Downloaded 157 times




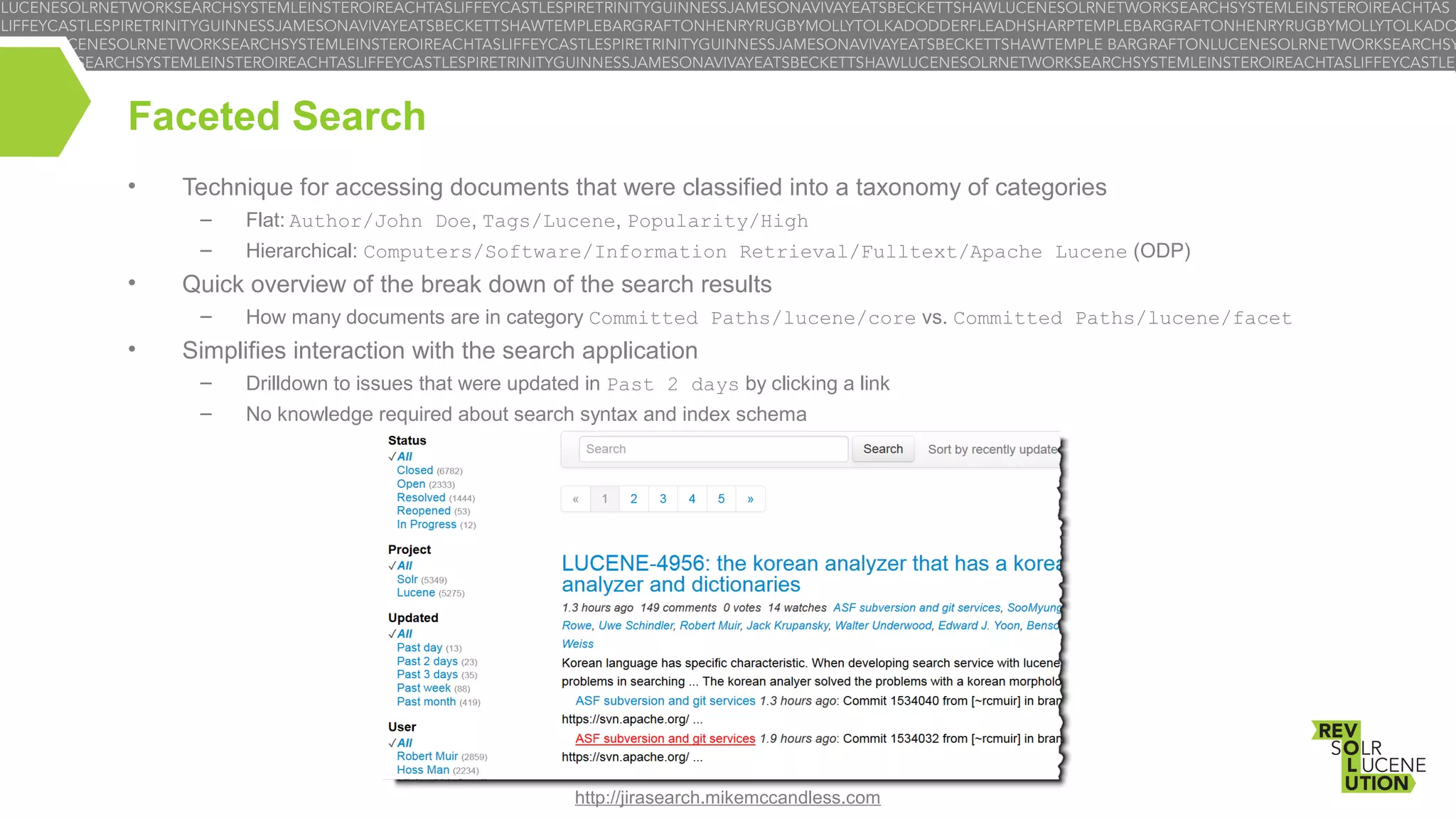


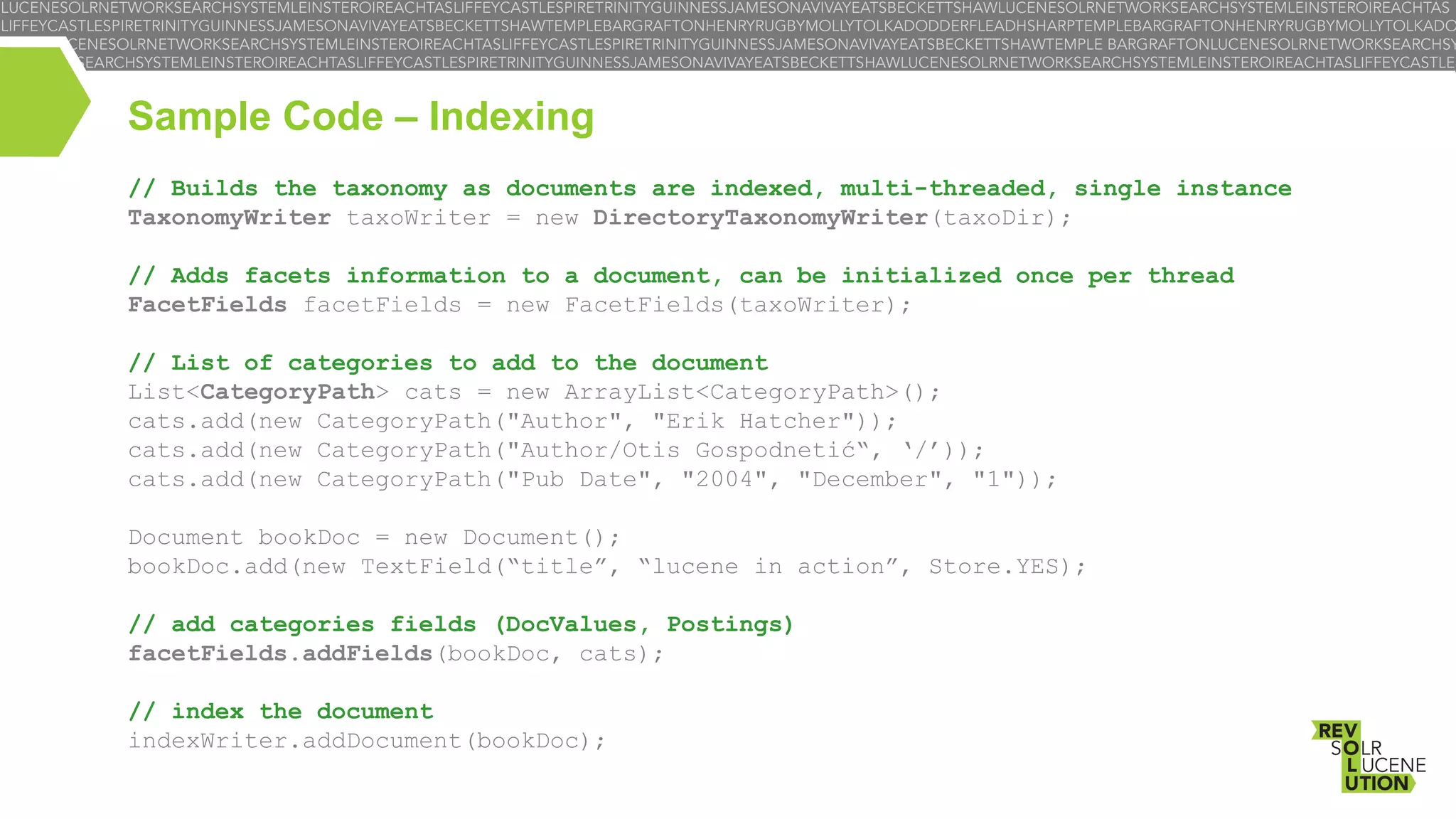
![Sample Code – Search
// Open an NRT TaxonomyReader
TaxonomyReader taxoReader = new DirectoryTaxonomyReader(taxoWriter);
// Define the facets to
FacetSearchParams fsp =
fsp.addFacetRequest(new
fsp.addFacetRequest(new
aggregate (top-10 categories for each)
new FacetSearchParams();
CountFacetRequest(new CategoryPath("Author"), 10));
CountFacetRequest(new CategoryPath("Pub Date"), 10));
// Collect both top-K facets and top-N matching documents
TopDocsCollector tdc = TopScoredDocCollector.create(10, true);
