Downloaded 22 times






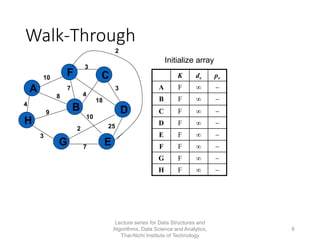
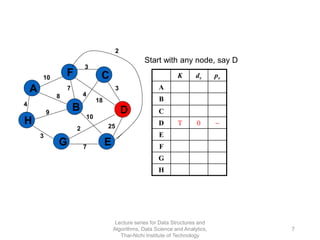
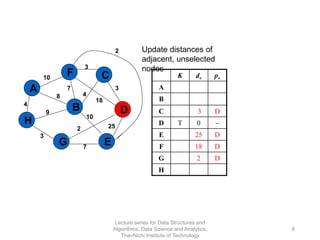
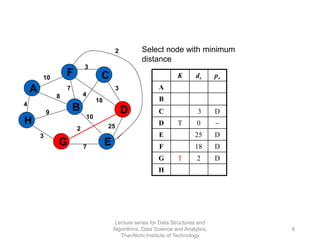
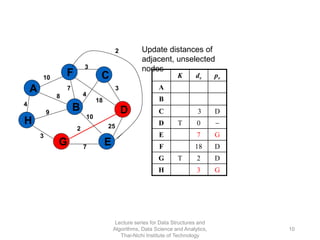
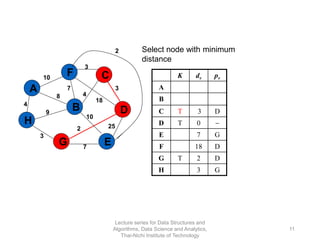
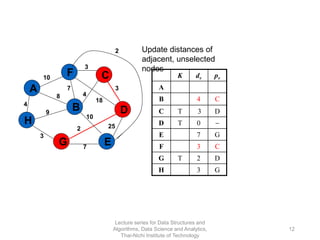
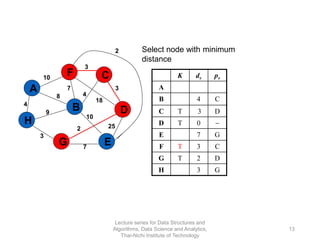
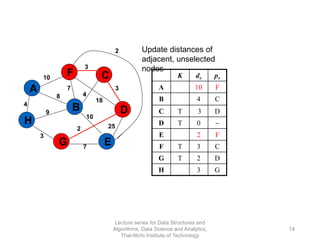
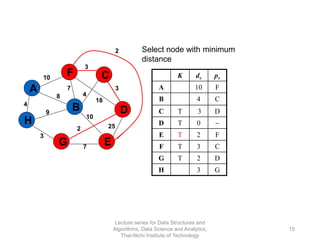
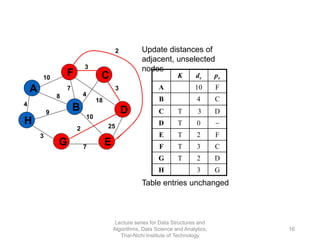
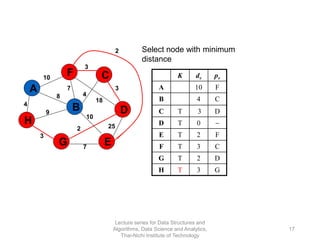
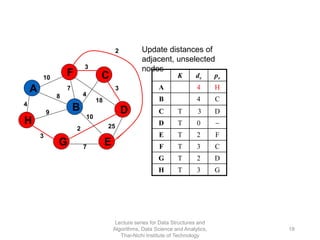
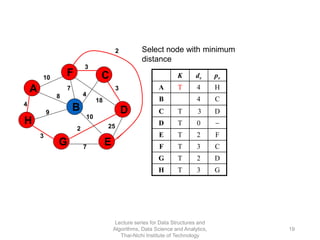
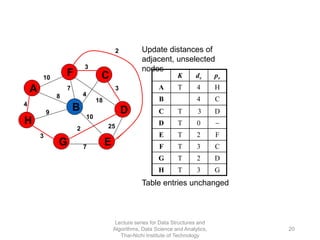
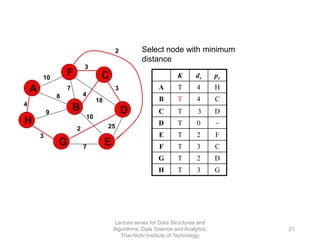
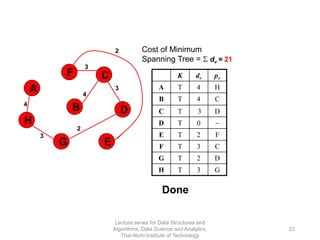


