Download as ODP, PPTX













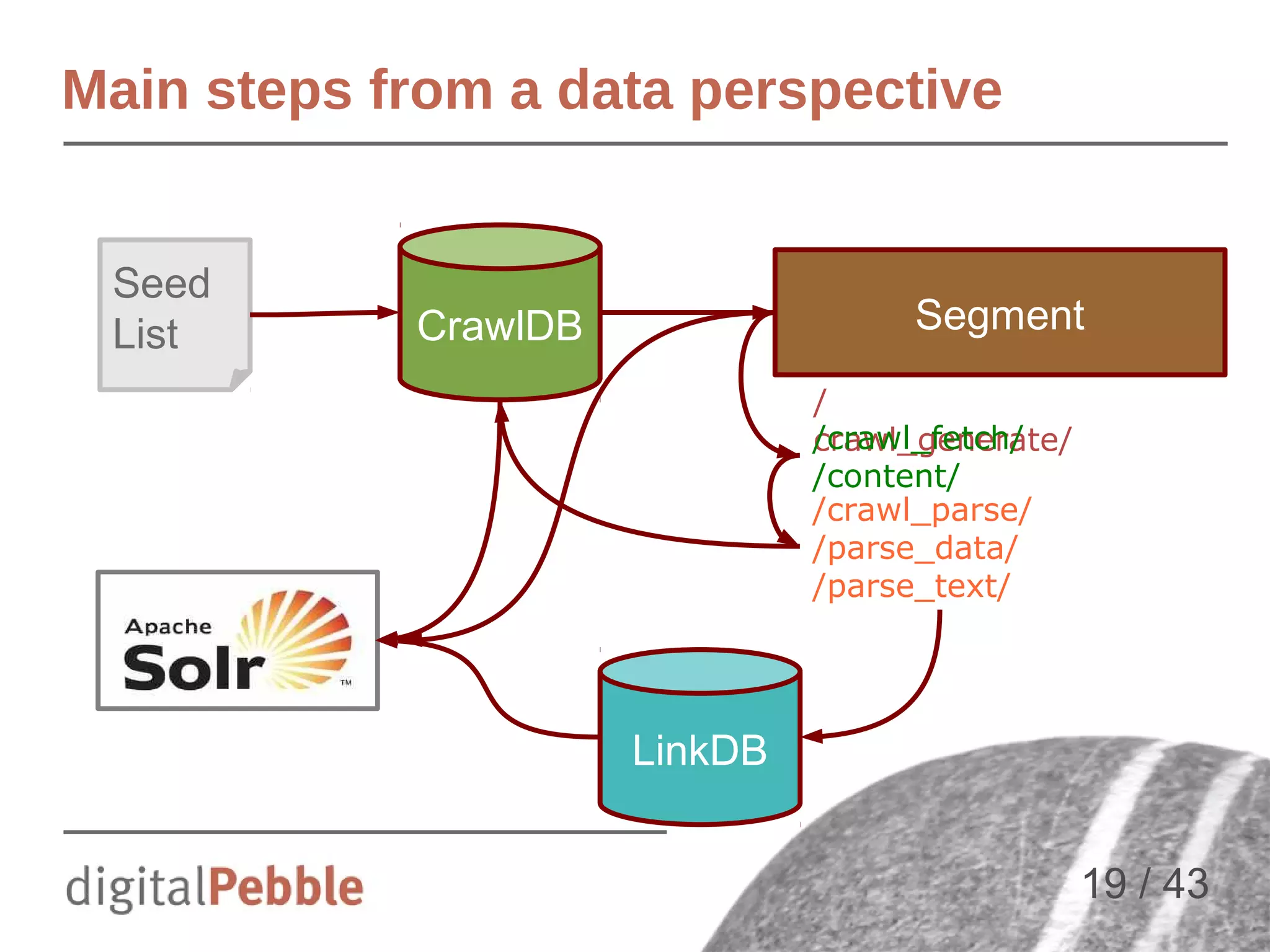
![Typical Nutch Steps
Same in 1.x and 2.x
Sequence of batch operations
1)
2)
3)
4)
5)
6)
7)
Inject → populates CrawlDB from seed list
Generate → Selects URLS to fetch in segment
Fetch → Fetches URLs from segment
Parse → Parses content (text + metadata)
UpdateDB → Updates CrawlDB (new URLs, new status...)
InvertLinks → Build Webgraph
Index → Send docs to [SOLR | ES | CloudSearch | … ]
Repeat steps 2 to 7
Or use the all-in-one crawl script
18 / 43](https://image.slidesharecdn.com/jnioche-lucenerevoeu-2013-131107152915-phpapp01/75/Large-Scale-Crawling-with-Apache-Nutch-and-Friends-18-2048.jpg)
![Frontier expansion
Manual “discovery”
– Adding new URLs by
hand, “seeding”
Automatic discovery
of new resources
(frontier expansion)
– Not all outlinks are
equally useful - control
– Requires content
parsing and link
extraction
seed
i=1
i=2
i=3
[Slide courtesy of A. Bialecki]
20 / 43](https://image.slidesharecdn.com/jnioche-lucenerevoeu-2013-131107152915-phpapp01/75/Large-Scale-Crawling-with-Apache-Nutch-and-Friends-20-2048.jpg)









![AVRO Schema => Java code
{"name": "WebPage",
"type": "record",
"namespace": "org.apache.nutch.storage",
"fields": [
{"name": "baseUrl", "type": ["null", "string"] },
{"name": "status", "type": "int"},
{"name": "fetchTime", "type": "long"},
{"name": "prevFetchTime", "type": "long"},
{"name": "fetchInterval", "type": "int"},
{"name": "retriesSinceFetch", "type": "int"},
{"name": "modifiedTime", "type": "long"},
{"name": "protocolStatus", "type": {
"name": "ProtocolStatus",
"type": "record",
"namespace": "org.apache.nutch.storage",
"fields": [
{"name": "code", "type": "int"},
{"name": "args", "type": {"type": "array", "items": "string"}},
{"name": "lastModified", "type": "long"}
]
}},
[…]
30 / 43](https://image.slidesharecdn.com/jnioche-lucenerevoeu-2013-131107152915-phpapp01/75/Large-Scale-Crawling-with-Apache-Nutch-and-Friends-30-2048.jpg)














The document provides an overview of Apache Nutch, a distributed framework for large-scale web crawling that integrates with the Apache ecosystem including Hadoop and Solr. It covers the history, installation, operational steps, features, and use cases of Nutch, highlighting its extensibility through plugins and its application in various domains like search and data mining. The presentation also discusses future developments and improvements for Nutch 2.x, including its alignment with modern data storage solutions through Apache Gora.


































































![A customized web search engine [autosaved]](https://cdn.slidesharecdn.com/ss_thumbnails/acustomizedwebsearchengineautosaved-130724201343-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)



















