Download as PDF, PPTX





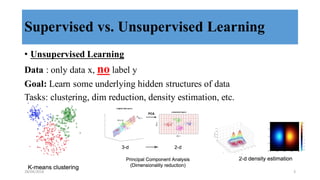



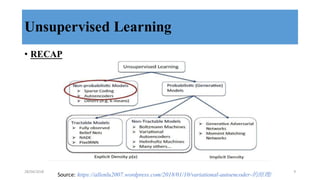


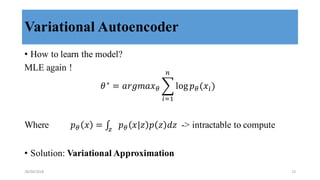



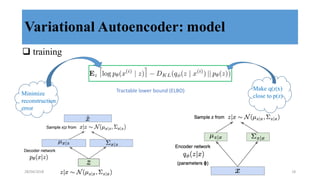
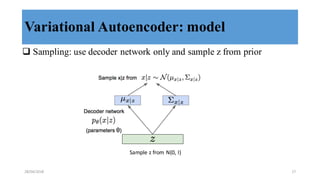





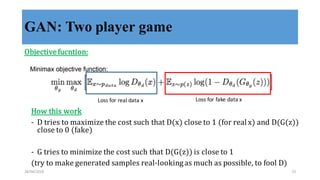
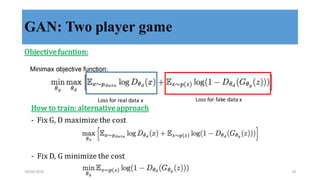











This document discusses generative adversarial networks (GANs) and their applications. It begins with an overview of generative models including variational autoencoders and GANs. GANs use two neural networks, a generator and discriminator, that compete against each other in a game theoretic framework. The generator learns to generate fake samples to fool the discriminator, while the discriminator learns to distinguish real and fake samples. Applications discussed include image-to-image translation using conditional GANs to map images from one domain to another, and text-to-image translation using GANs to generate images from text descriptions.











































































