Download as PDF, PPTX









![Overview of the SIREn API
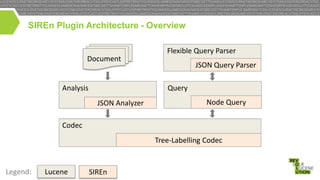
Document
Query
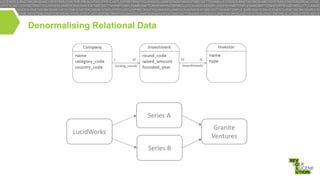
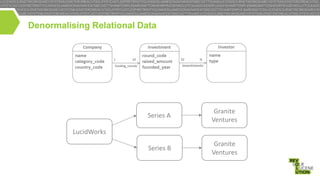
{
"name" : "LucidWorks",
"category_code" : "analytics",
"funding_rounds" : [
{
"round_code" : "a",
"raised_amount" : 6000000,
"funded_year" : 2009,
"investments" : [
{
"name" : "Granite Ventures",
"type" : "financial-org"
},
…
]
},
…
]
}
(category_code :
analytics)
AND
(funding_rounds : {
round_code : seed OR a OR angel,
raised_amount : [0 TO 12000000],
* : {
type : financial-org
}
})](https://image.slidesharecdn.com/siren-final-131120111510-phpapp01/85/High-Performance-JSON-Search-and-Relational-Faceted-Browsing-with-Lucene-11-320.jpg)

![Theory behind SIREn: Tree-Labelling
{
"name" : "LucidWorks",
"category_code" : "analytics",
"funding_rounds" : [
{
"round_code" : "a",
"raised_amount" : 6000000,
"funded_year" : 2009,
…
},
…
]
}
name
LucidWorks
funding_
rounds
round_
code
a
raised_
amount
6000000
…](https://image.slidesharecdn.com/siren-final-131120111510-phpapp01/85/High-Performance-JSON-Search-and-Relational-Faceted-Browsing-with-Lucene-13-320.jpg)
![Theory behind SIREn: Tree-Labelling
1
{
"name" : "LucidWorks",
"category_code" : "analytics",
"funding_rounds" : [
{
"round_code" : "a",
"raised_amount" : 6000000,
"funded_year" : 2009,
…
},
…
]
}
name
LucidWorks
1.1
1.1.1
funding_
rounds
1.2
1.2.1
round_
code
a
1.2.2.1
1.2.2.1.1
raised_
amount
6000000
1.2.2.2
…
1.2.2
1.2.2.2.1](https://image.slidesharecdn.com/siren-final-131120111510-phpapp01/85/High-Performance-JSON-Search-and-Relational-Faceted-Browsing-with-Lucene-14-320.jpg)







