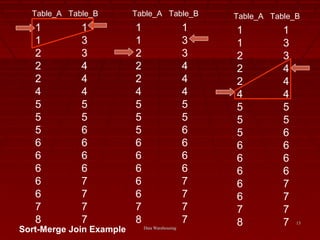
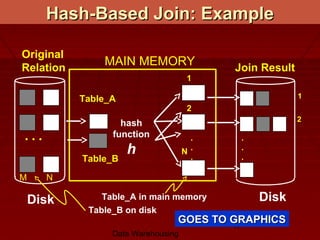
This document discusses different techniques for performing joins in data warehousing, including nested loop joins, sort-merge joins, and hash joins. It provides code examples and diagrams to illustrate how each type of join works. Specifically, it explains that nested loop joins examine each row in one table to find matching rows in the other table, while sort-merge joins first sort both tables on the join key before merging to find matches. Hash joins hash one table and probe it with the other to identify matches. The document also discusses factors that affect the performance of each join technique, such as table order and skew.