Download as PDF, PPTX












![Next: Boy ponders the errors of his ways
“this book is composed […] upon one very simple theme
[…] that we can learn from our mistakes”
!
!
!
!
!
!
!
!
!
!
Karl Popper, Conjectures and Refutations](https://image.slidesharecdn.com/e99c6b9c-8e5f-4fc1-90d1-fdfb1fe283f3-150702055920-lva1-app6891/75/Inductive-Reasoning-and-one-of-the-Foundations-of-Machine-Learning-17-2048.jpg)

















![While t ≤ T:
Predict by weighted majority vote.Step 1.
Multiply incorrect experts by β.Step 2.
t ← t+1Step 3.
Set t = 1.
Algorithm #2
What is the regret? [ choose β carefully ]
r
T · log N
2
Pick β in (0,1). Assign 1 to experts.](https://image.slidesharecdn.com/e99c6b9c-8e5f-4fc1-90d1-fdfb1fe283f3-150702055920-lva1-app6891/75/Inductive-Reasoning-and-one-of-the-Foundations-of-Machine-Learning-36-2048.jpg)

![Online Convex Opt.
Scenario: Convex set K; convex loss L(a,b)
[ in both arguments, separately ]
!
At time t,
Forecaster picks at in K
Nature responds with bt in K
[ Nature is adversarial ]
Forecaster’s loss is L(a,b)
Goal: Minimize regret.](https://image.slidesharecdn.com/e99c6b9c-8e5f-4fc1-90d1-fdfb1fe283f3-150702055920-lva1-app6891/75/Inductive-Reasoning-and-one-of-the-Foundations-of-Machine-Learning-38-2048.jpg)






![While t ≤ T:
Step 1.
Step 2.
Set t = 1.
Algorithm #3
What is the regret?
[ choose β carefully ]
diam(K) · Lipschitz(L) ·
p
T
t ← t+1
Pick a1 at random.
at at 1 ·
@
@a
L(at 1, bt 1)](https://image.slidesharecdn.com/e99c6b9c-8e5f-4fc1-90d1-fdfb1fe283f3-150702055920-lva1-app6891/75/Inductive-Reasoning-and-one-of-the-Foundations-of-Machine-Learning-45-2048.jpg)
![Deep thought #3
Those who cannot
remember [their]
past are condemned
to repeat it
George Santayana](https://image.slidesharecdn.com/e99c6b9c-8e5f-4fc1-90d1-fdfb1fe283f3-150702055920-lva1-app6891/75/Inductive-Reasoning-and-one-of-the-Foundations-of-Machine-Learning-46-2048.jpg)












![Meta-Algorithm #4
Play Algorithm #2 against Algorithm W
[ #2 maximizes W’s mistakes ]](https://image.slidesharecdn.com/e99c6b9c-8e5f-4fc1-90d1-fdfb1fe283f3-150702055920-lva1-app6891/75/Inductive-Reasoning-and-one-of-the-Foundations-of-Machine-Learning-59-2048.jpg)
![Meta-Algorithm #4
Play Algorithm #2 against Algorithm W
[ #2 maximizes W’s mistakes ]
inf
w
sup
d
V(w, d)
1
2
✏
Algorithm #2
Algorithm W](https://image.slidesharecdn.com/e99c6b9c-8e5f-4fc1-90d1-fdfb1fe283f3-150702055920-lva1-app6891/75/Inductive-Reasoning-and-one-of-the-Foundations-of-Machine-Learning-60-2048.jpg)
![Meta-Algorithm #4
• Freund and Schapire 1995
!
• Best learning algorithm in
late 1990s and early 2000s
!
• Authors won Gödel prize
Play Algorithm #2 against Algorithm W
[ #2 maximizes W’s mistakes ]
inf
w
sup
d
V(w, d)
1
2
✏
Algorithm #2
Algorithm W](https://image.slidesharecdn.com/e99c6b9c-8e5f-4fc1-90d1-fdfb1fe283f3-150702055920-lva1-app6891/75/Inductive-Reasoning-and-one-of-the-Foundations-of-Machine-Learning-61-2048.jpg)









![“[A] theory of induction is superfluous.
It has no function in a logic of science.
The best we can say of a hypothesis
is that up to now it has been able to
show its worth, and that it has been
more successful that other
hypotheses although, in principle, it
can never be justified, verified, or
even shown to be probable. This
appraisal of the hypothesis relies
solely upon deductive consequences
(predictions) which may be drawn
from the hypothesis: There is no need
to even mention induction.”](https://image.slidesharecdn.com/e99c6b9c-8e5f-4fc1-90d1-fdfb1fe283f3-150702055920-lva1-app6891/75/Inductive-Reasoning-and-one-of-the-Foundations-of-Machine-Learning-71-2048.jpg)


