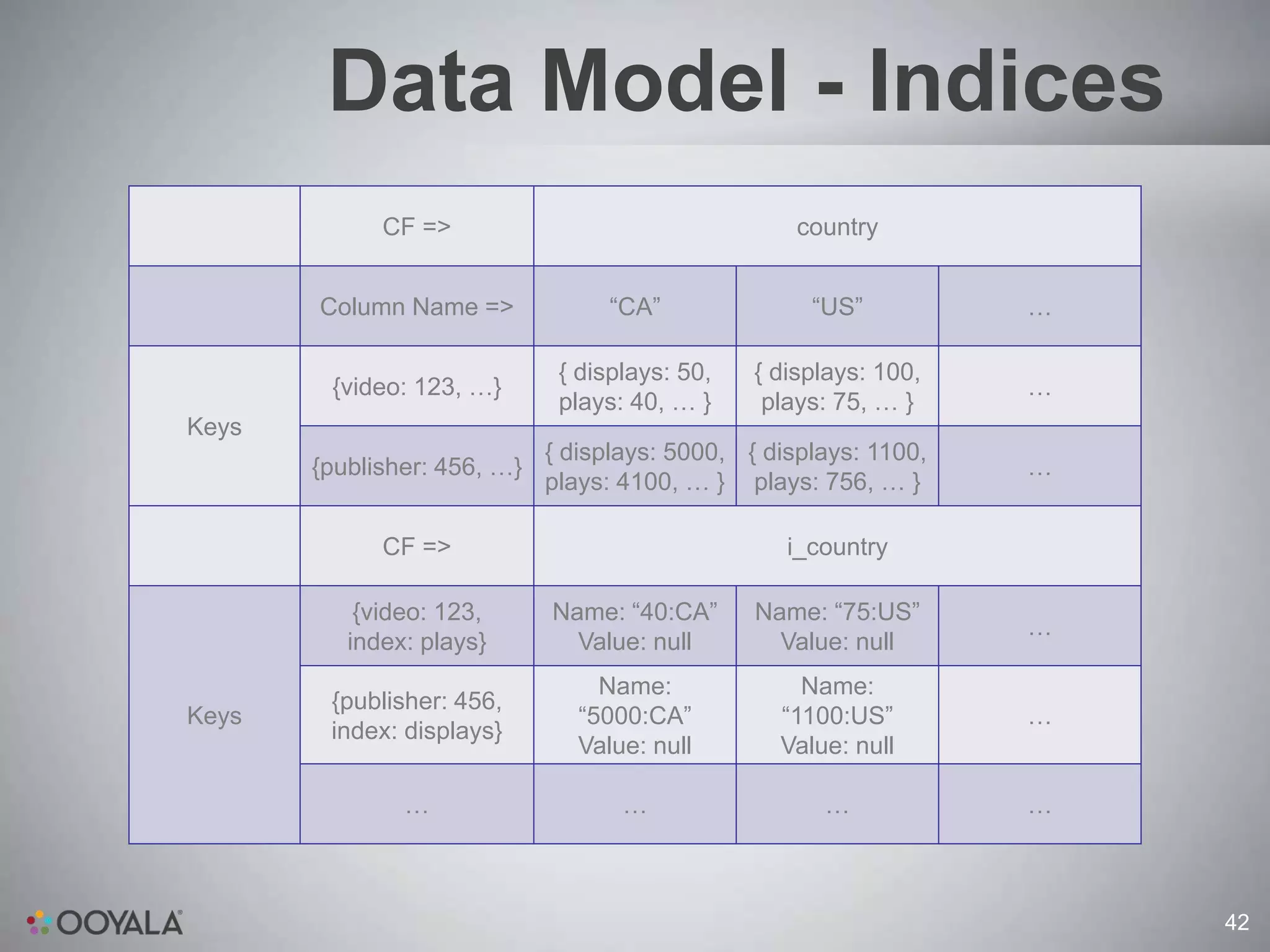
![Data Model – Indices
Trivial to answer a “Top N” query for a single row if the field we sort
on has an index: just read the last N columns of the index row
What if the query spans multiple rows?
Use 3-pass uniform threshold algorithm. Guaranteed to get the top-
N columns in any multi-row aggregate in 3 RPC calls. See:
[http://www.cs.ucsb.edu/research/tech_reports/reports/2005-
14.pdf]
Has some drawbacks: can’t do bottom-N, computing top-N-to-2N is
impossible, have to do top-2N and drop half.
43](https://image.slidesharecdn.com/cassandranyc2011-ilyamaykov-ooyala-scalingvideoanalyticswithapachecassandra-120109183605-phpapp01/75/Cassandra-nyc-2011-ilya-maykov-ooyala-scaling-video-analytics-with-apache-cassandra-43-2048.jpg)































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)