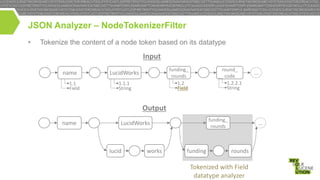





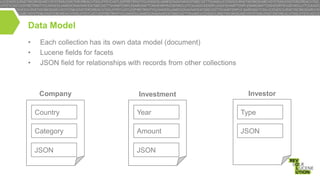
![JSON Model
•
•
JSON field: Tree covering all the relationships with records from other collections
Resulting tree can be very large
Company
Investment
Investor
category_
code
round_
code
type
country_
code
funding_
rounds
raised_
amount
investments -1
funding_
rounds -1
[…]
category_
code
round_
code
raised_
amount
investments
[…]
country_
code
[…]
type
investments
[…]
type
[…]
round_
code
raised_
amount
funding_
rounds -1
[…]
category_
code
country_
code](https://image.slidesharecdn.com/siren-final-131120111510-phpapp01/85/High-Performance-JSON-Search-and-Relational-Faceted-Browsing-with-Lucene-42-320.jpg)
![JSON Model
•
•
JSON field: Tree covering all the relationships with records from other collections
Resulting tree can be very large
Company
Investment
category_
code
country_
code
funding_
rounds
[…]
round_
code
raised_
amount
investments
[…]
type
Investor](https://image.slidesharecdn.com/siren-final-131120111510-phpapp01/85/High-Performance-JSON-Search-and-Relational-Faceted-Browsing-with-Lucene-43-320.jpg)
![JSON Model
•
•
JSON field: Tree covering all the relationships with records from other collections
Resulting tree can be very large
Company
Investment
category_
code
country_
code
funding_
rounds
[…]
round_
code
raised_
amount
investments
[…]
type
Investor](https://image.slidesharecdn.com/siren-final-131120111510-phpapp01/85/High-Performance-JSON-Search-and-Relational-Faceted-Browsing-with-Lucene-44-320.jpg)
![JSON Model
•
•
JSON field: Tree covering all the relationships with records from other collections
Resulting tree can be very large
Company
Investment
round_
code
raised_
amount
funding_
rounds -1
[…]
category_
code
country_
code
investments
[…]
type
Investor](https://image.slidesharecdn.com/siren-final-131120111510-phpapp01/85/High-Performance-JSON-Search-and-Relational-Faceted-Browsing-with-Lucene-45-320.jpg)
![JSON Model
•
•
JSON field: Tree covering all the relationships with records from other collections
Resulting tree can be very large
Company
Investment
round_
code
raised_
amount
funding_
rounds -1
[…]
category_
code
country_
code
investments
[…]
type
Investor](https://image.slidesharecdn.com/siren-final-131120111510-phpapp01/85/High-Performance-JSON-Search-and-Relational-Faceted-Browsing-with-Lucene-46-320.jpg)
![JSON Model
•
•
JSON field: Tree covering all the relationships with records from other collections
Resulting tree can be very large
Company
Investment
Investor
type
investments -1
[…]
round_
code
raised_
amount
funding_
rounds -1
[…]
category_
code
country_
code](https://image.slidesharecdn.com/siren-final-131120111510-phpapp01/85/High-Performance-JSON-Search-and-Relational-Faceted-Browsing-with-Lucene-47-320.jpg)
![JSON Model
•
•
JSON field: Tree covering all the relationships with records from other collections
Resulting tree can be very large
Company
Investment
Investor
type
investments -1
[…]
round_
code
raised_
amount
funding_
rounds -1
[…]
category_
code
country_
code](https://image.slidesharecdn.com/siren-final-131120111510-phpapp01/85/High-Performance-JSON-Search-and-Relational-Faceted-Browsing-with-Lucene-48-320.jpg)
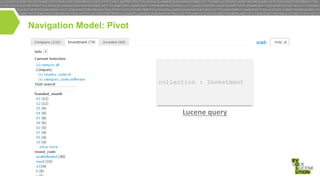
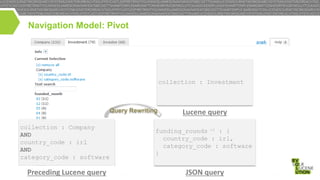
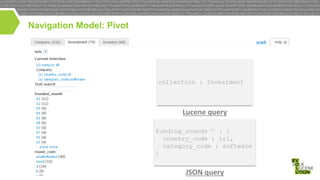
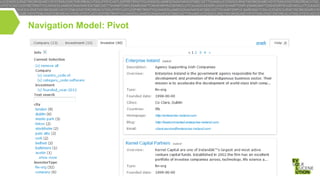
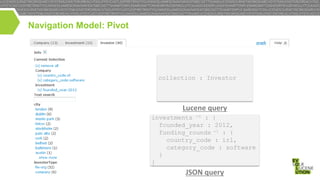







This document discusses high performance JSON search and relational faceted browsing using Lucene. It introduces SIREn, a Lucene plugin for indexing and searching JSON documents with a nested data model. SIREn uses tree labeling techniques to represent the JSON document structure and enable both full-text and structural queries. It also allows for relational faceted browsing across multiple record collections through pivot navigation and query rewriting. While BlockJoin supports some nested data in Lucene, SIREn has better scalability through its compression techniques and more flexibility through its schema-agnostic approach.






































































































