Downloaded 22 times



![3
From 10,000 Meters
[1] http://www.openstack.org/blog/2013/11/openstack-user-survey-statistics-november-2013/
• Open Source Distributed Storage solution
• Most popular choice of distributed storage for
OpenStack
[1]
• Lots of goodies
‒ Distributed Object Storage
‒ Redundancy
‒ Efficient Scale-Out
‒ Can be built on commodity hardware
‒ Lower operational cost](https://image.slidesharecdn.com/01-suse-150406142721-conversion-gate01/85/Ceph-Day-Amsterdam-2015-Measuring-and-predicting-performance-of-Ceph-clusters-3-320.jpg)
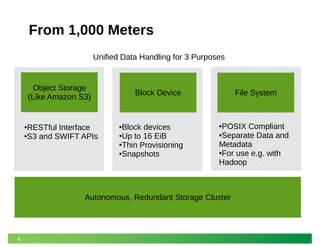
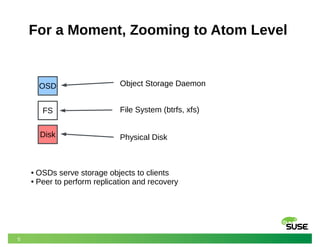
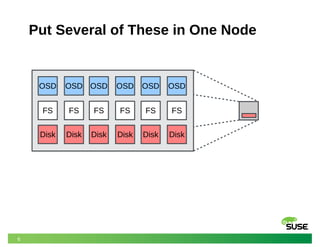

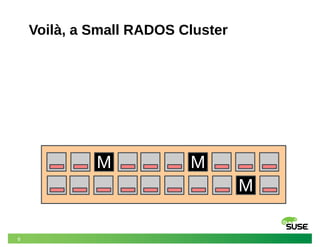





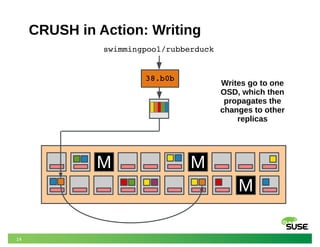
























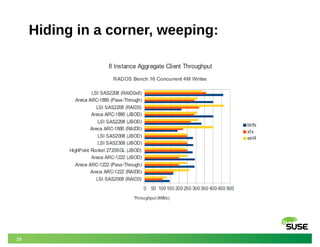

















This document discusses modeling and predicting performance in Ceph distributed storage systems. It provides an overview of Ceph, including its object storage, block storage, and file system capabilities. It then discusses various factors that impact Ceph performance, such as network configuration, storage node hardware, number of disks, caching, redundancy settings, and placement groups. The document notes there are many configuration choices and tradeoffs to consider when designing a Ceph cluster to meet performance requirements.
























![[B4]deview 2012-hdfs](https://cdn.slidesharecdn.com/ss_thumbnails/b4deview-2012-hdfs-120919013559-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)












































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)














