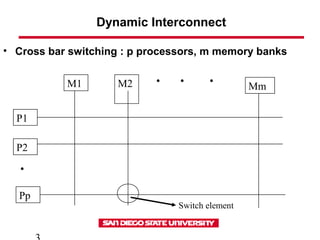
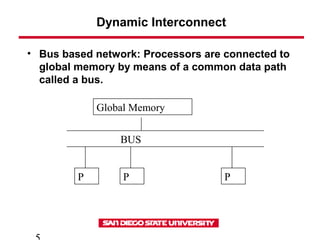
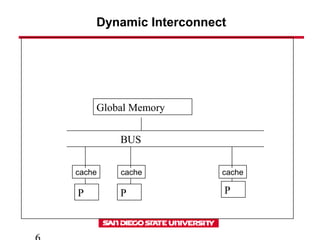
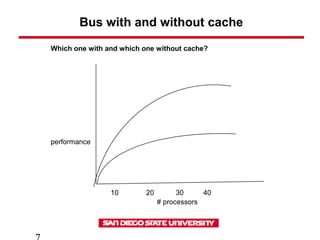
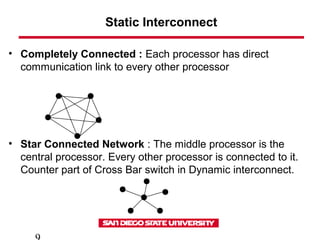
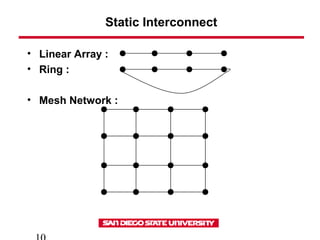
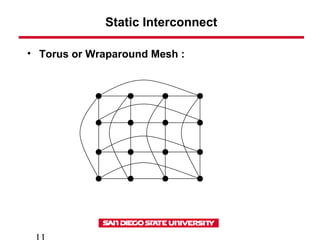
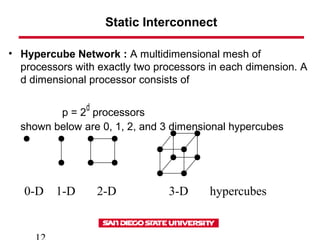
This document discusses various types of interconnect networks that can be used to connect processors and memory in parallel computers. It describes dynamic interconnects like crossbar switches and bus-based networks that are commonly used for shared memory systems. It also describes static interconnects like completely connected, star connected, linear arrays, rings, meshes, torus and hypercubes typically used for message passing systems. It provides details on different properties of these networks like diameter, connectivity, bisection width etc. It also discusses performance modeling and sources of overhead in parallel systems.