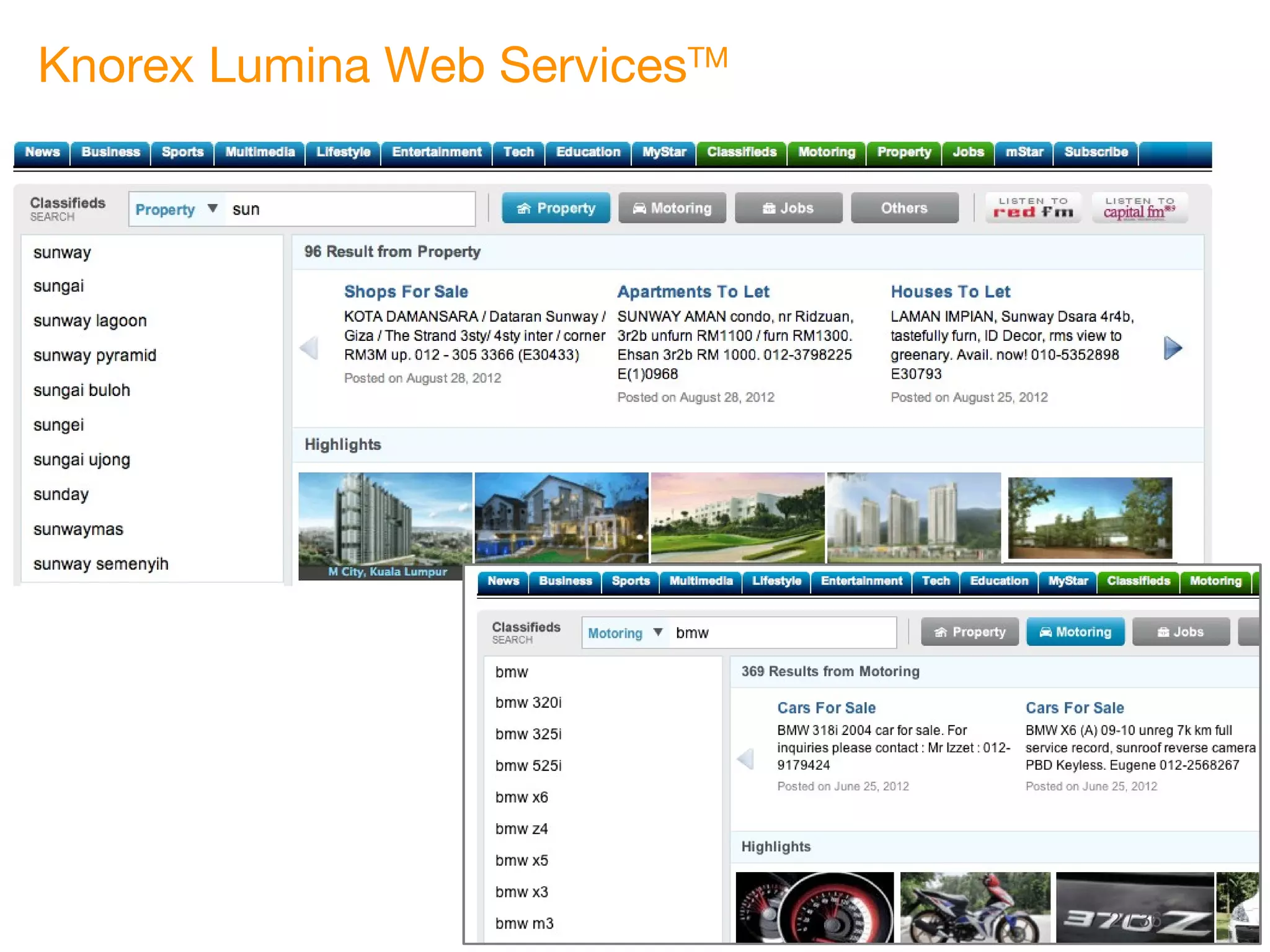
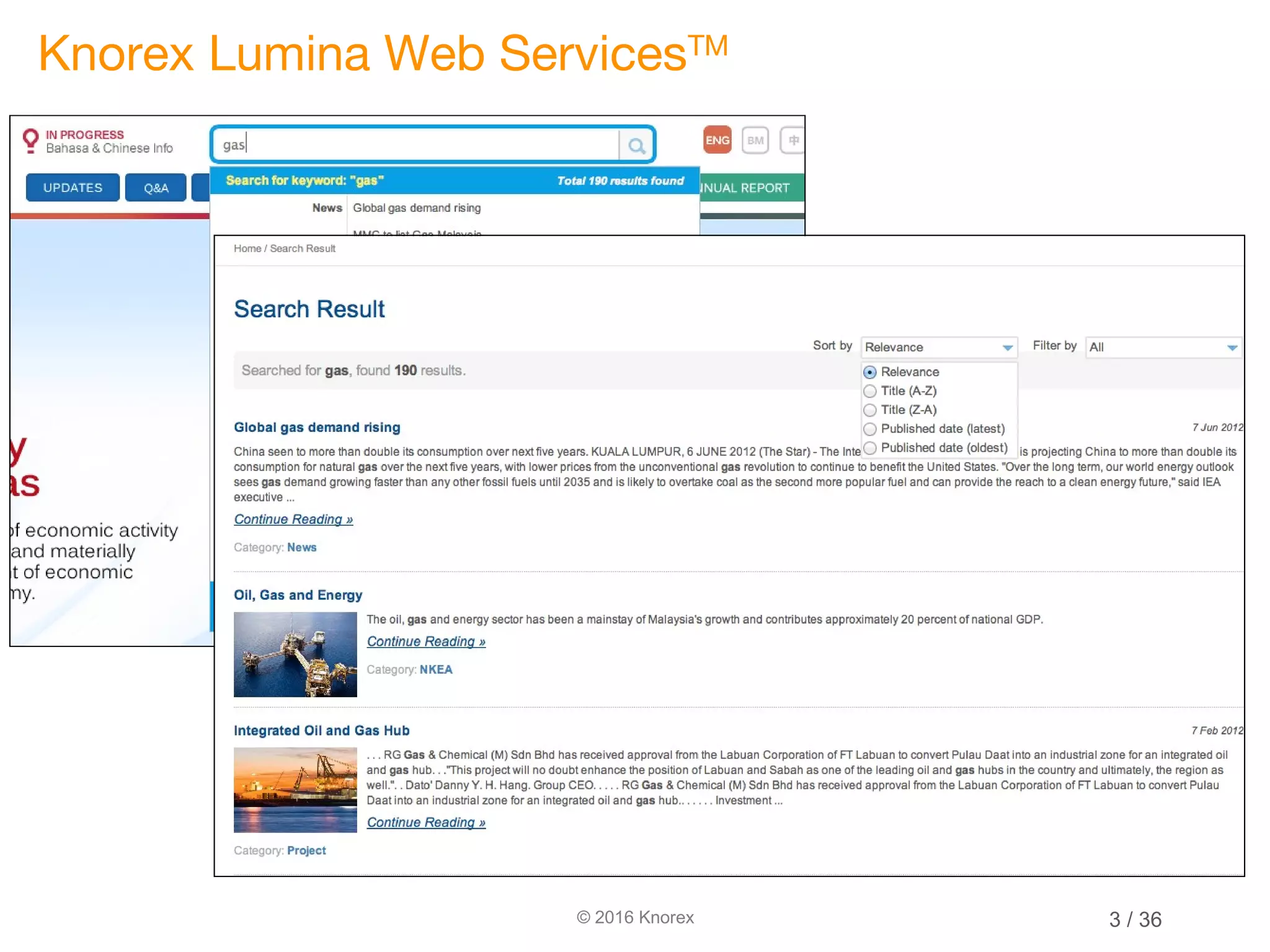
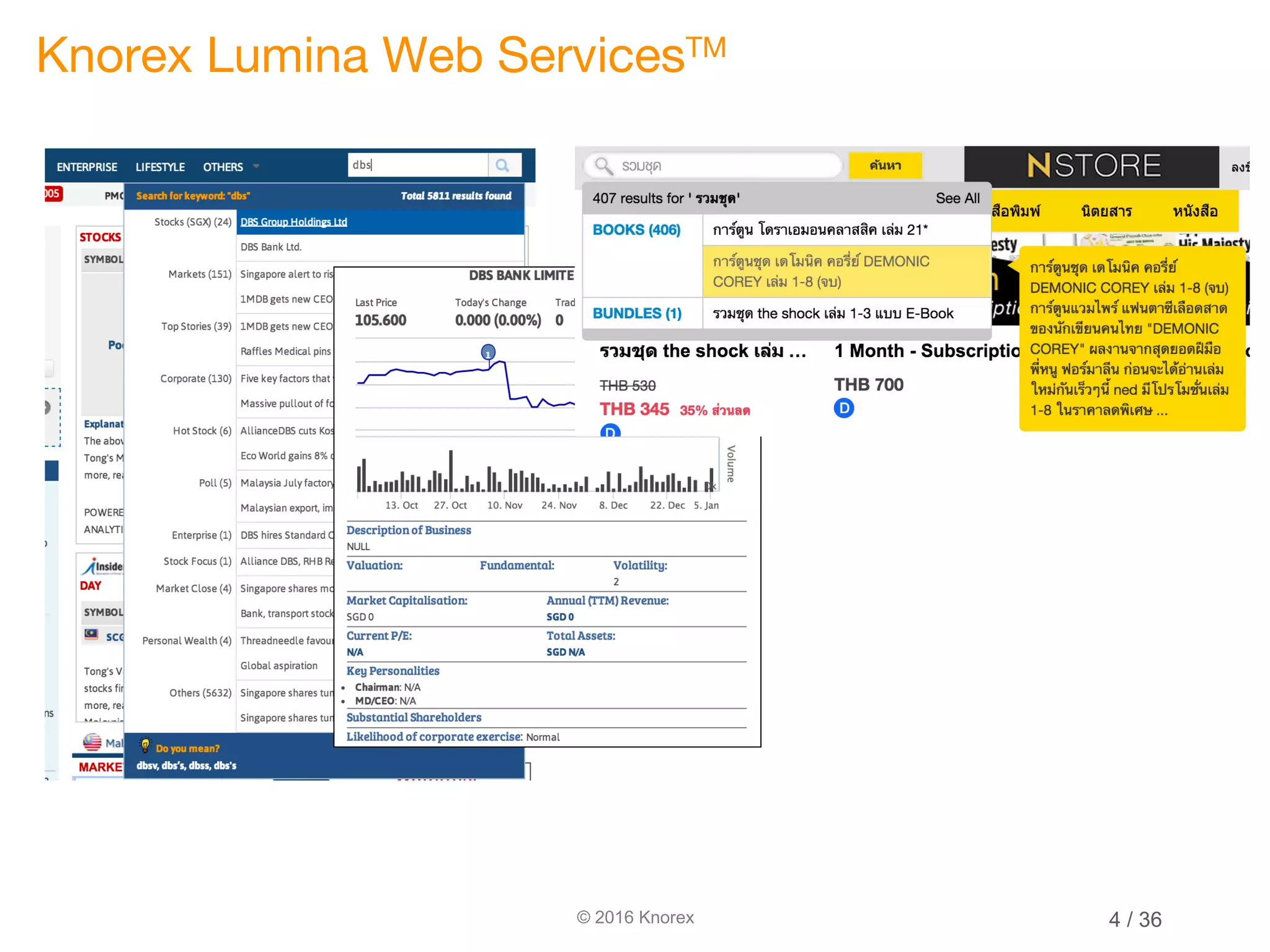
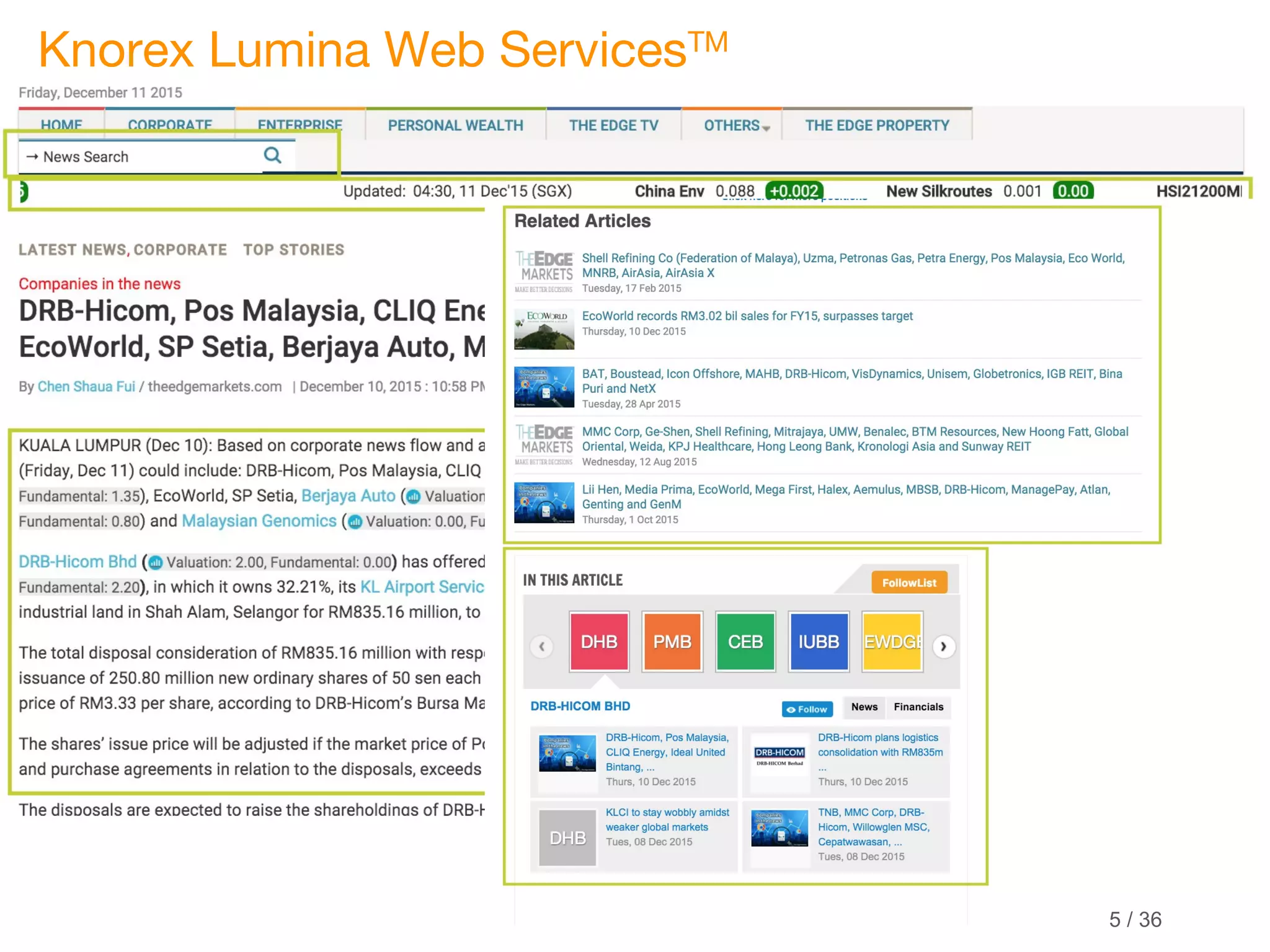
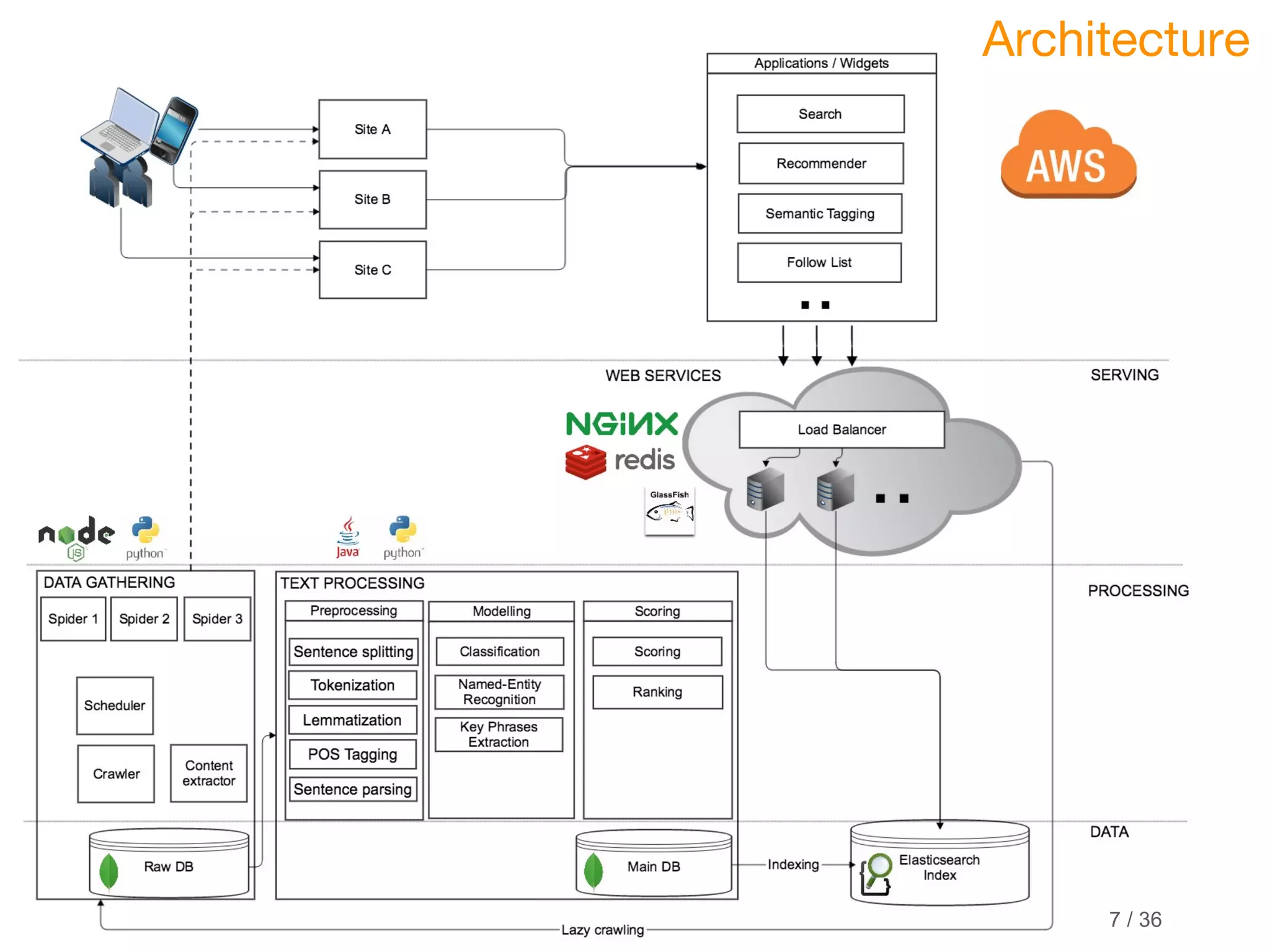
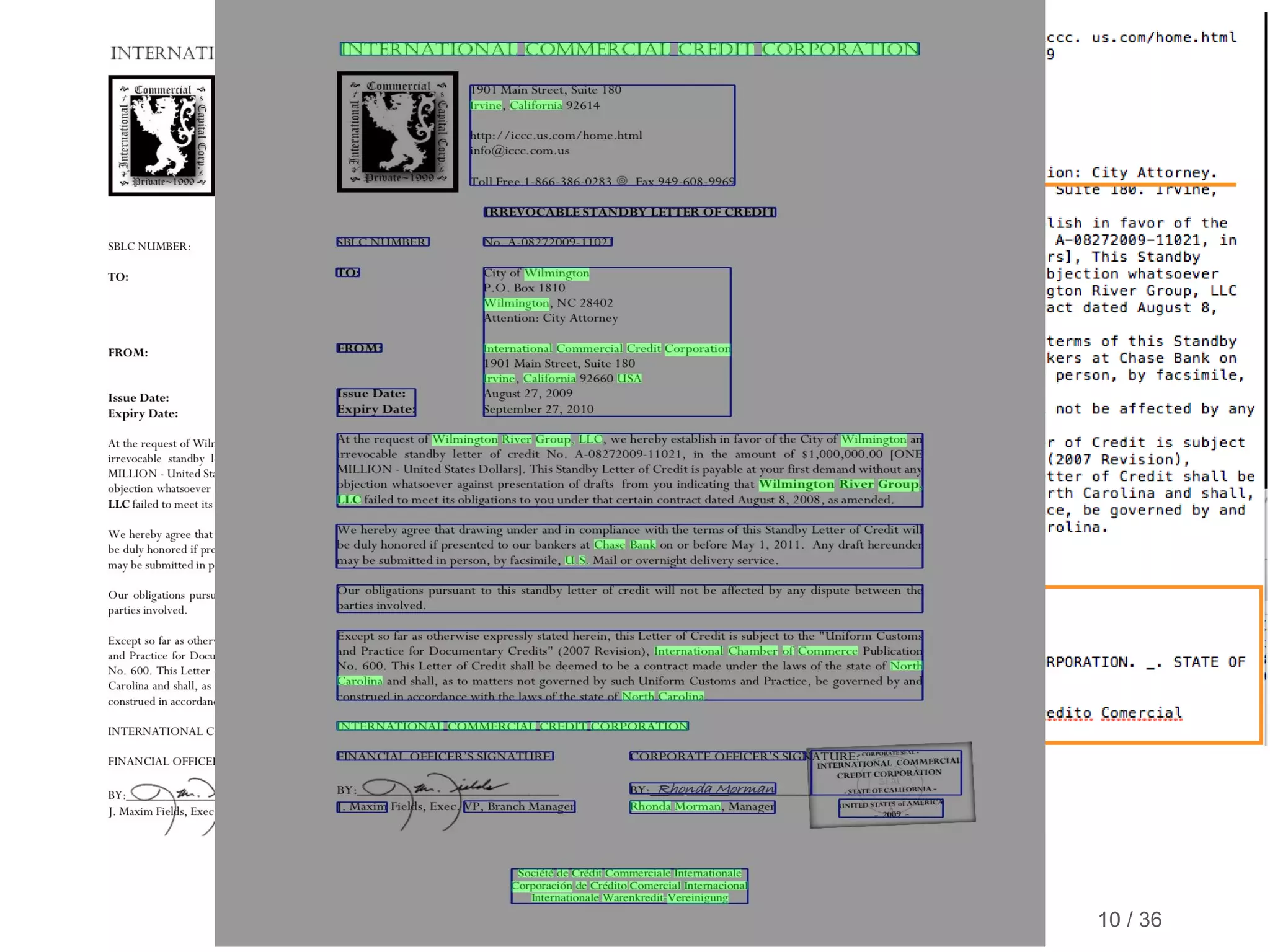
