Downloaded 345 times







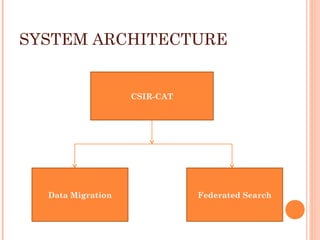



















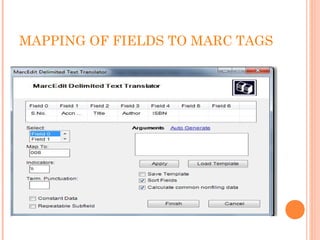
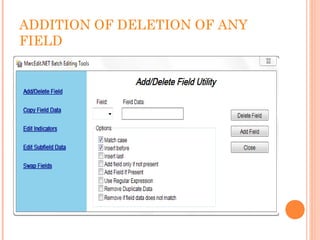
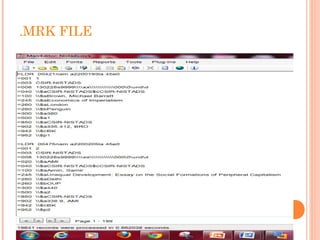

























This document describes the process of migrating data from the proprietary Libsys ILMS to the open source Koha ILMS at the National Institute of Science Communication and Information Resources (NISCAIR) library in India. Key steps included: 1) Generating reports from Libsys and converting them to Excel files 2) Cleaning the data by removing blanks and consolidating multi-line fields 3) Converting the Excel files to MARC format files 4) Importing the MARC files into Koha 5) Customizing Koha's interface, administration tools, and OPAC to meet NISCAIR's needs.










































































