Download to read offline



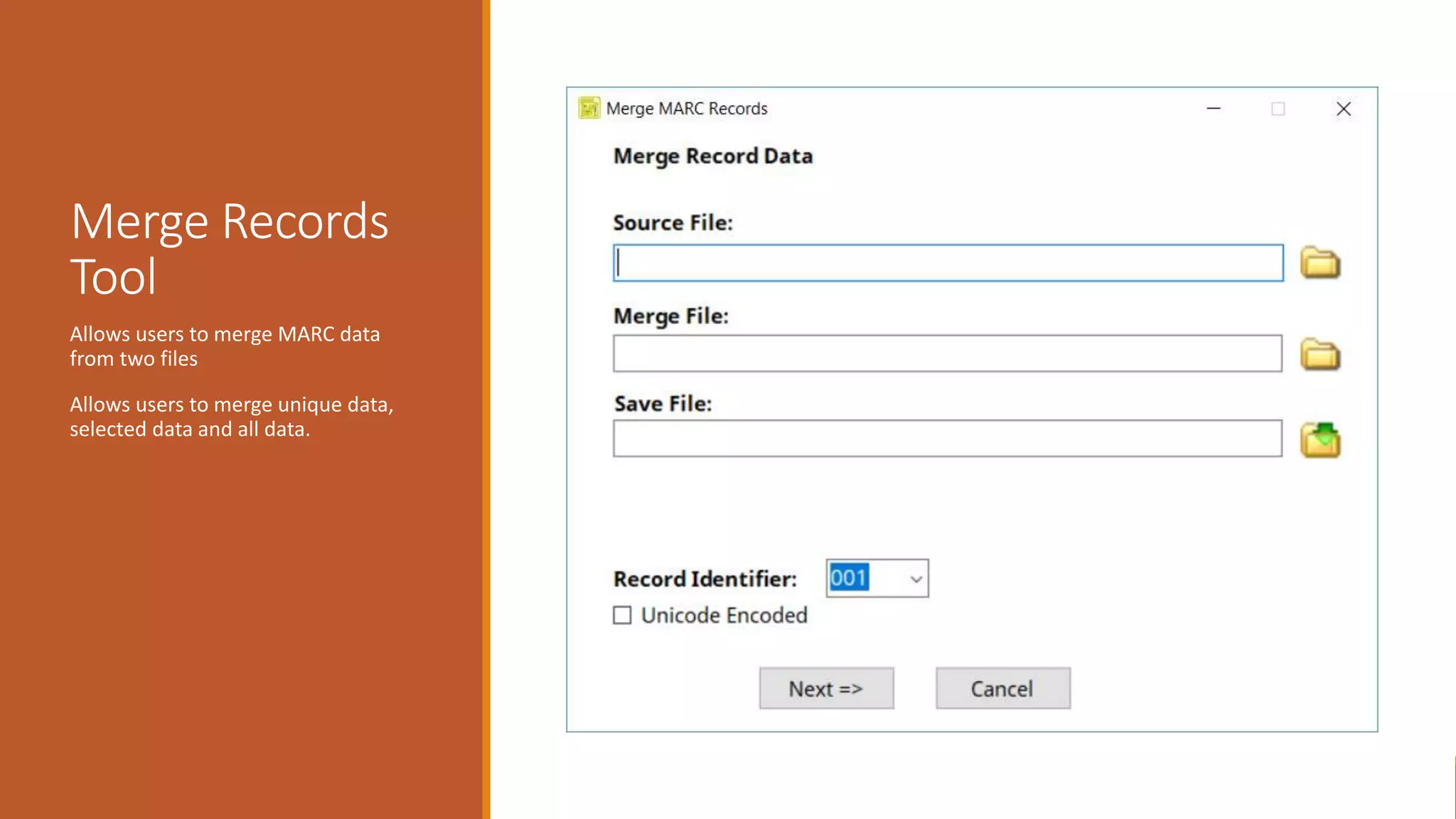

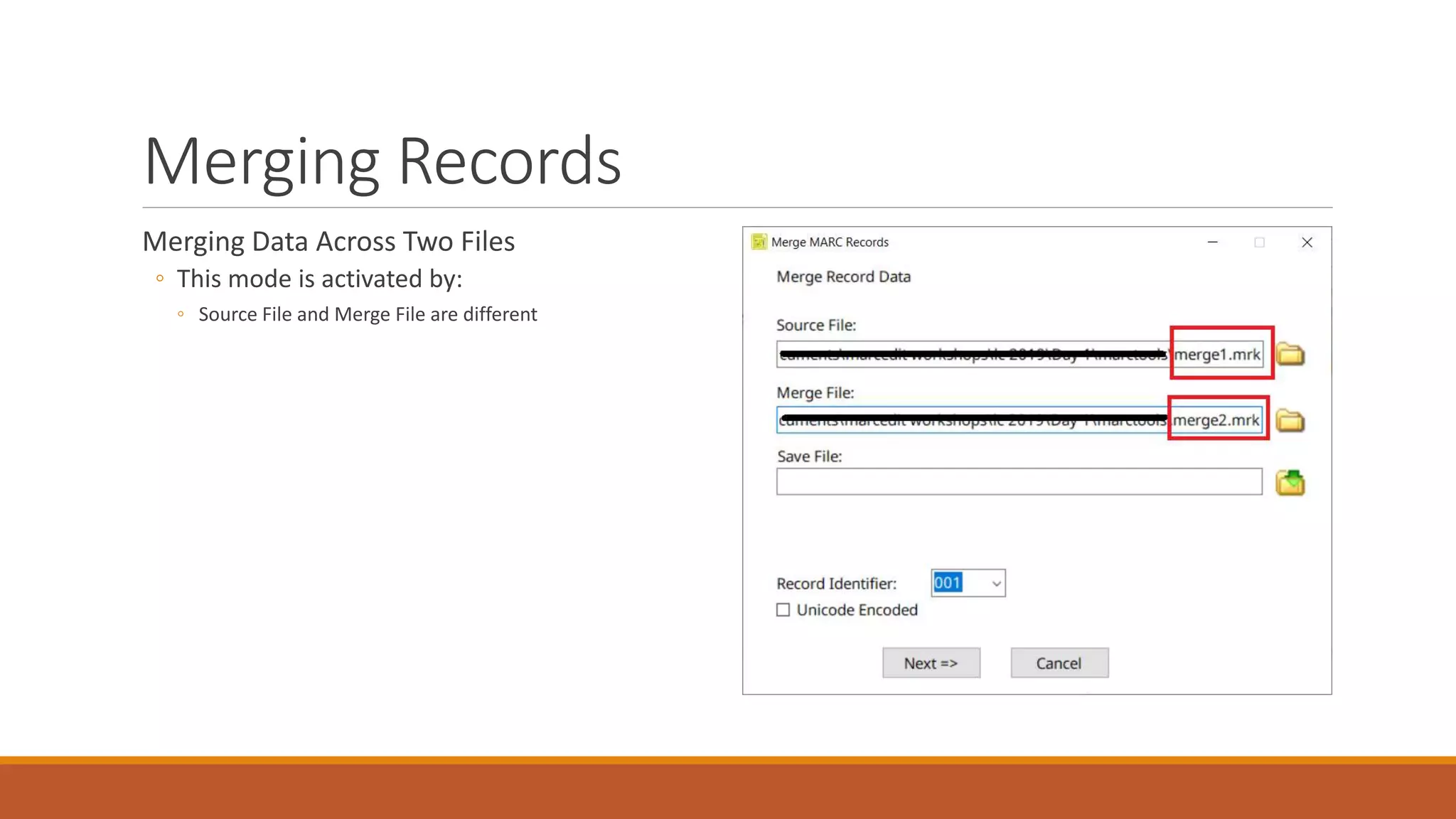
