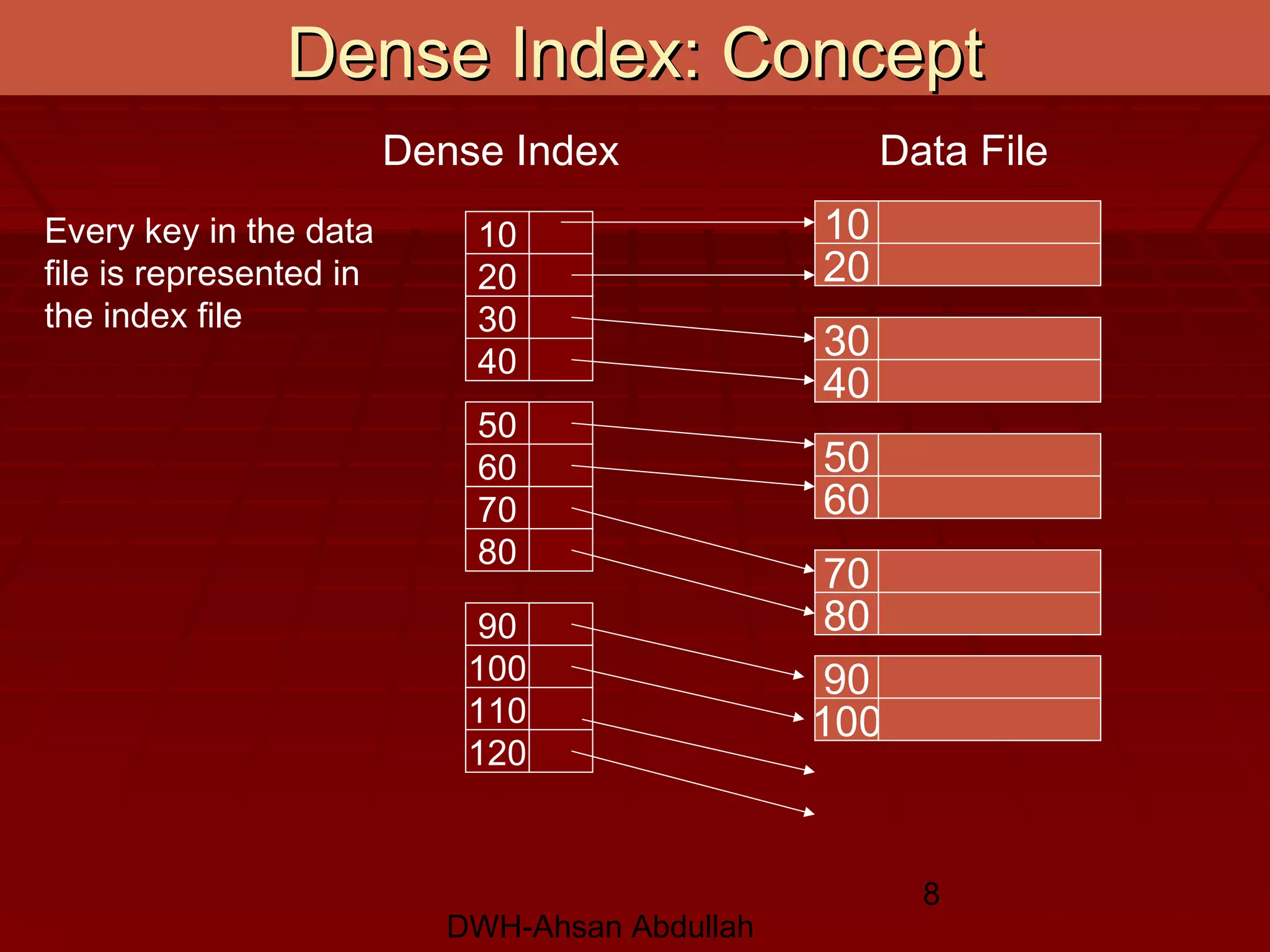
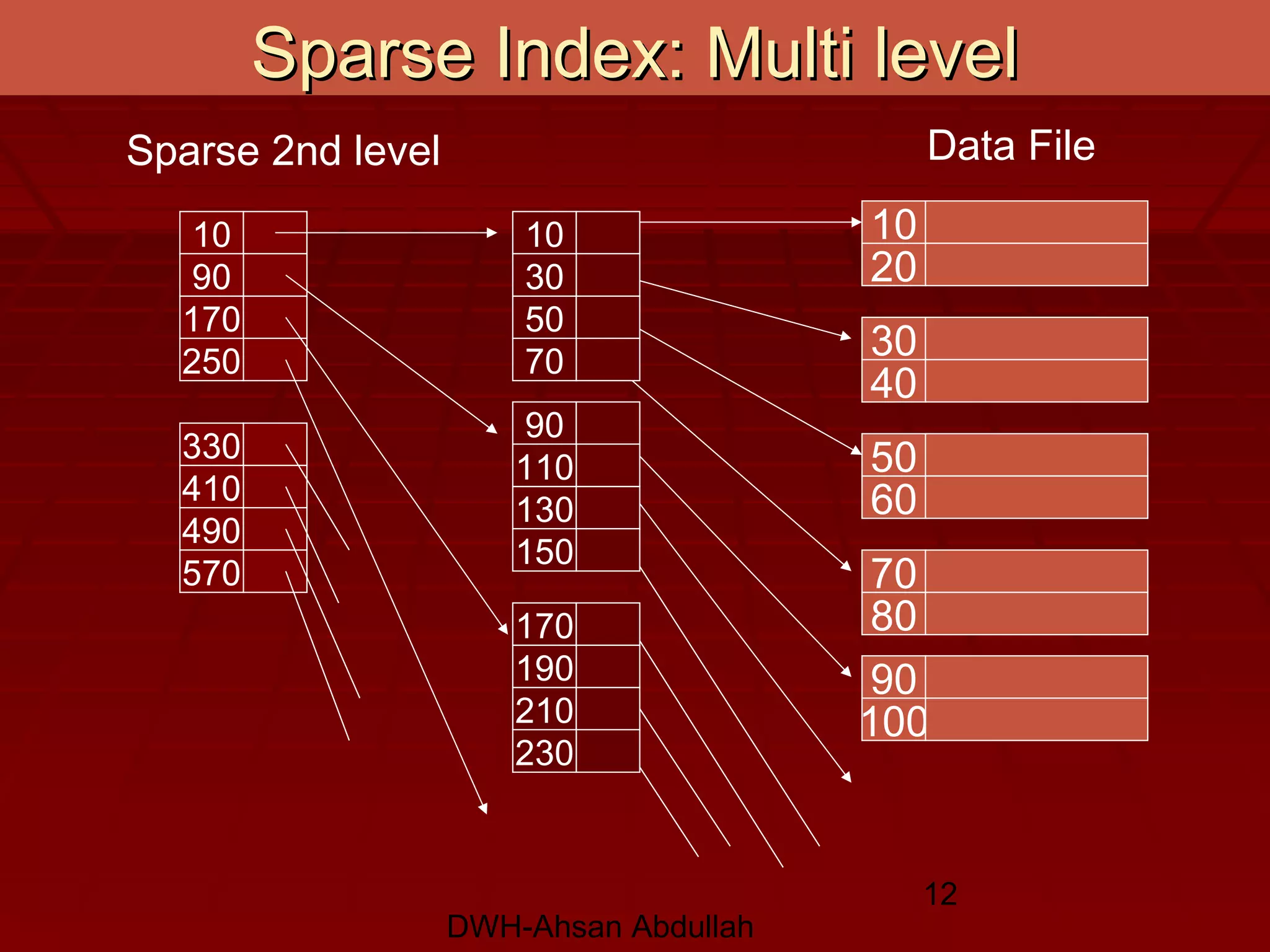
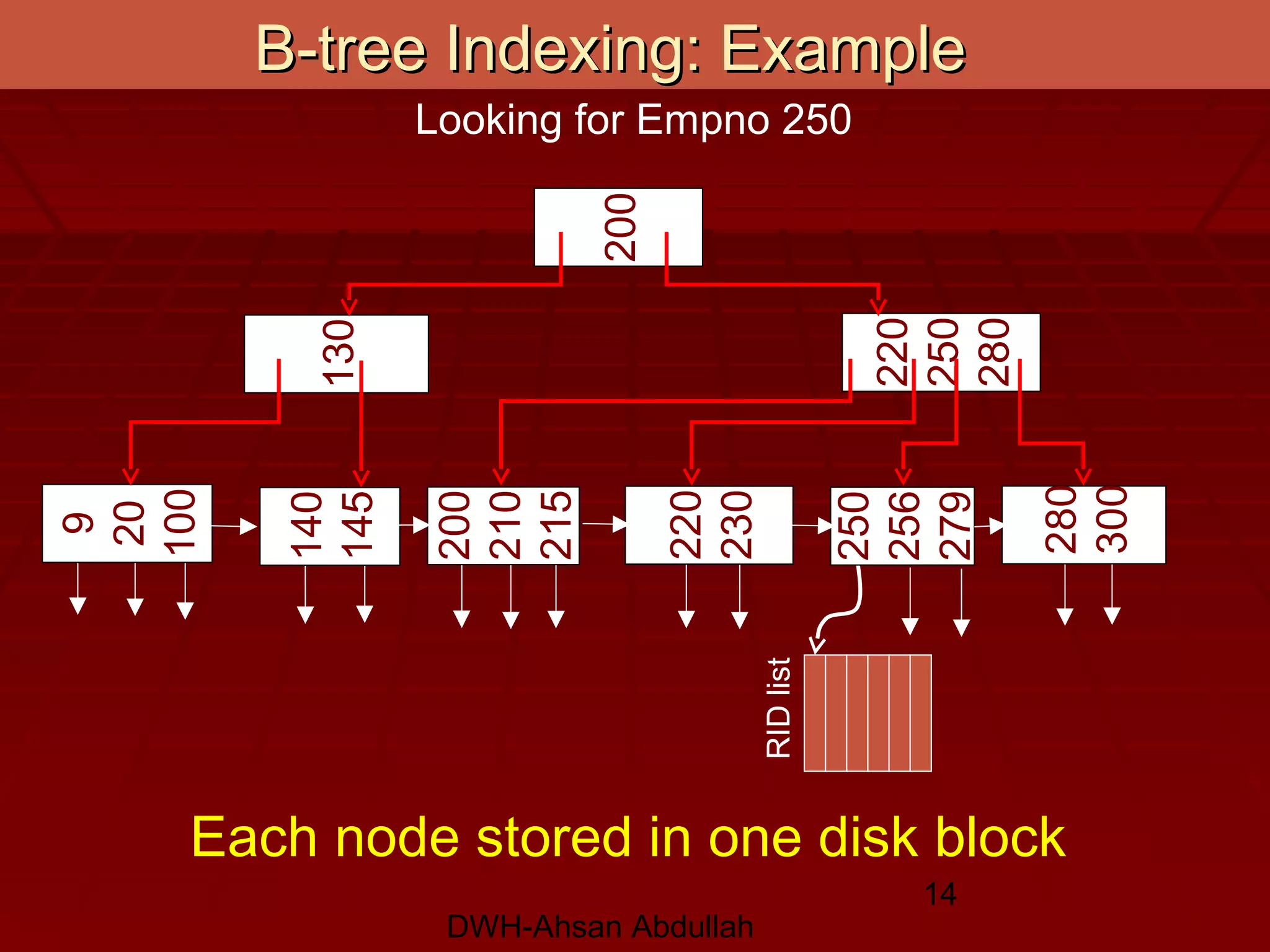
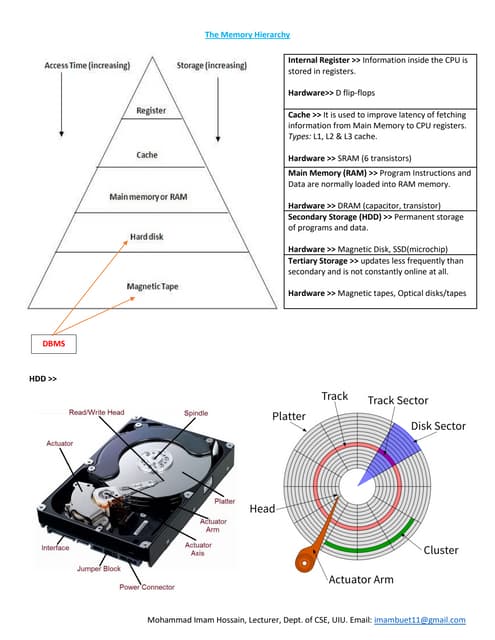
This document discusses various conventional indexing techniques used to improve the speed of data retrieval from databases and data warehouses. It describes dense indexing, sparse indexing, and multi-level or B-tree indexing. It explains that indexing provides pointers to the location of data, avoiding the need to sequentially scan entire data files. The document also covers hashing-based indexes and compares B-tree indexes, which support range queries, to hashing indexes, which are best for exact match queries.