



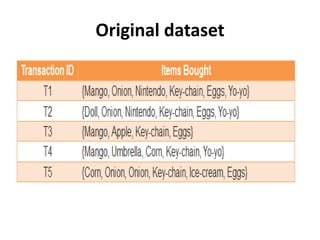
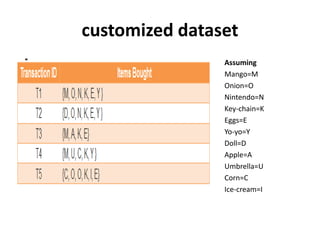


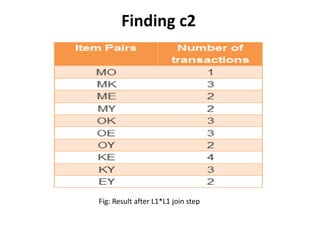
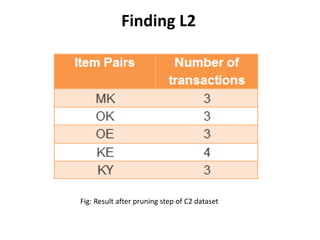
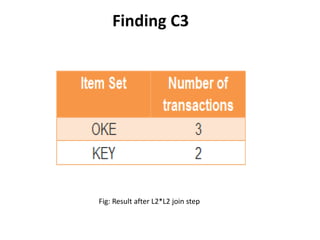







The document discusses the Apriori algorithm, a fundamental data mining technique used to discover frequent itemsets within large datasets. It explains the algorithm's two main steps: the join step and the prune step, while also addressing its drawbacks such as the generation of huge candidate sets and multiple database scans. Additionally, it outlines several improvement mechanisms and references key literature in the field.























































