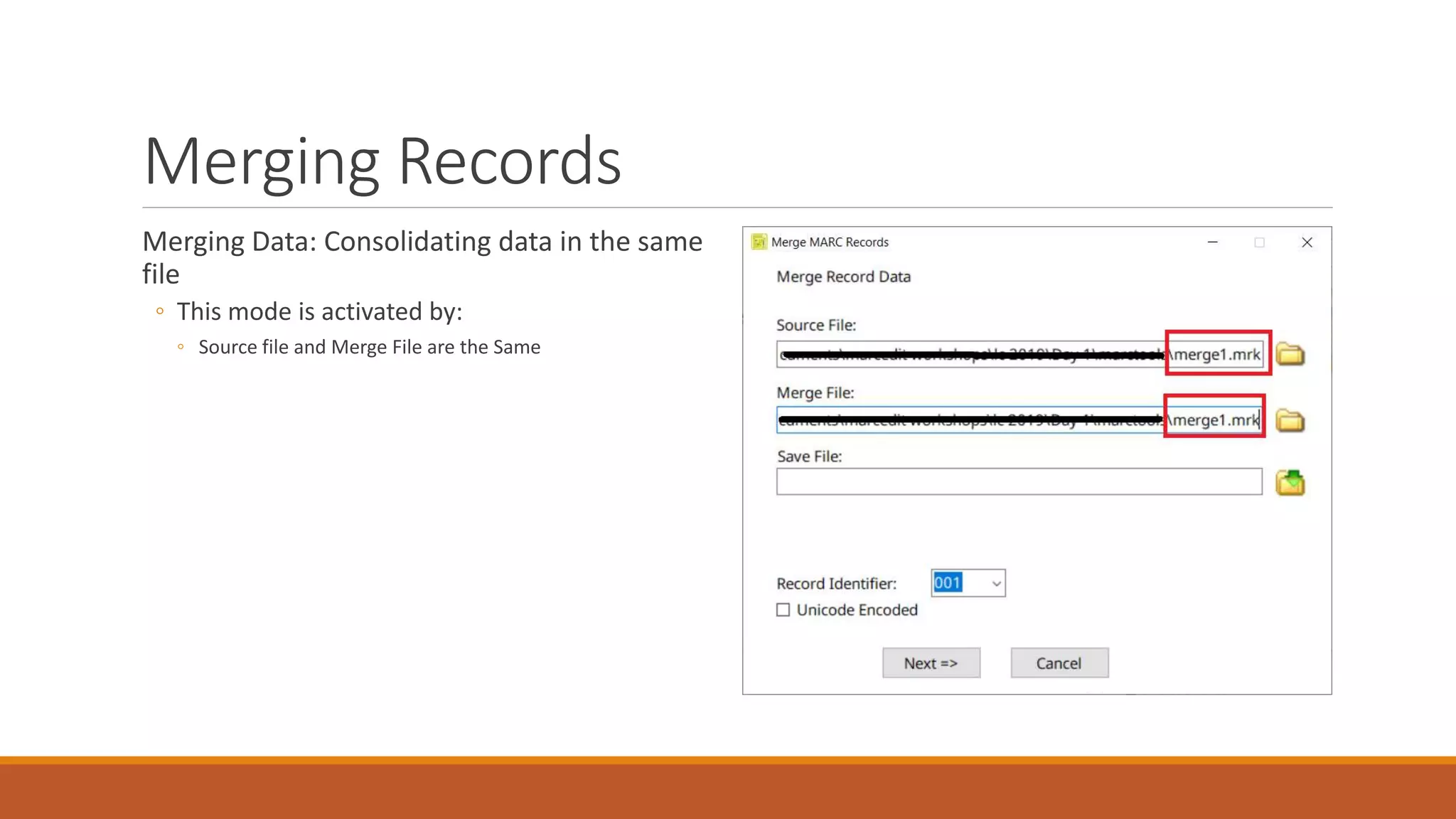
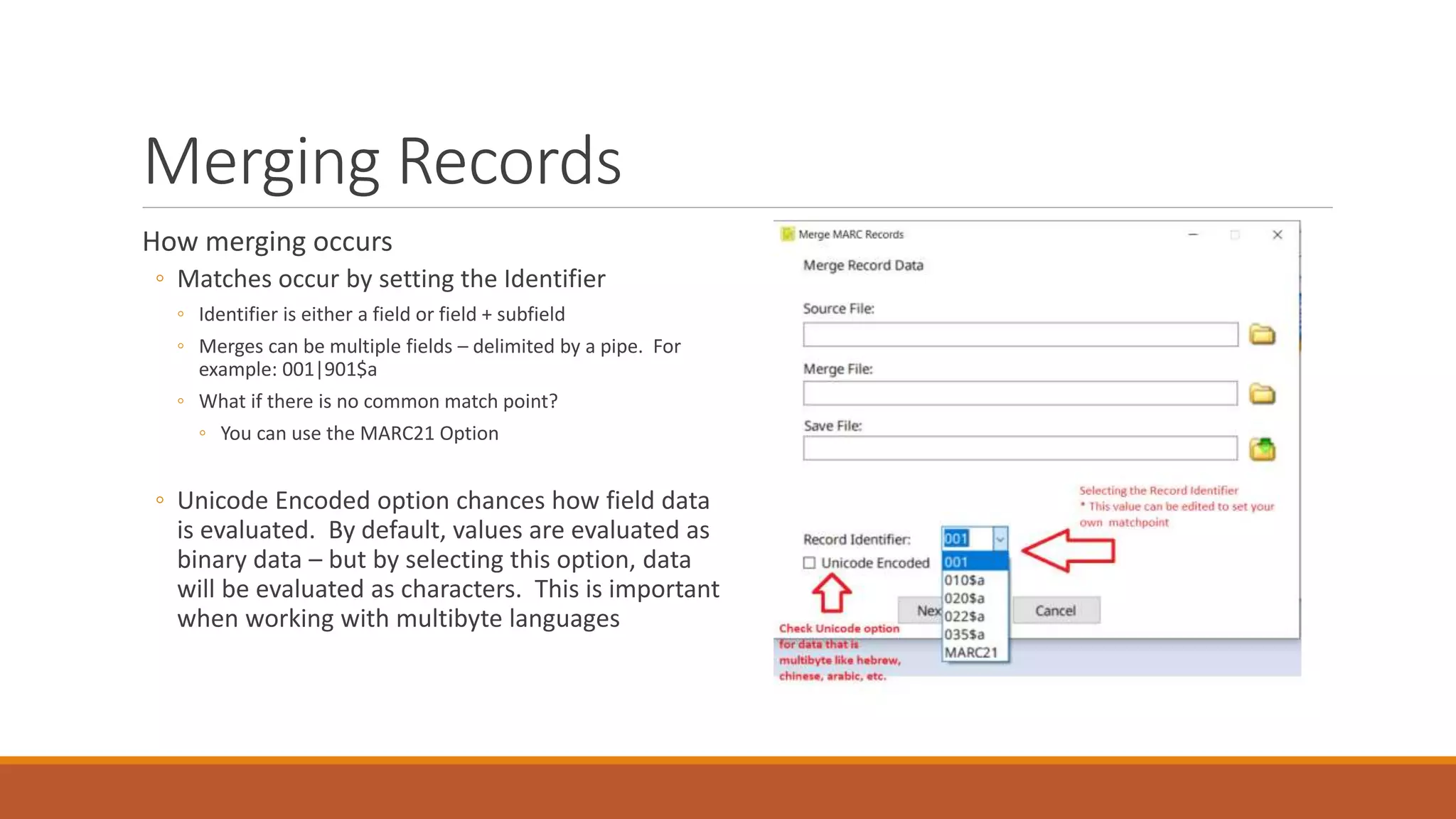



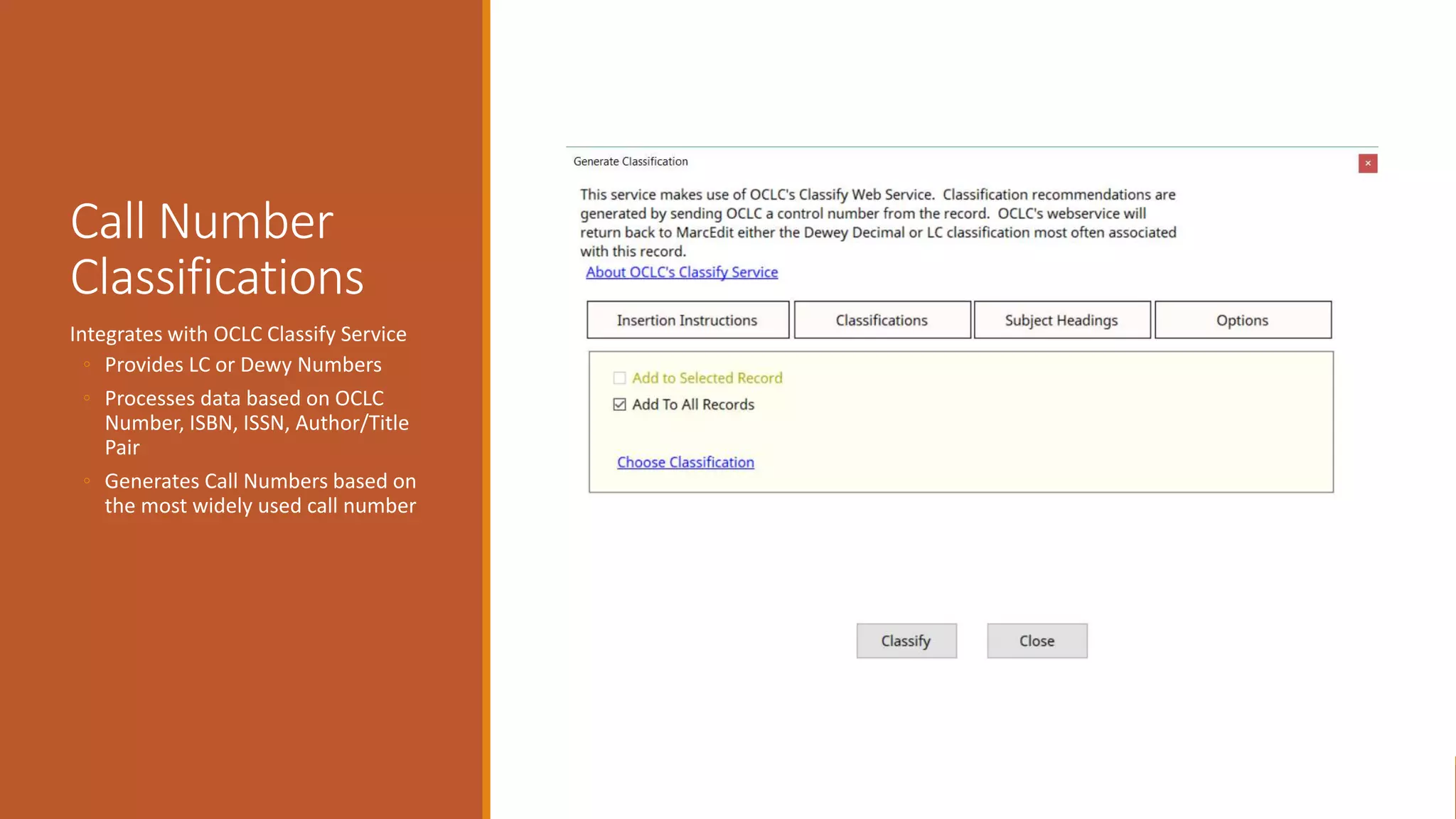