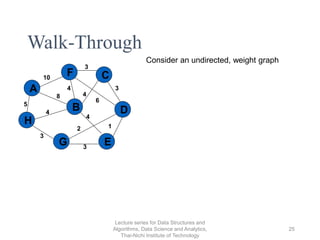
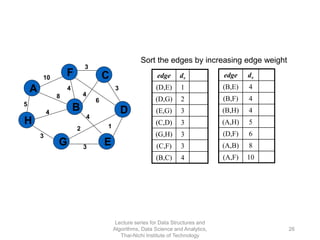
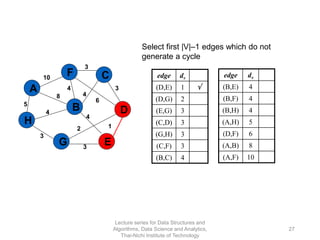
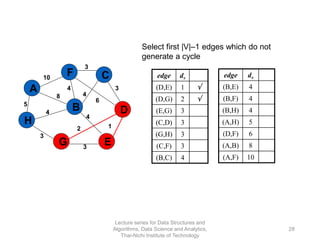
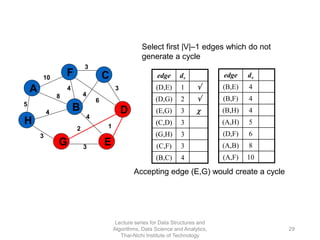
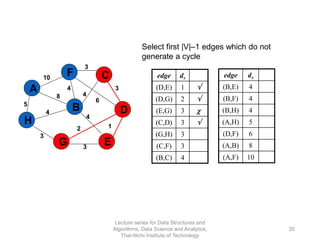
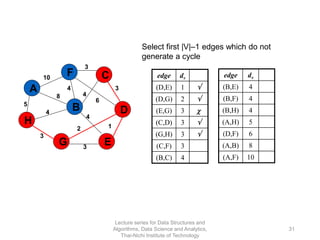
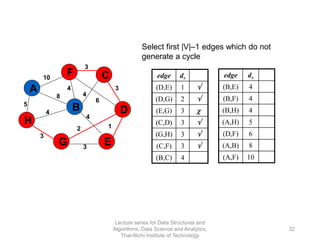
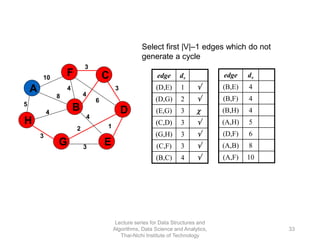
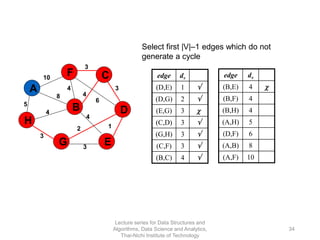
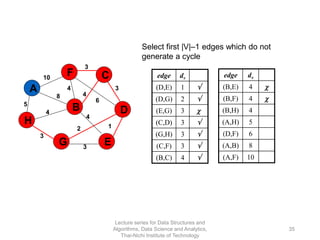
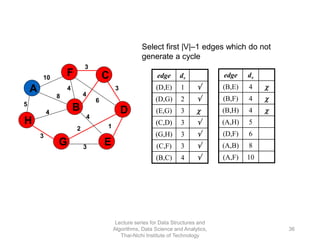
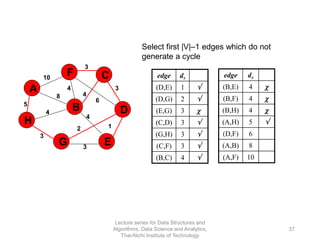
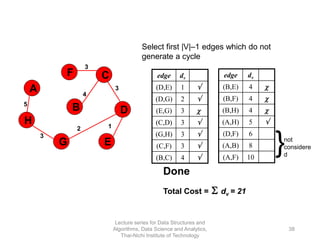



The document discusses minimum spanning trees and provides examples of Prim's and Kruskal's algorithms. It includes: - A definition of minimum spanning tree as a subgraph that spans all nodes with minimum total edge weight. - Characteristics of Prim's and Kruskal's algorithms such as working with undirected, weighted/unweighted graphs and producing optimal solutions greedily. - A walk-through example of Prim's algorithm on a graph and calculating the minimum spanning tree cost.

















![[系列活動] Machine Learning 機器學習課程](https://cdn.slidesharecdn.com/ss_thumbnails/ml4ds02122017-170212005829-thumbnail.jpg?width=640&height=640&fit=bounds)






![[SIGIR17] Learning to Rank Using Localized Geometric Mean Metrics](https://cdn.slidesharecdn.com/ss_thumbnails/slides-170808085021-thumbnail.jpg?width=640&height=640&fit=bounds)













































![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)
