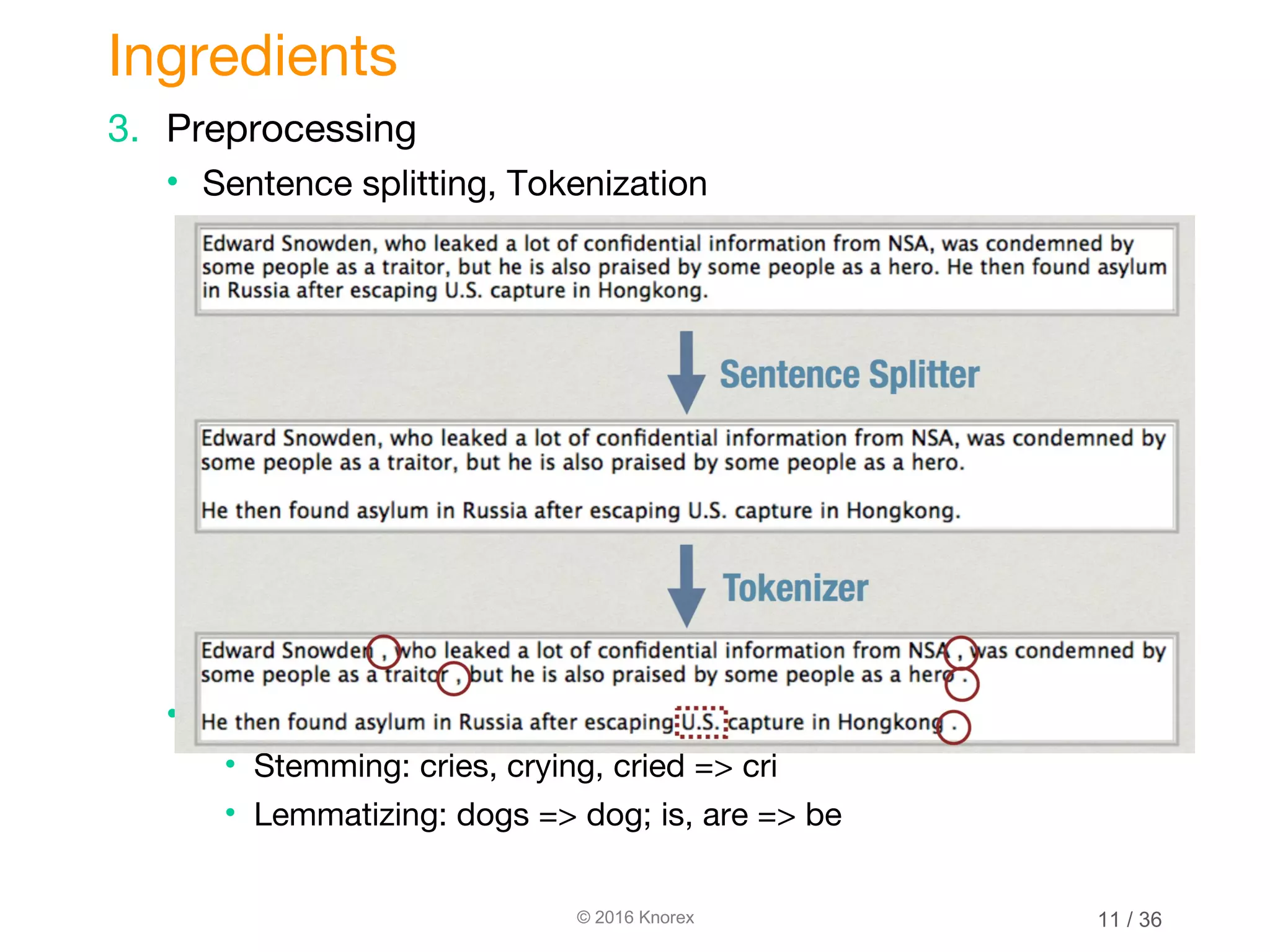
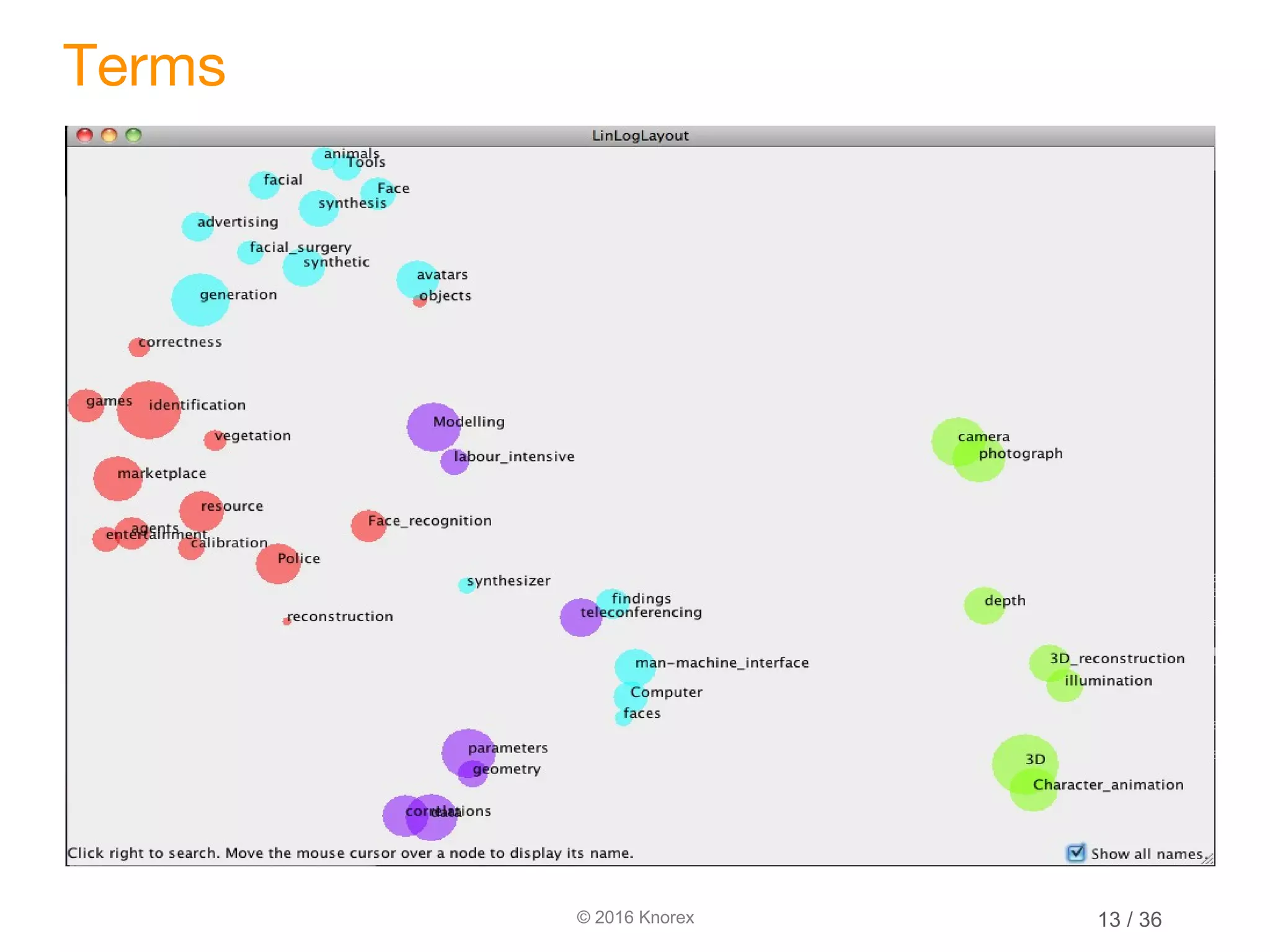
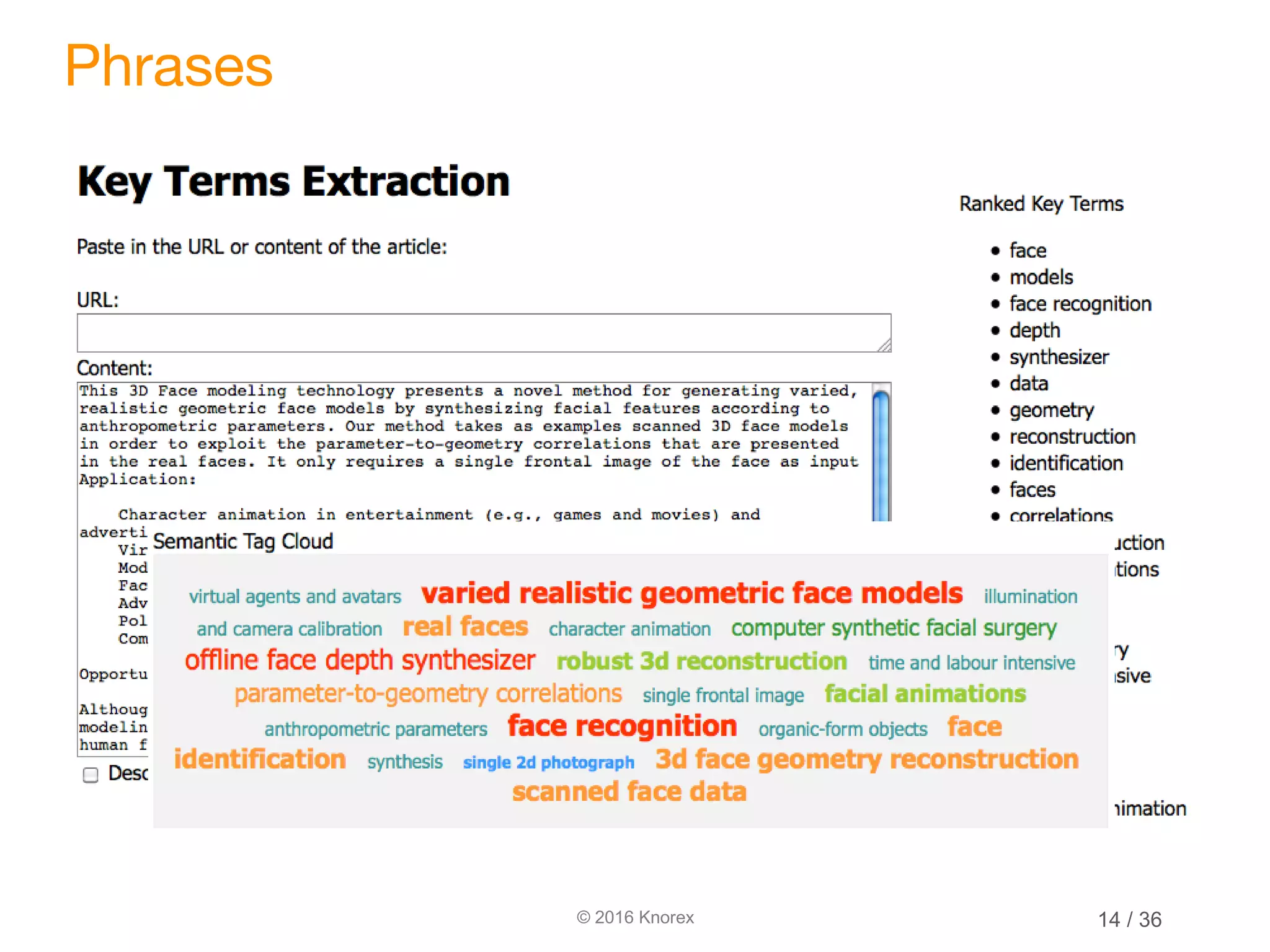
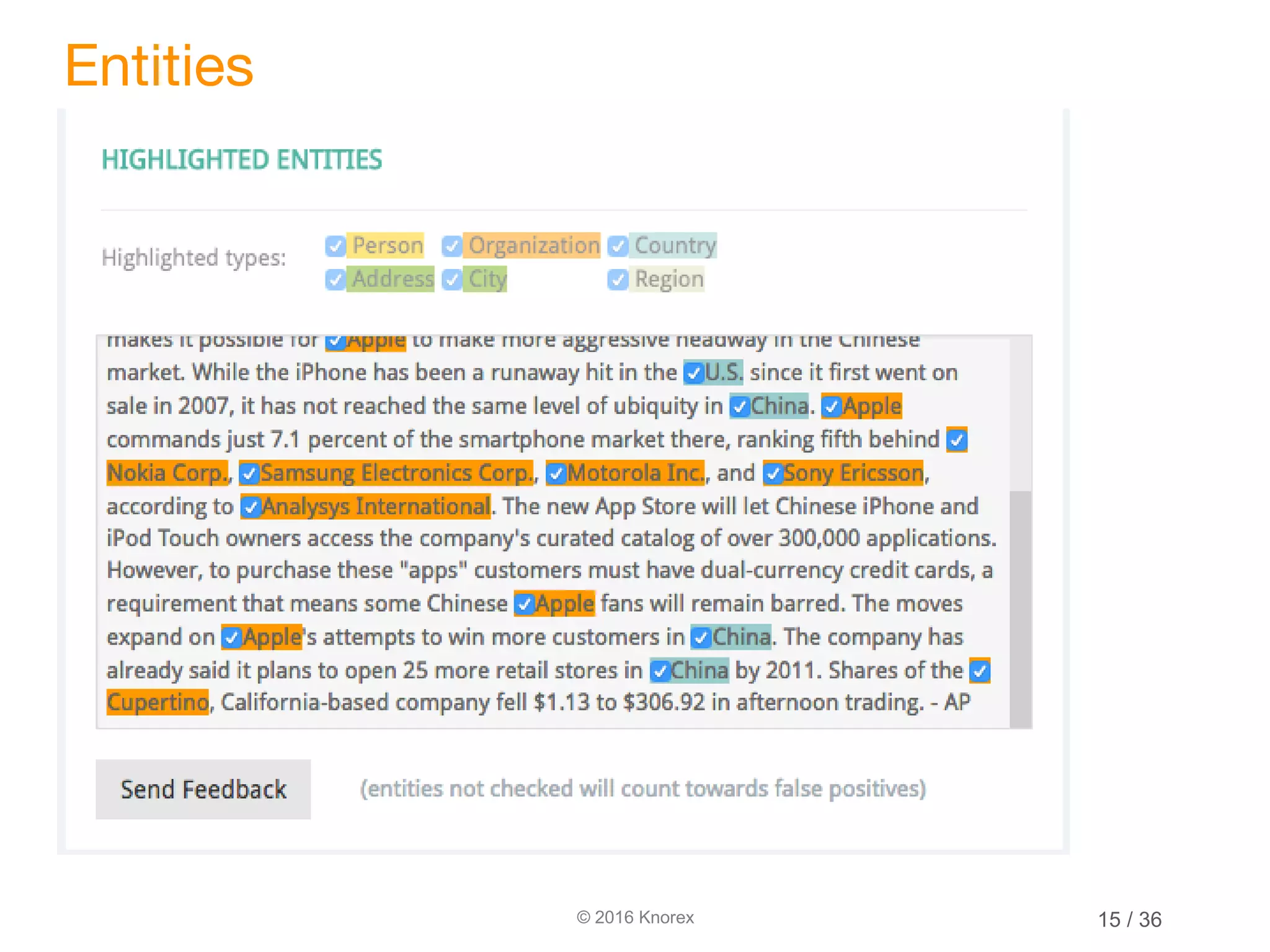
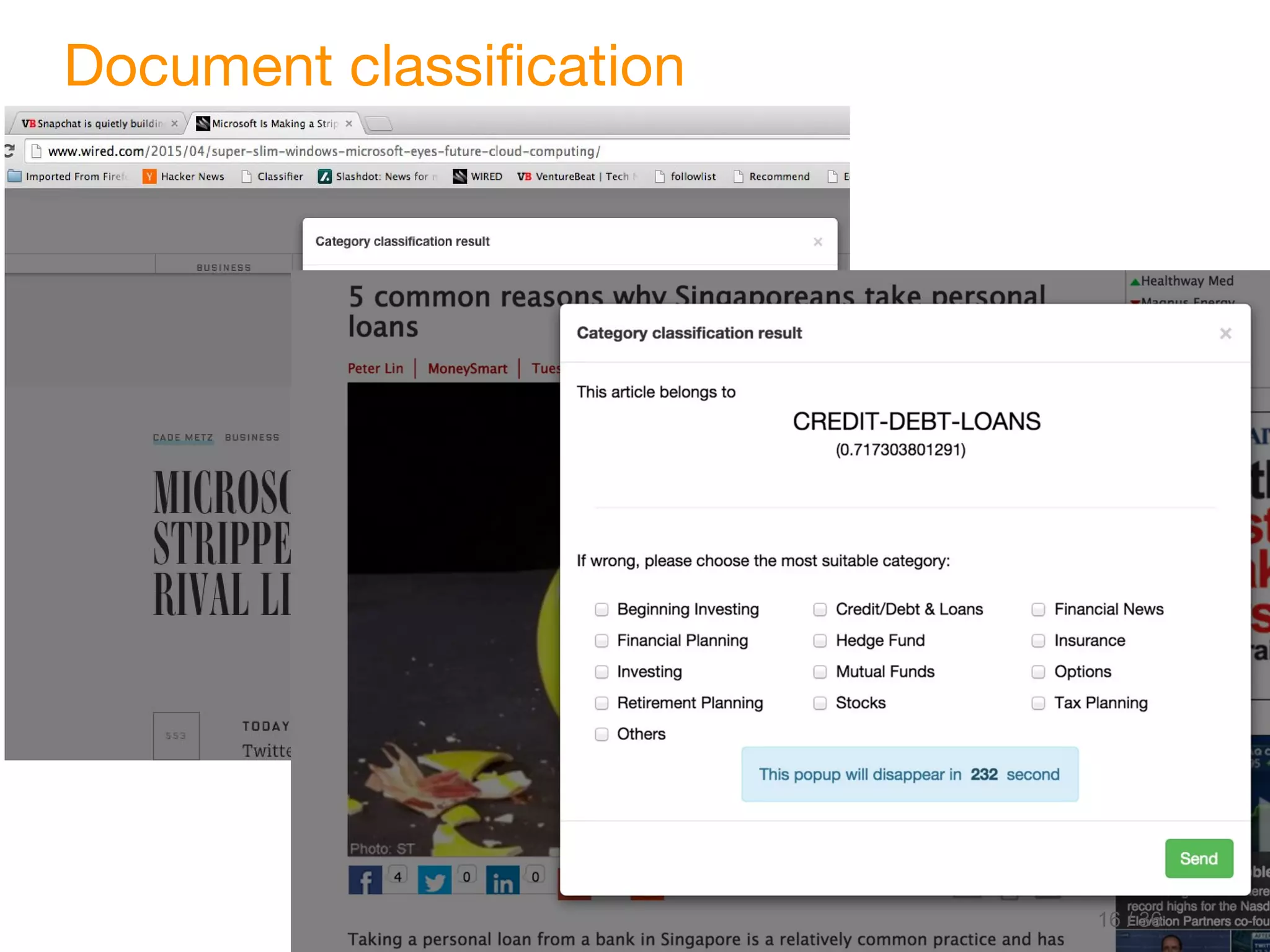