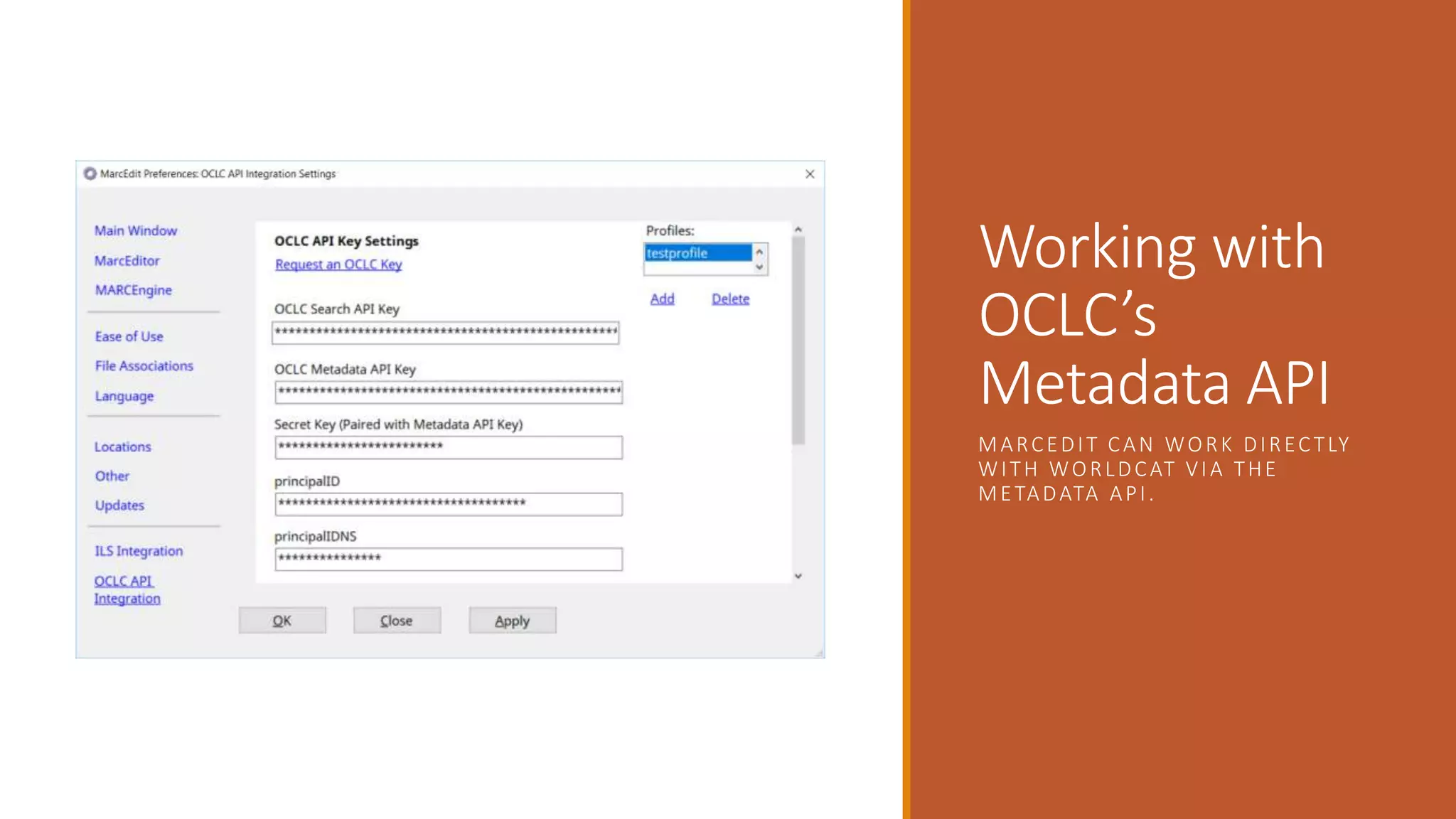
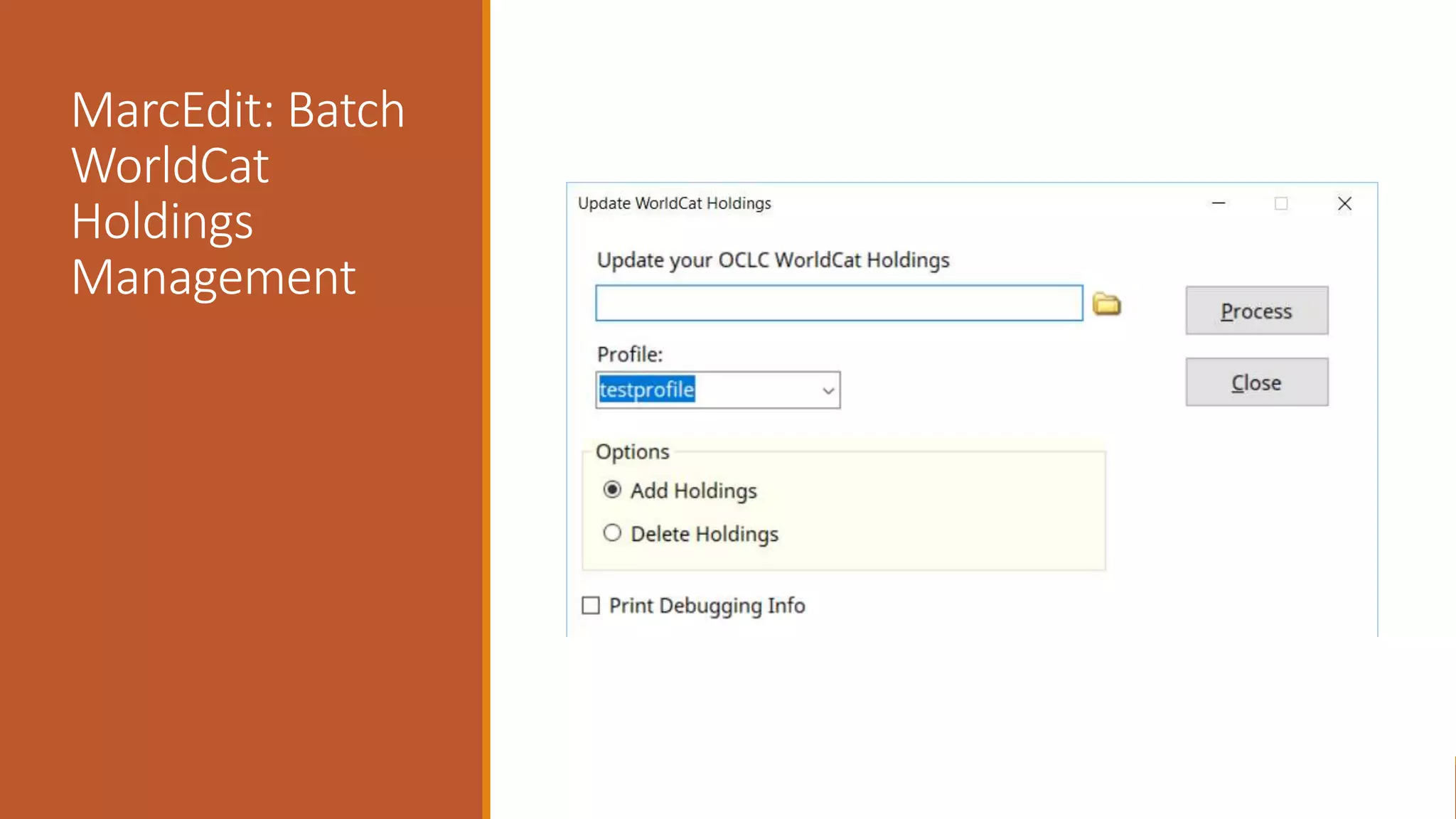
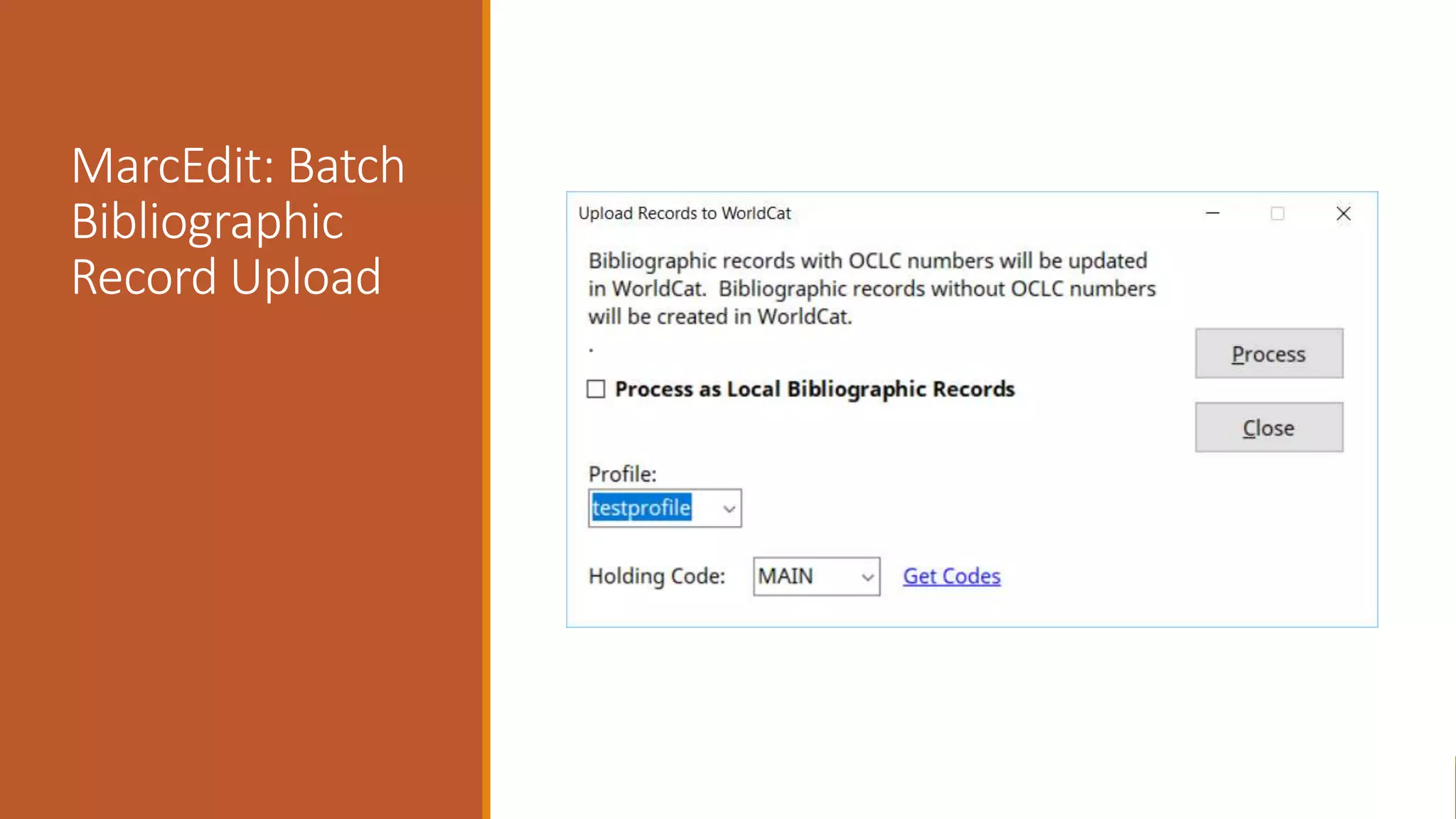
