Downloaded 151 times


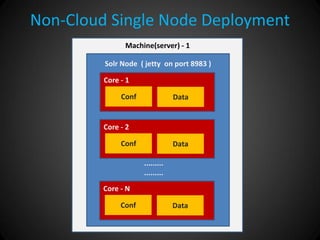


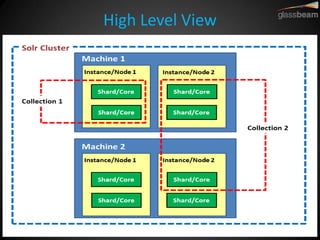



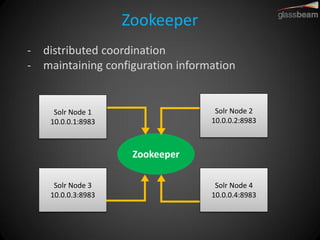
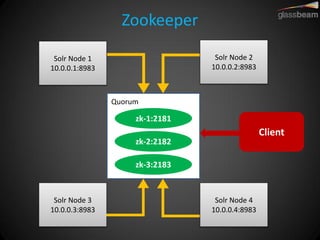
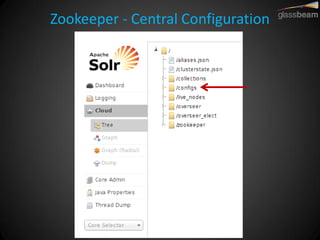



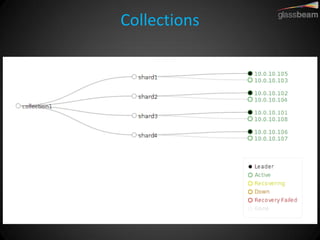


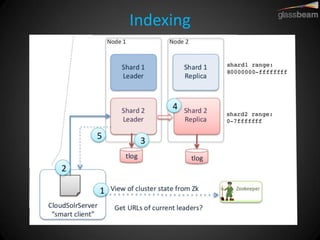

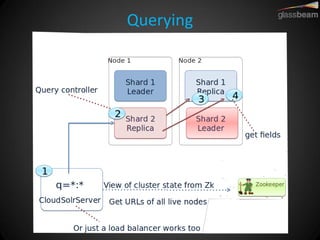


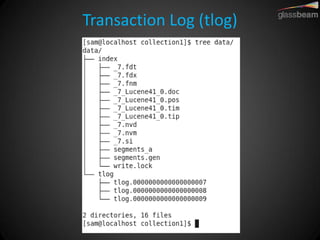





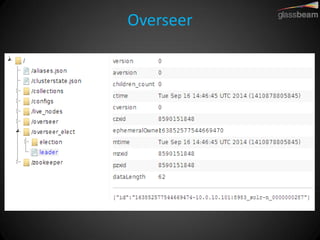

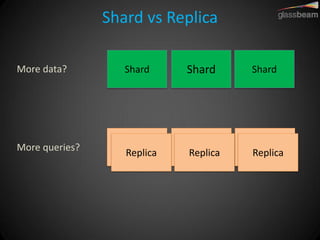


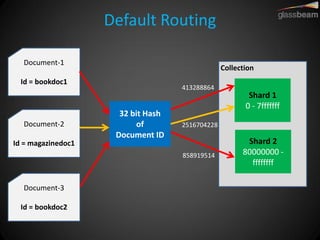
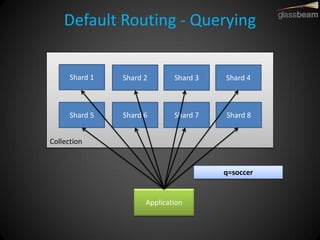


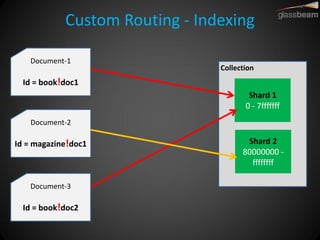

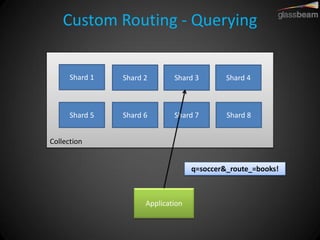


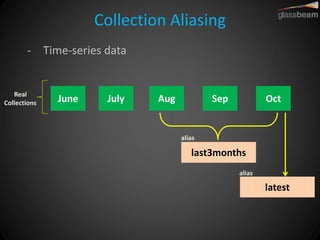
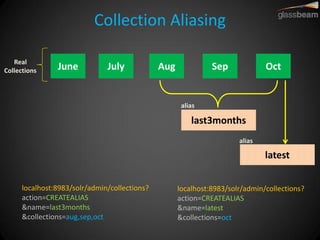
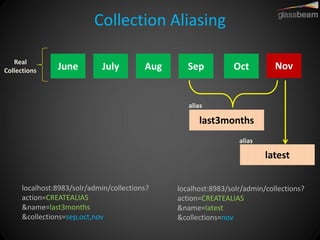




Solr Cloud allows Solr to be distributed and run across multiple servers for increased performance, scalability, availability, and elasticity. It uses Zookeeper for coordination and shares an index across multiple cores and collections. Documents are routed and replicated to shards and replicas based on a hashing function or custom routing rules to partition the data. Queries are distributed and results merged to provide scalable search across an elastic, fault-tolerant cluster.


















































![[Hic2011] using hadoop lucene-solr-for-large-scale-search by systex](https://cdn.slidesharecdn.com/ss_thumbnails/hic2011usinghadoop-lucene-solr-for-large-scale-searchbysystex-111205021544-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
















![[DSC Europe 25] Josip Saban - Career building for data professionals.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/zroflcttkm1vmli0txea-josip-saban-career-building-for-data-professionals-260123083019-587cdb8c-thumbnail.jpg?width=640&height=640&fit=bounds)
