This document discusses marrying natural language processing (NLP) techniques with Elasticsearch to solve real-world search problems. It outlines the key ingredients of gathering and extracting content from data sources, preprocessing text, and modeling terms, phrases and entities. It then describes how Elasticsearch can be used for basic analysis, filtering, recommendations and deduplication. Specific NLP techniques like key phrase extraction, named entity recognition and semantic hashing are proposed to improve search quality beyond bag-of-words approaches. The document concludes with a summary of considering analysis, queries, indexing versus search tradeoffs, and paying attention to the data input step.





![© 2016 Knorex
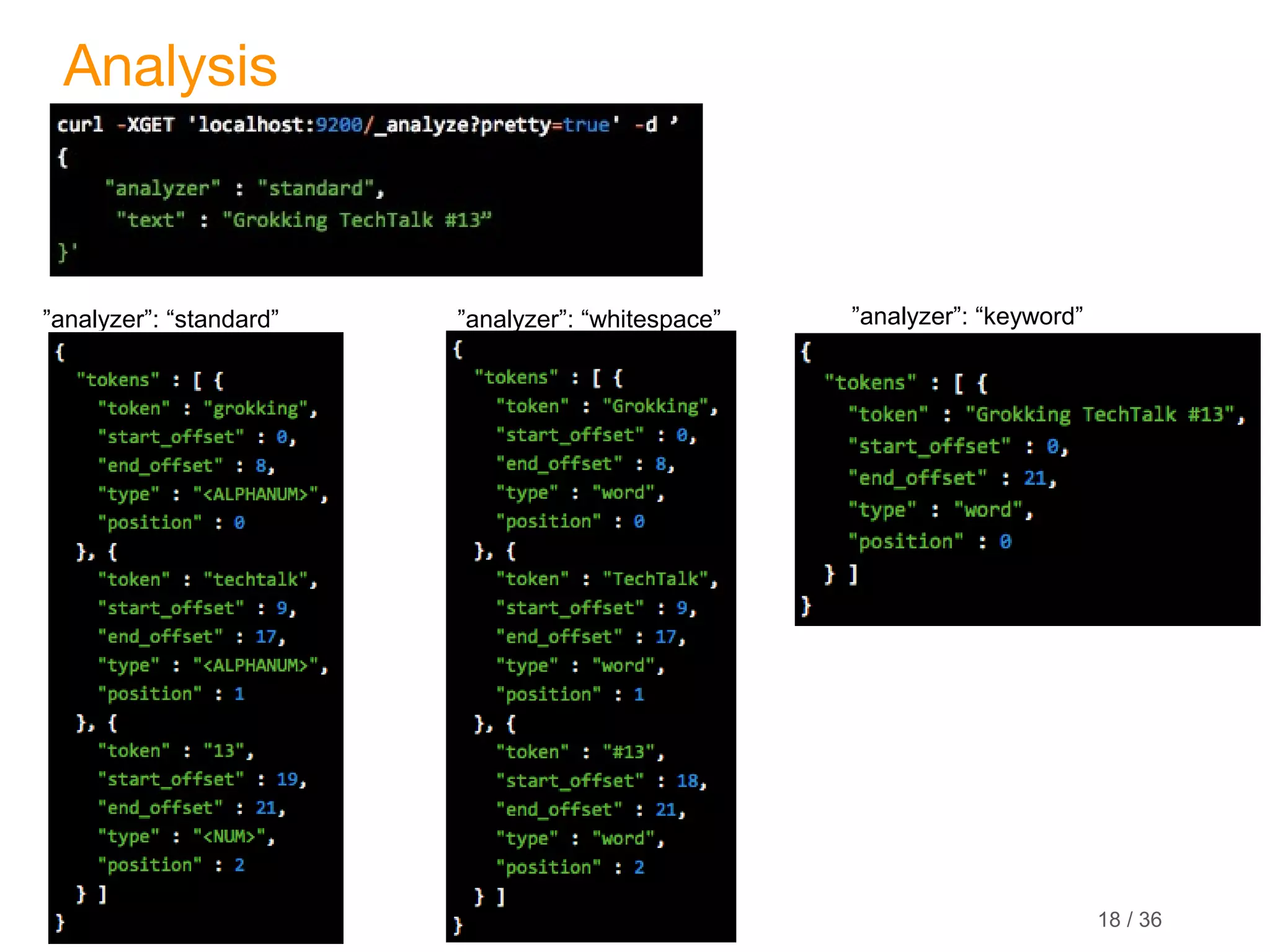
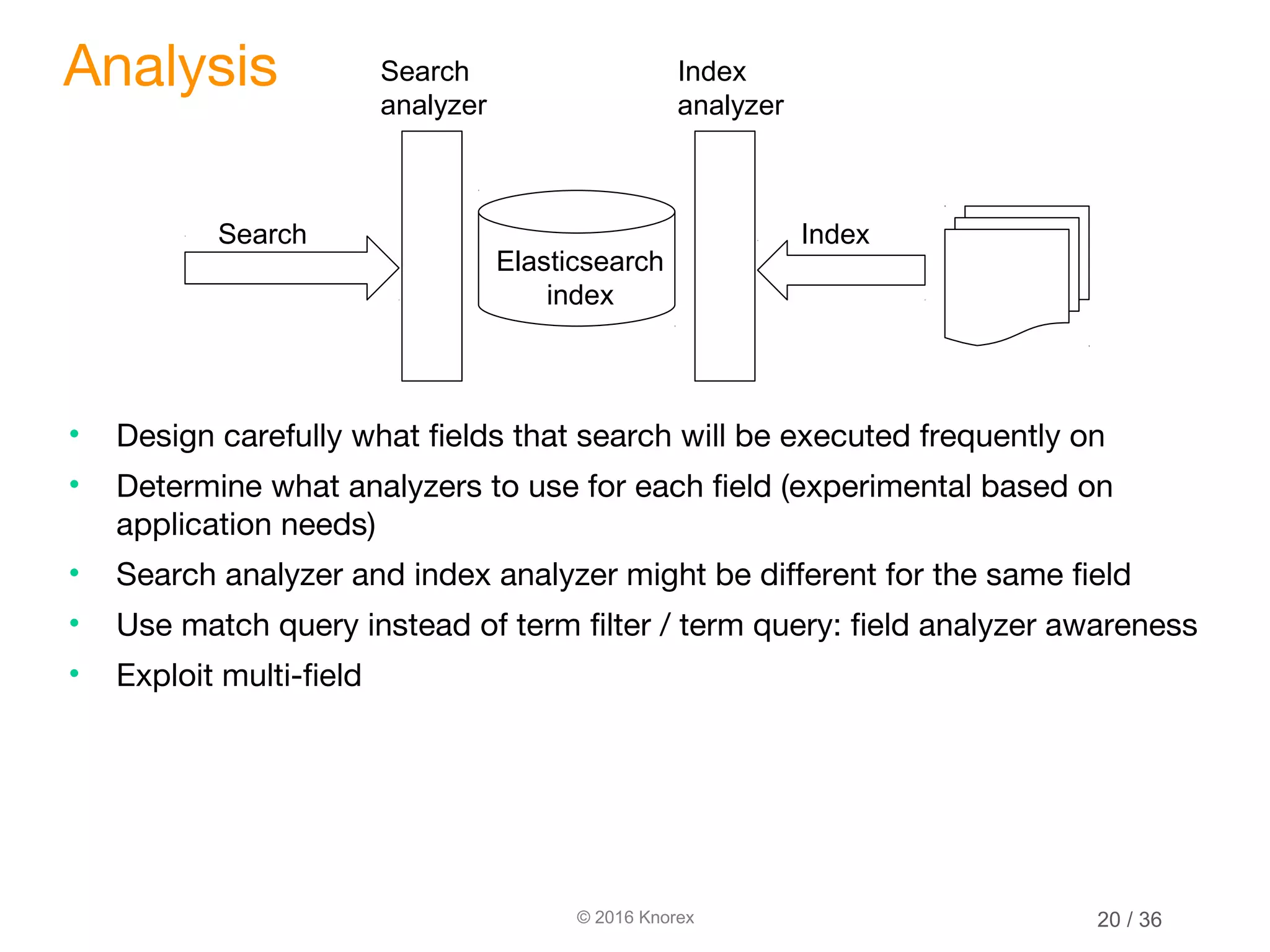
Analysis
Successful!
[“https”,
“www.facebook.com”,
”events”,
“194454270949757“]
No hits! WTH… it is not working!!!!
Default
analyzer
as-is
• url => not_analyzed / keyword analyzer
• Use match query instead of term filter /
term query: field analyzer awareness
• Custom analyzer: e.g. keyword
tokenizer + lowercase filter
19 / 36](https://image.slidesharecdn.com/phu-le-knx-25jun2016-grokking-160628133220/75/TechTalk-13-Grokking-Marrying-Elasticsearch-with-NLP-to-solve-real-world-search-problems-19-2048.jpg)




































































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)

















