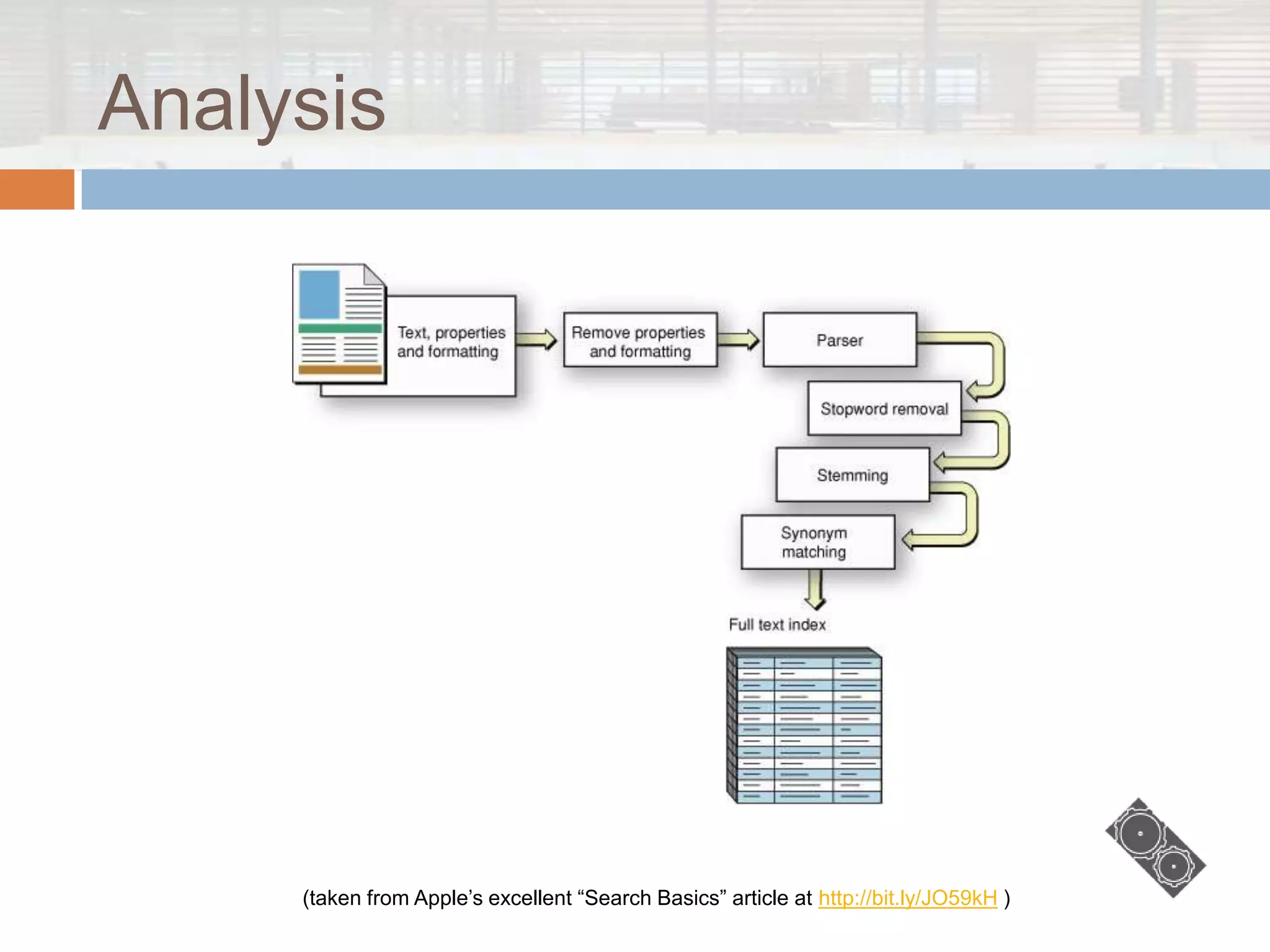
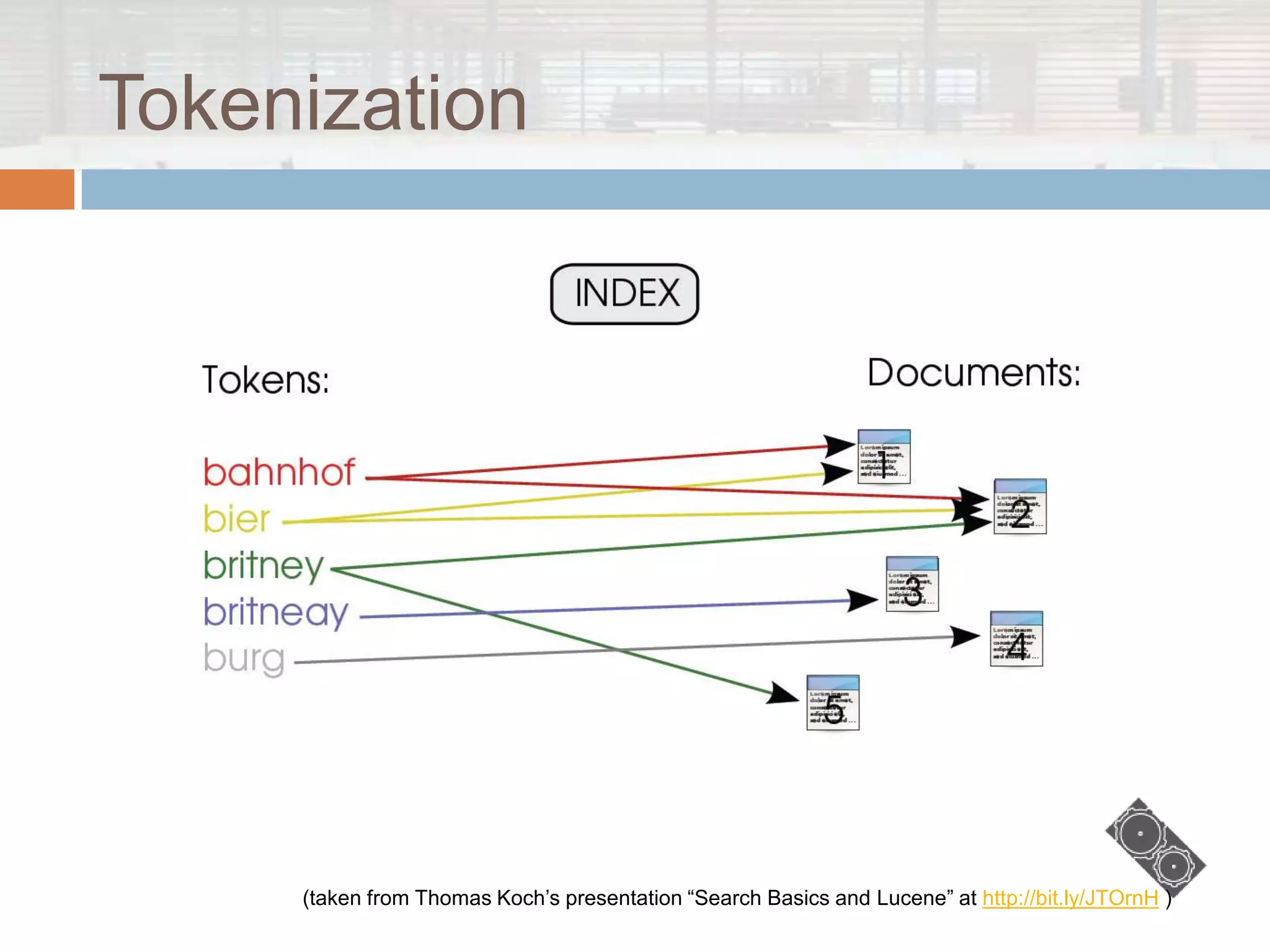
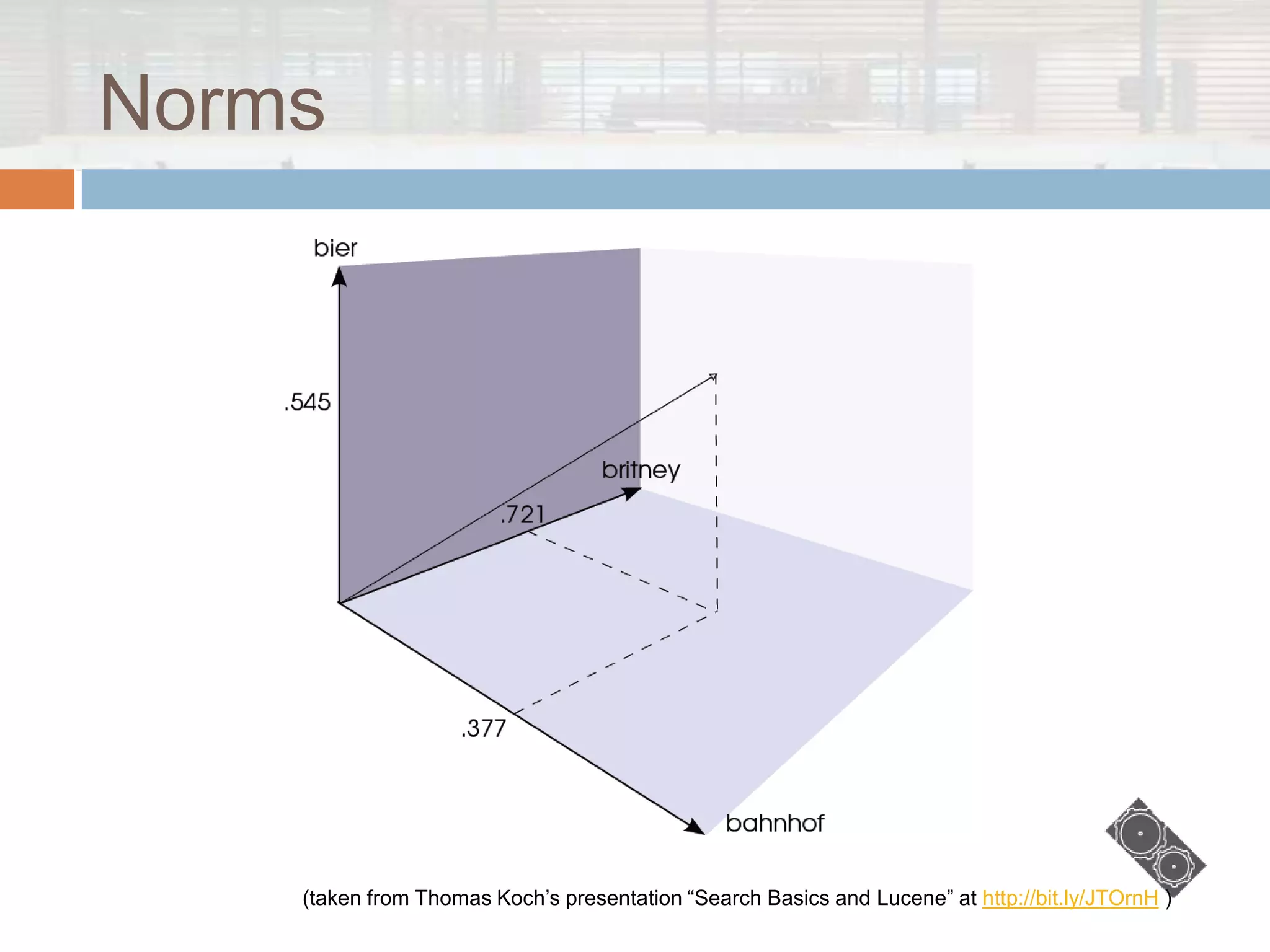
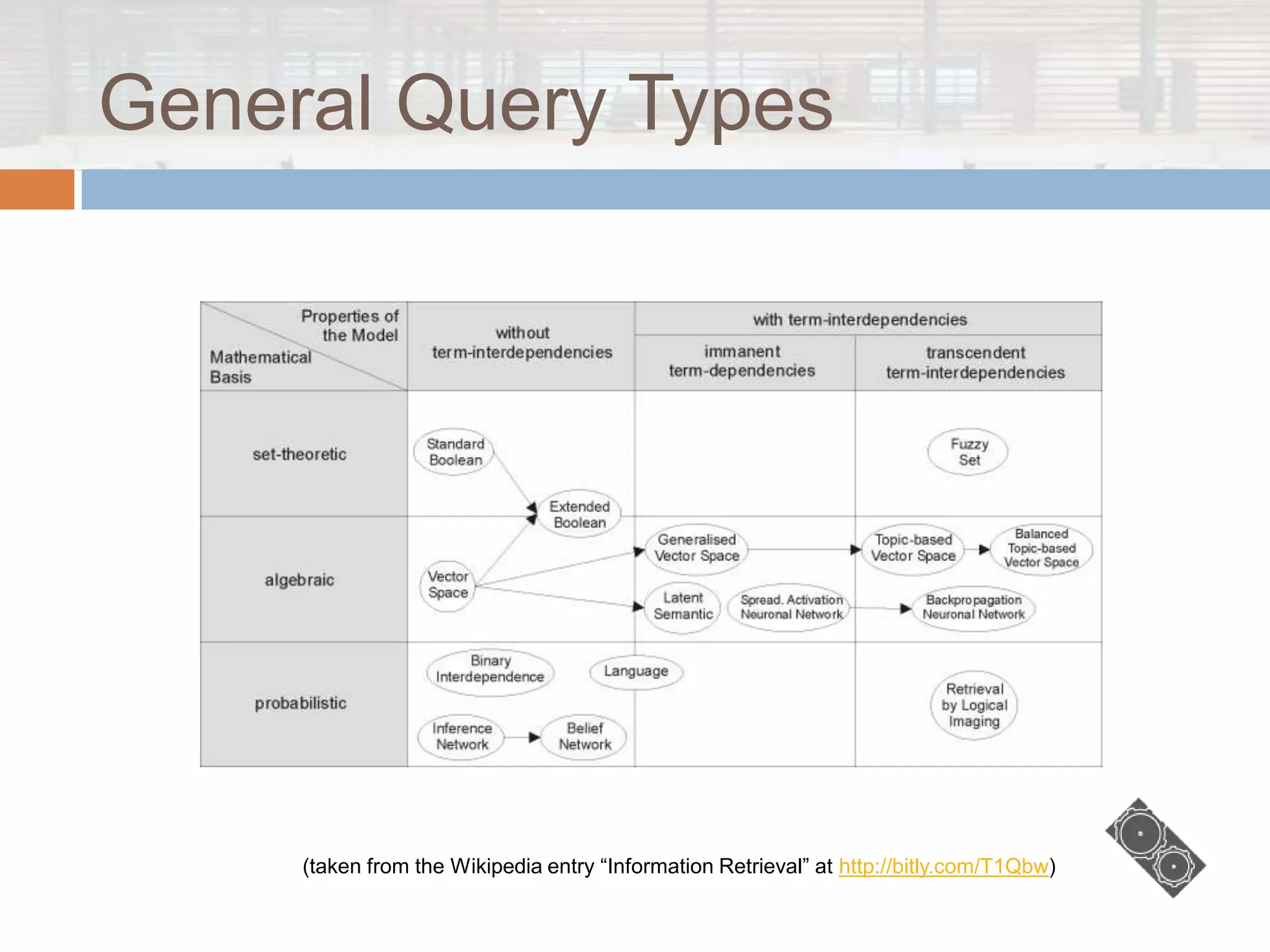
The document discusses Lucene.net, a C# port of the Apache Lucene search library, focusing on its capabilities and underlying concepts in information retrieval. It outlines the structure of indexes, querying methods, various query types, and additional contributions to enhance search functionality. Moreover, it clarifies what Lucene.net is not, emphasizing that it is not a complete information retrieval system or a web crawler.