FacetsCollector fc = FacetsCollector.create(fsp, indexr, taxor);
Query q = new TermQuery(new Term(“title”, “lucene”));
searcher.search(q, MultiCollector.wrap(tdc, fc));
// Traverse the top facets
for (FacetResult fres : facetsCollector.getFacetResults()) {
FacetResultNode root = fres.getFacetResultNode();
System.out.println(String.format("%s (%d)", root.label, root.value));
for (FacetResultNode cat : root.getSubResults()) {
System.out.println(“ “ + cat.label.components[0] + “ (“ + cat.value + “)”);
}
}](https://image.slidesharecdn.com/lsrdublinlucenefacetserera-131118213835-phpapp02/75/Faceted-Search-with-Lucene-9-2048.jpg)

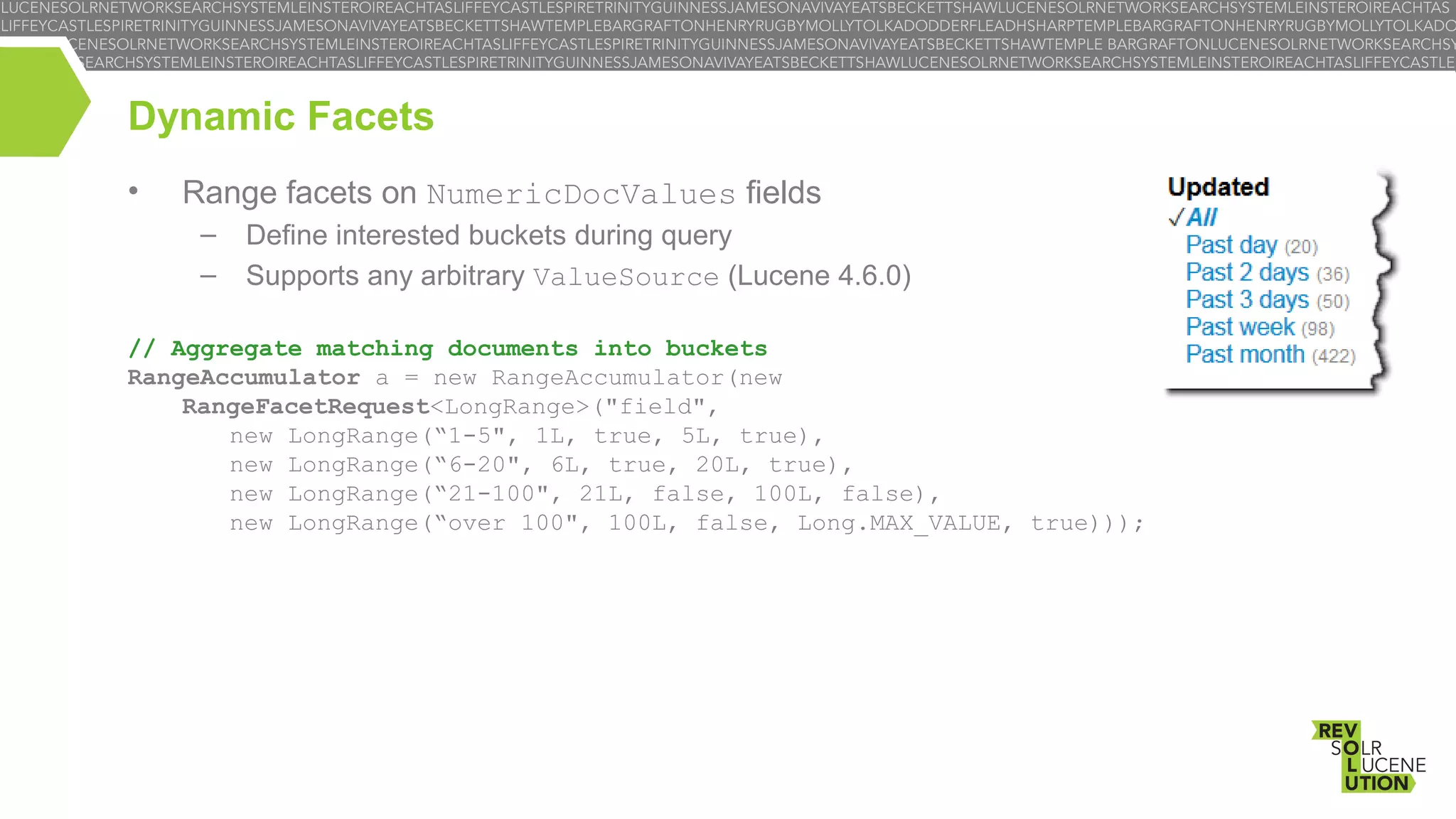
![Facet Associations
•
Not all facets created equal
–
–
–
•
Categories can have values associated with them per document
–
–
•
Categories added by an automatic categorization system, e.g. Category/Apache
Lucene (0.74) (confidence level is 0.74)
Important metadata about the facet, e.g. Contracts/US ($5M) (total $$$ generated
from contracts)
Complex structures, e.g. Users/Shai Erera (lastAccess=YYYY/MM/DD,
numUpdates=8…)
They are later aggregated by these values
NOTE: ≠ NumericDocValuesFields!
