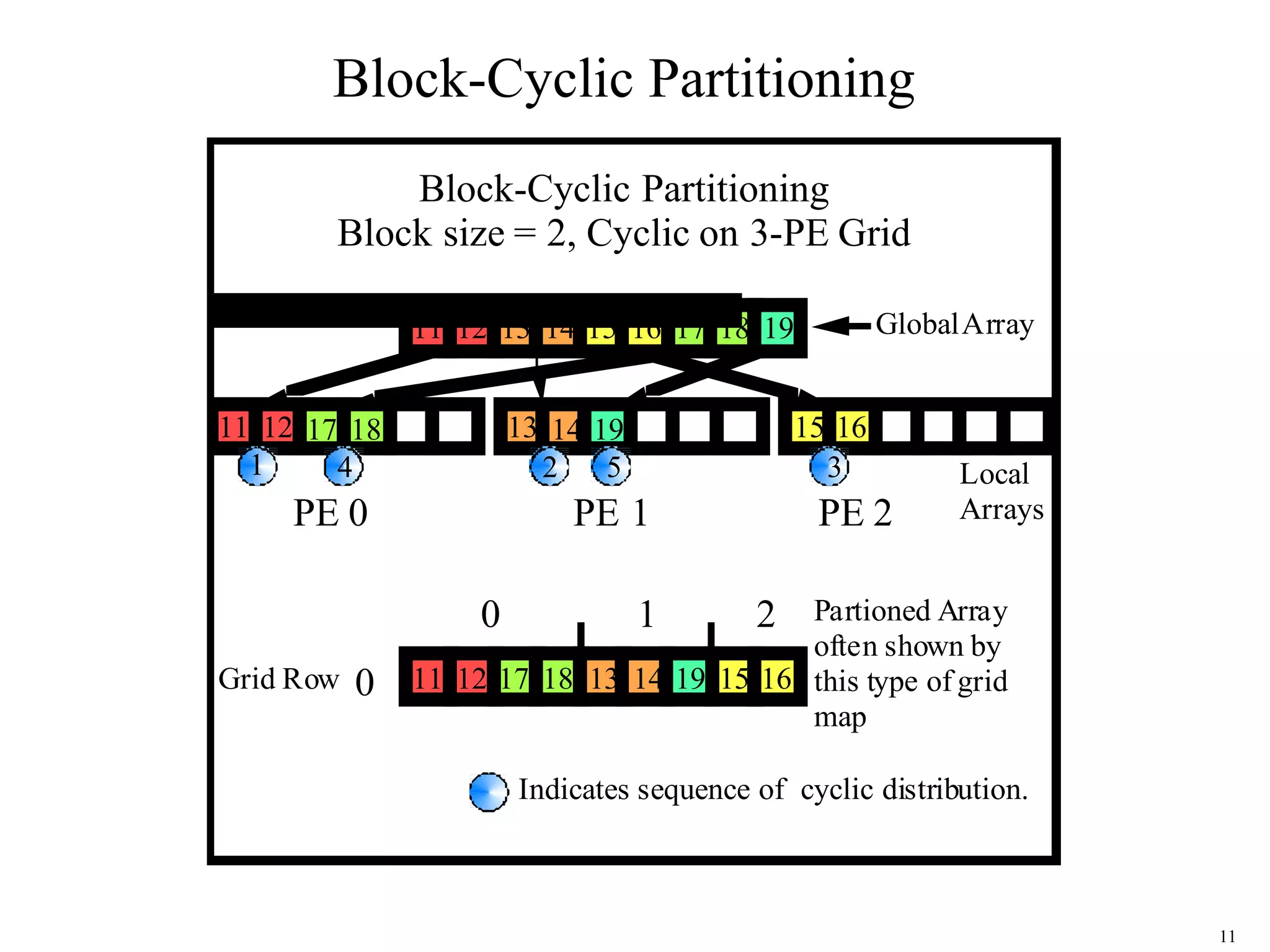
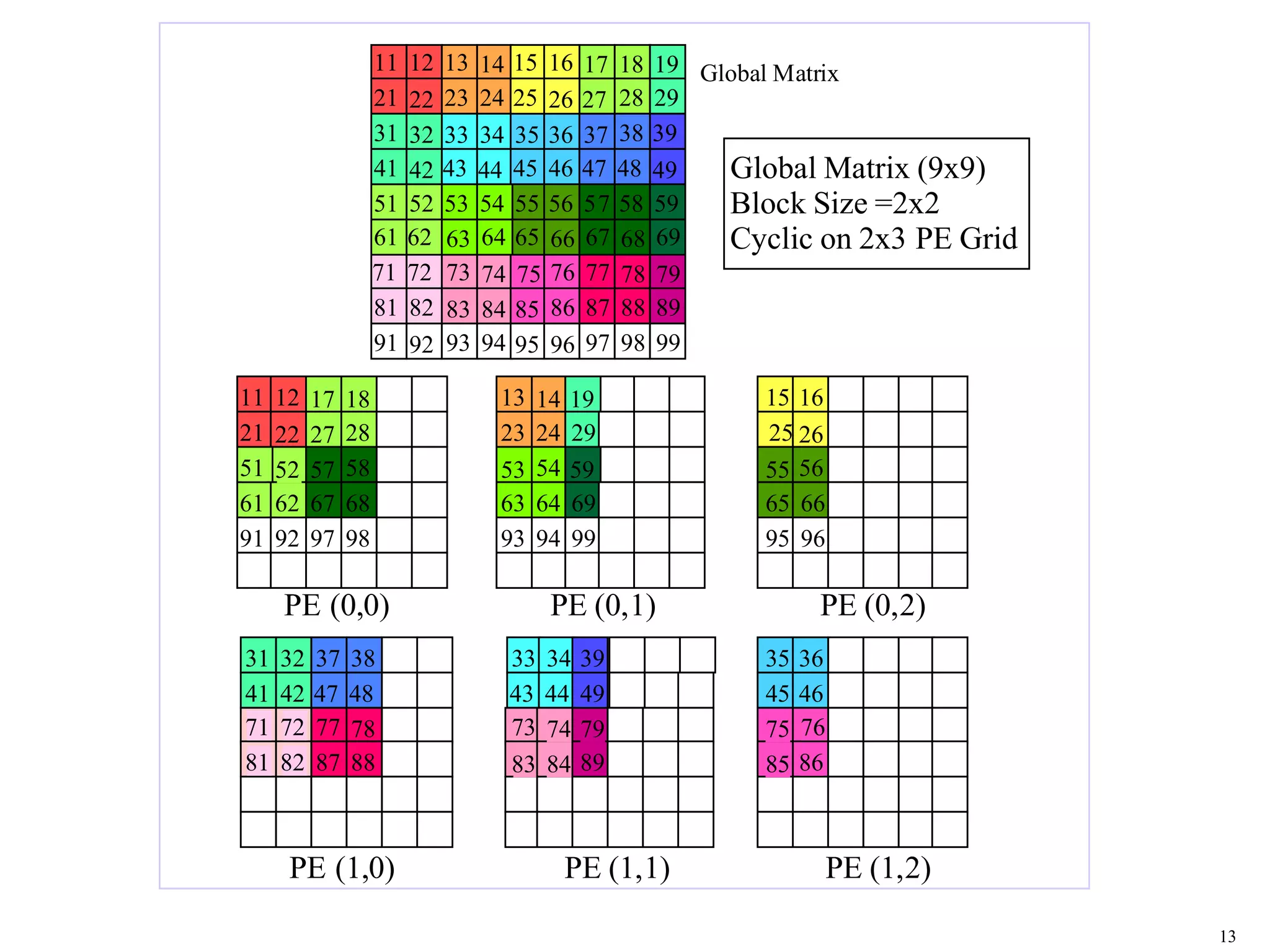
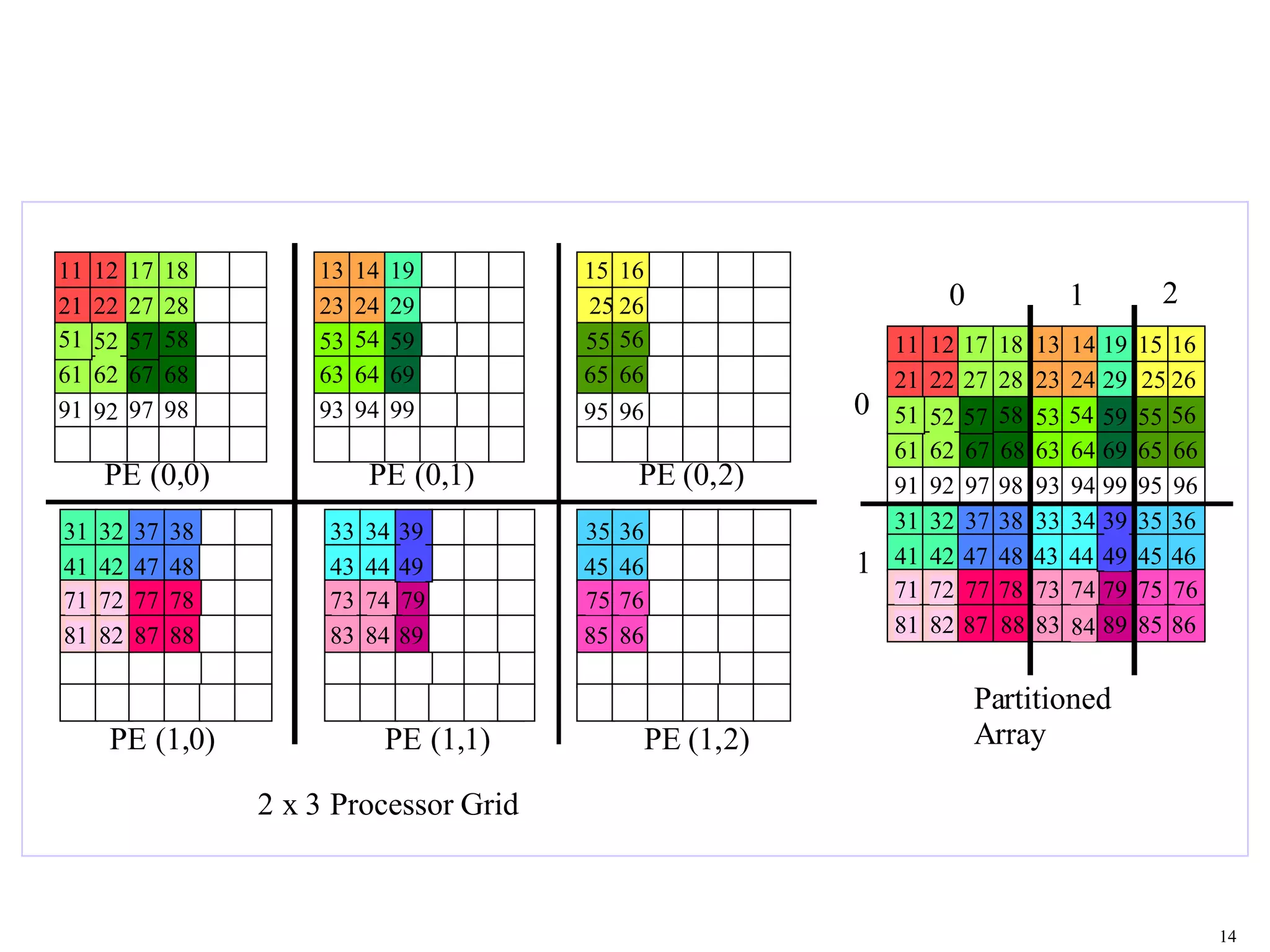
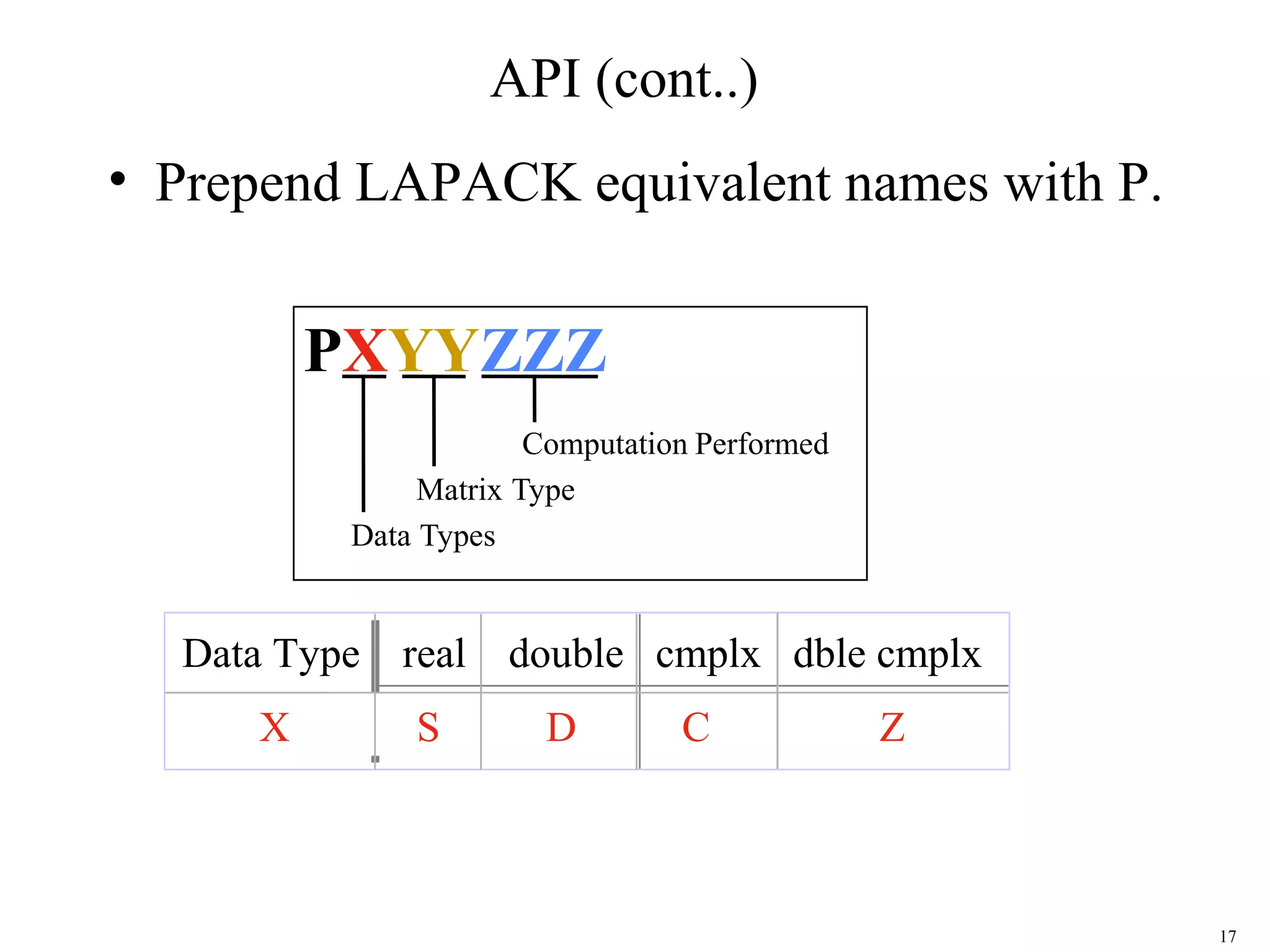
This document provides an introduction and overview of ScaLAPACK, a library of linear algebra routines for solving dense linear algebra problems in parallel. ScaLAPACK relies on BLAS, LAPACK, BLACS, and PBLAS to perform operations on dense matrices distributed across multiple processors using a 2D block cyclic distribution. Example code is provided to initialize the processor grid with BLACS, distribute a matrix and vector among processes, and solve a system of linear equations using ScaLAPACK routines.