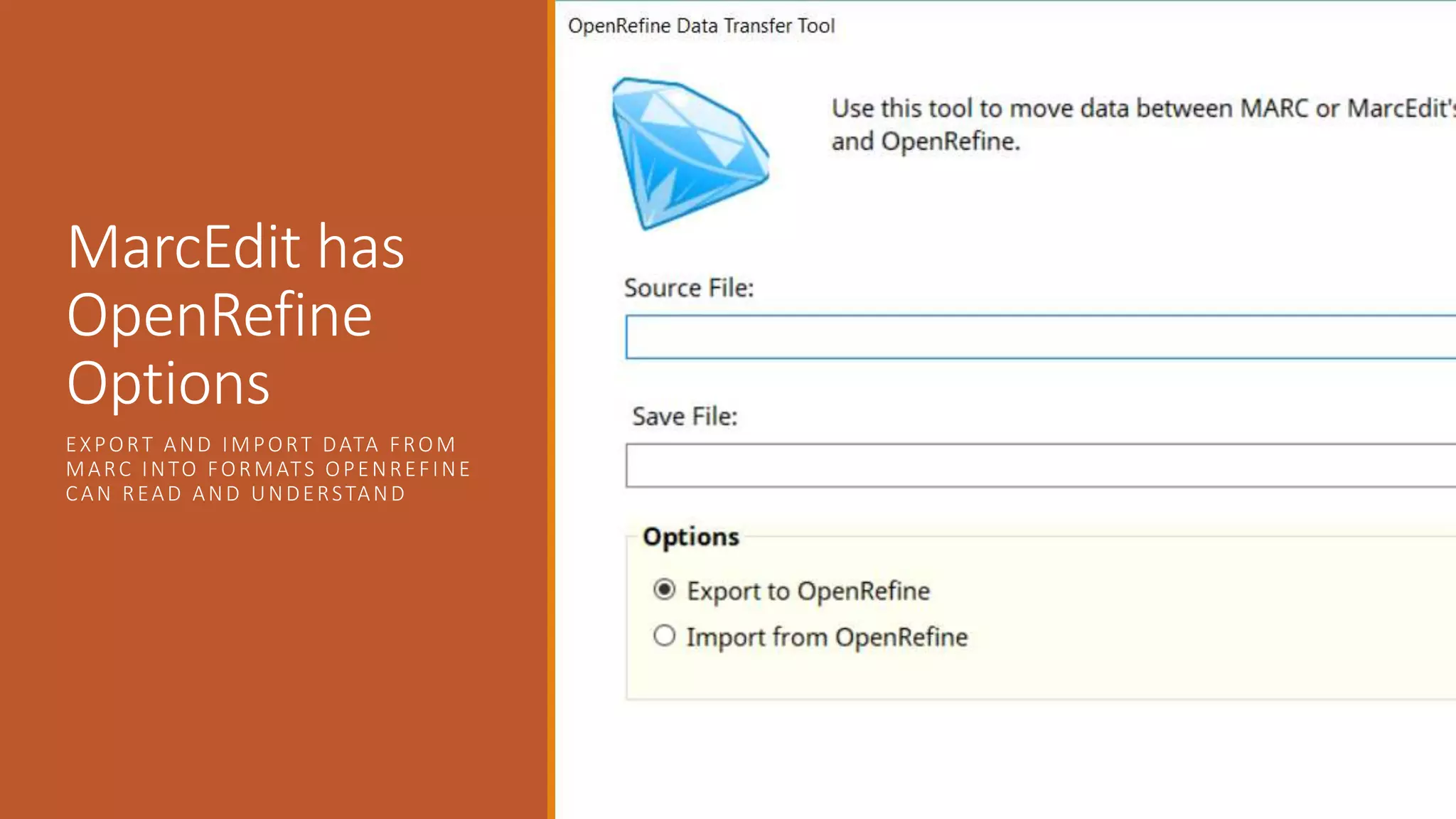


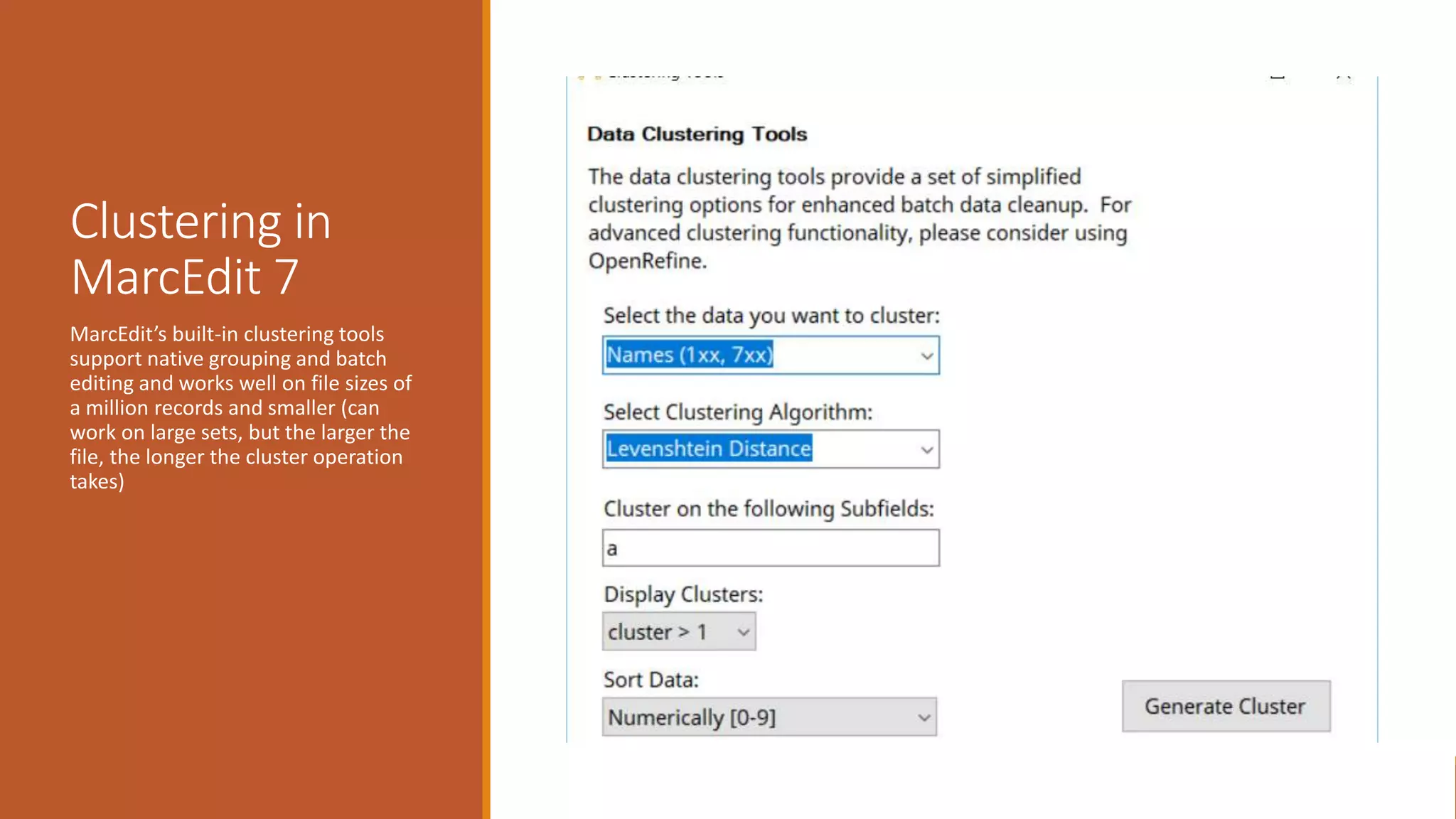

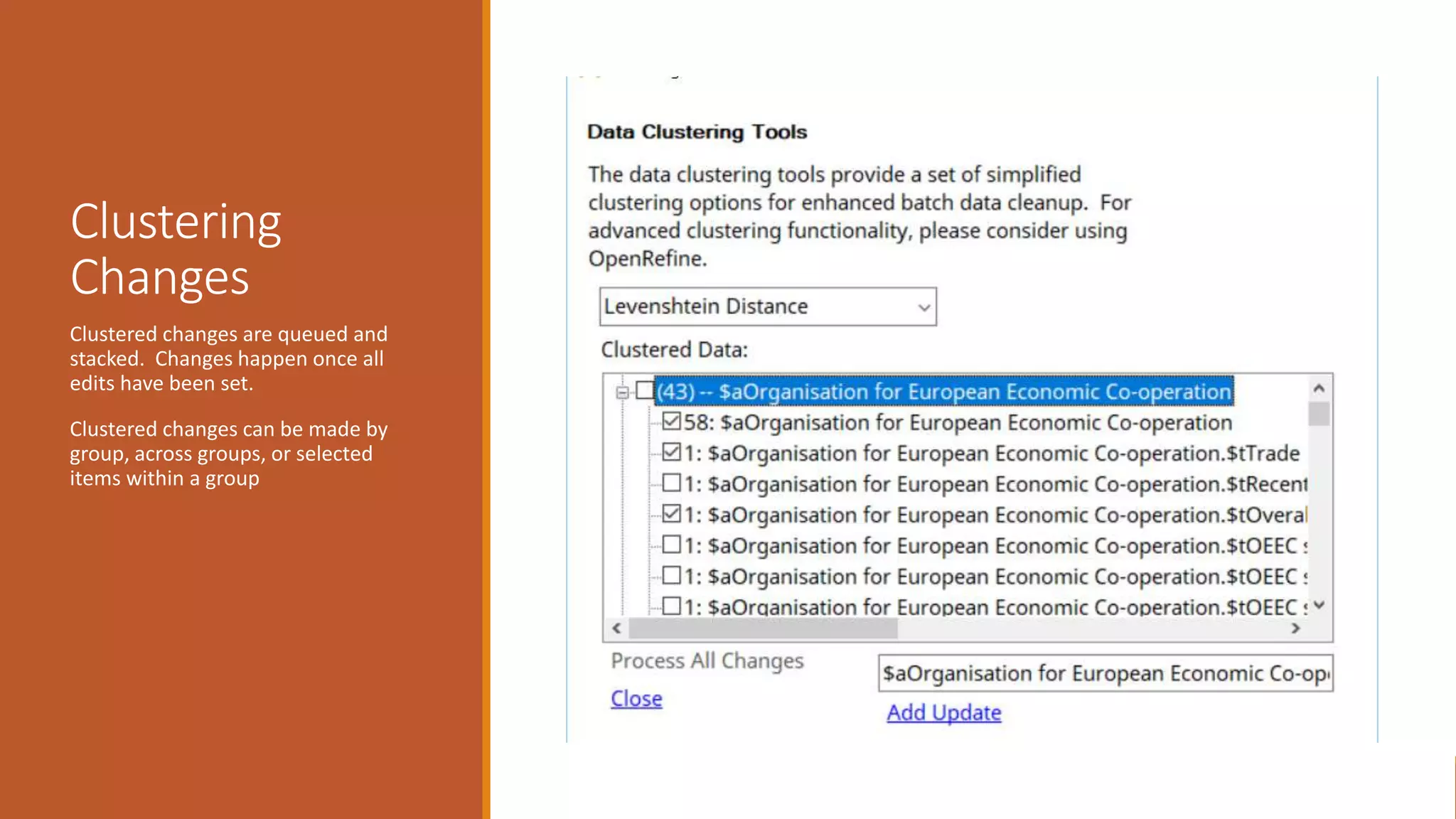



The document discusses merging, clustering, and integration processes for MARC data, focusing on tools like MarcEdit and OpenRefine. It outlines functionalities for merging records from different files, managing bibliographic data via APIs, and clustering options tailored for library formats. Additionally, it highlights the differences between using MarcEdit and OpenRefine for handling MARC data, emphasizing the advantages of MarcEdit for catalogers.



































