Facet associations are completely customizable – encoded as a byte[] per
document
http://shaierera.blogspot.com/2013/01/facet-associations.html](https://image.slidesharecdn.com/lsrdublinlucenefacetserera-131118213835-phpapp02/75/Faceted-Search-with-Lucene-12-2048.jpg)


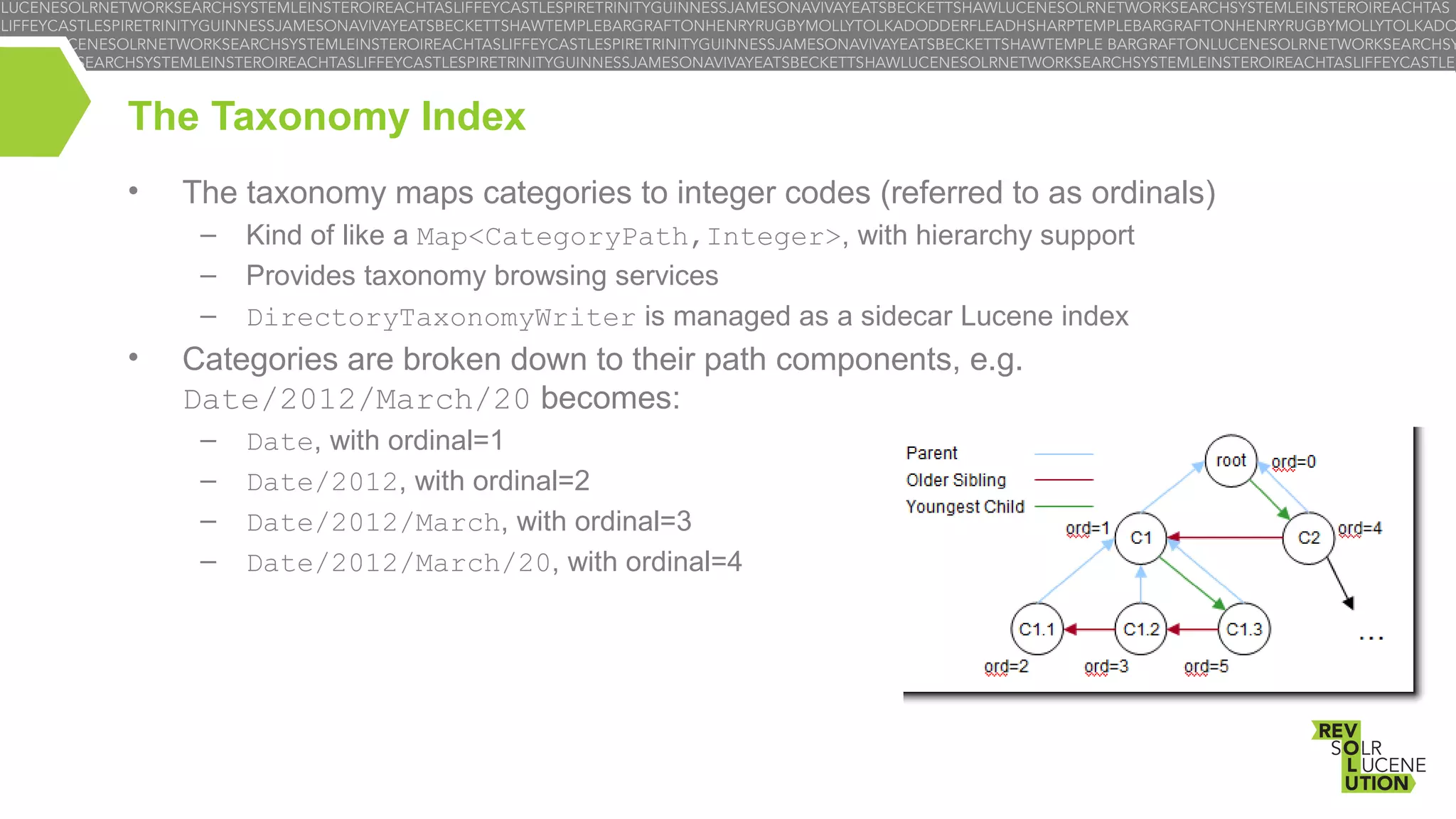






The document outlines the concept of faceted search using Lucene, highlighting its features, indexing modes, and components involved in implementing this search technique. It discusses taxonomy-based and sorted set faceting, drilldown capabilities, dynamic facets, and the performance improvements introduced in recent versions. Additionally, it includes sample code for indexing and searching with facets, while noting the flexible structure of facets and their associations with metadata.











































































