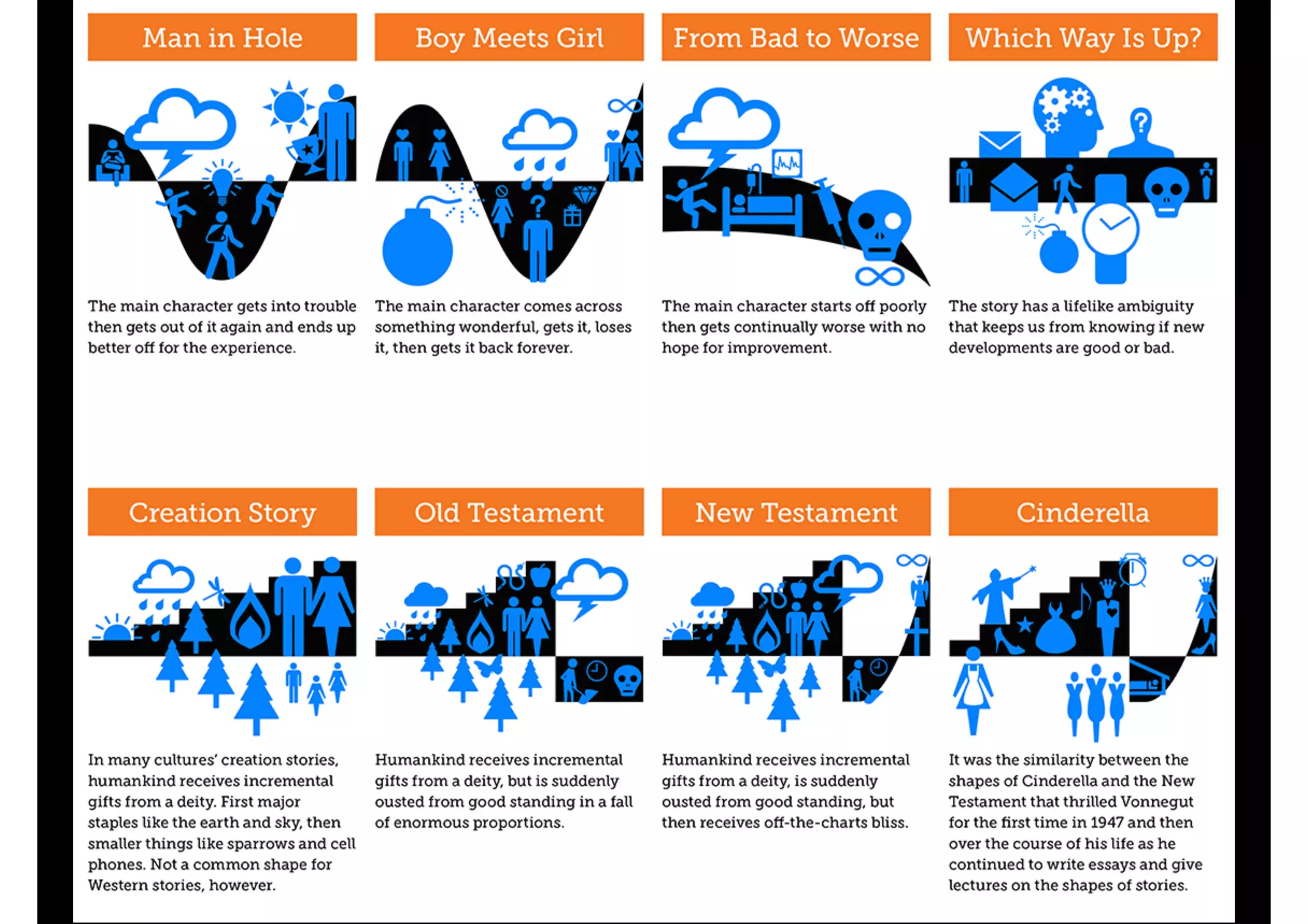
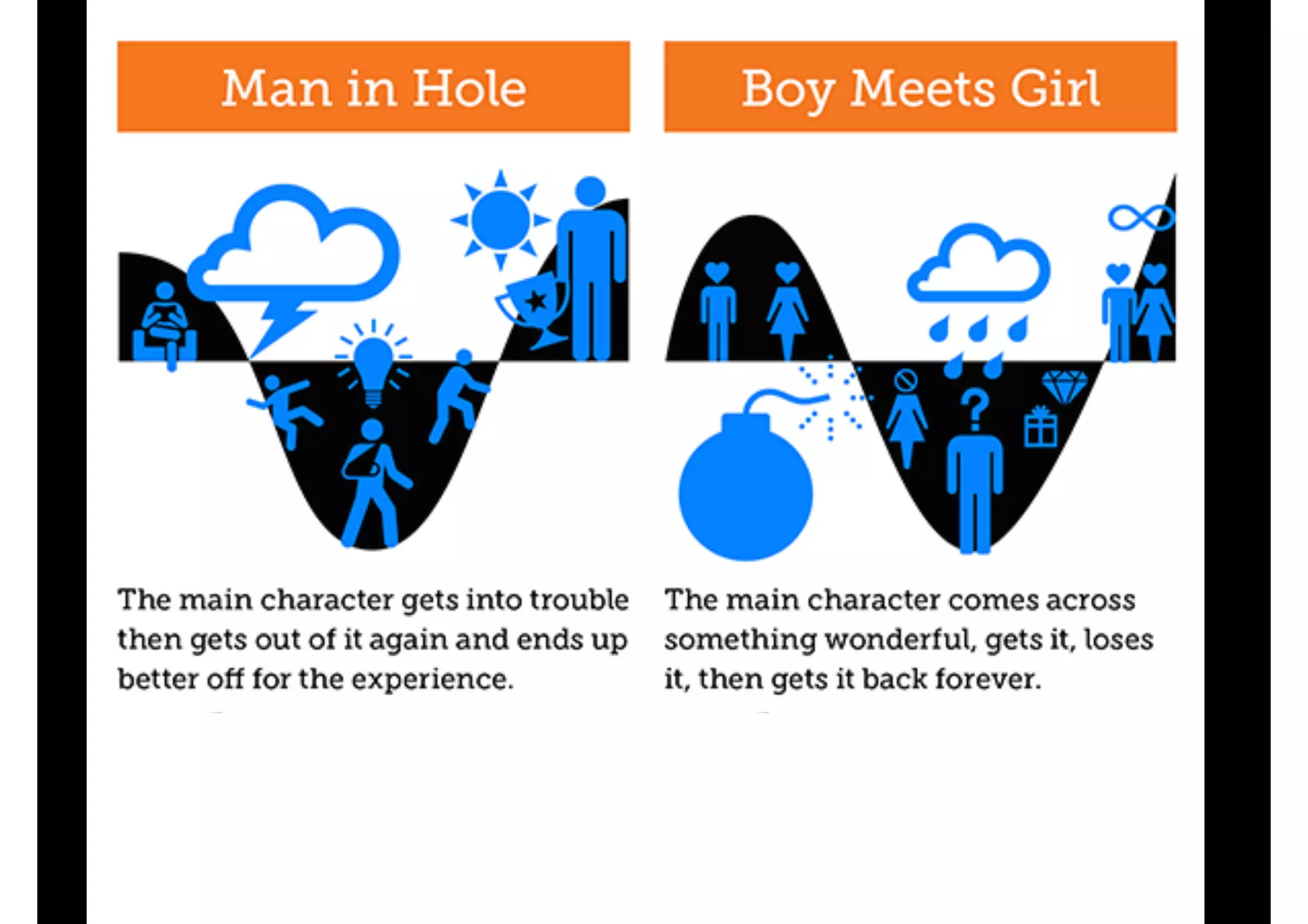
The document discusses the principles of inductive reasoning and various machine learning algorithms, exploring how algorithms learn from mistakes rather than relying solely on deductive reasoning. It outlines scenarios for sequential and adversarial prediction, emphasizing the importance of minimizing regret and the challenges posed by non-convex optimization in deep learning. The document concludes by highlighting the advancements in deep learning and mentions influential figures in the field.






































![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dunja Adzic Jovanovic - AI and Cybersecurity: Defending Data ...](https://cdn.slidesharecdn.com/ss_thumbnails/o1zylpbhrtwnixxq2xj8-7-251211083048-185086f6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Nikolay Burlutskiy - Best Practices for Building Enterprise M...](https://cdn.slidesharecdn.com/ss_thumbnails/uirvaiuvq8y1w8hzd9tx-7-251212103249-2619edb4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Milan Sekuloski - Data, Defence, and Development: Cybersecuri...](https://cdn.slidesharecdn.com/ss_thumbnails/dfrkwwx4qly6atqpbl4z-4-251209104645-c3d4b0ca-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Vladimir Jelic - The AI-Driven Security Shift From Reactive D...](https://cdn.slidesharecdn.com/ss_thumbnails/6g5gj25mtjwayniqem1t-6-251209104645-7a5a5fc6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dusan Nesic - Securing Tomorrow’s Infrastructure: Why Cyber-P...](https://cdn.slidesharecdn.com/ss_thumbnails/qikbszfftyowjm2q6duw-1-251211083848-8f2ead6b-thumbnail.jpg?width=640&height=640&fit=bounds)
