Download to read offline



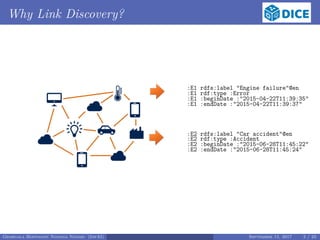


![Challenges in Link Discovery
Accuracy: correct links
Genetic programming
Probabilistic models
Time efficiency: fast and scalable linking
Planning algorithms (e.g. HELIOS [2]):
Use of cost functions to approximate runtime of LS
Cost functions are ONLY linear in the parameters of the planning:
threshold of LS, θ
size of datasets, |S| and |T|
...
Georgala Hoffmann Ngonga Ngomo (InfAI) September 15, 2017 6 / 23](https://image.slidesharecdn.com/slideswiplanner-181023183656/85/An-Evaluation-of-Models-for-Runtime-Approximation-in-Link-Discovery-6-320.jpg)

![Runtime Estimation
Sampling-based approach
similarity measure m (e.g. Levenshtein) and an implementation of the m
(e.g., Ed-Join [3])
execution of m with varying values of |S|, |T| and θ
collection of runtimes
What is the shape of the runtime evaluation function?
Georgala Hoffmann Ngonga Ngomo (InfAI) September 15, 2017 9 / 23](https://image.slidesharecdn.com/slideswiplanner-181023183656/85/An-Evaluation-of-Models-for-Runtime-Approximation-in-Link-Discovery-9-320.jpg)
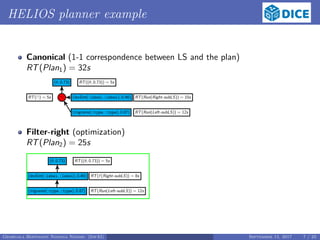
![Runtime Estimation cont.
Define an evaluation function as a mapping φ : N × N × (0, 1] → R, whose
value at (|S|, |T|, θ) is an approximation of the runtime for the LS with
these parameters
Define R = (R1, . . . , Rn) as the measured runtimes for the parameters
S = (|S1|, . . . , |Sn|), T = (|T1|, . . . , |Tn|) and θ = (θ1, . . . , θn)
Constrain the mapping φ to be a local minimum of the L2-Loss:
E(S, T, θ, r) := R − φ(S, T, θ) 2
,
writing φ(S, T, θ) = (φ(|S1|, |T1|, θ1), . . . , φ(|Sn|, |Tn|, θn)).
Georgala Hoffmann Ngonga Ngomo (InfAI) September 15, 2017 10 / 23](https://image.slidesharecdn.com/slideswiplanner-181023183656/85/An-Evaluation-of-Models-for-Runtime-Approximation-in-Link-Discovery-10-320.jpg)

![Experiment set-up
Datasets:
3 benchmark datasets: Amazon-GP, DBLP-ACM and DBLP-Scholar
scalability: MOVIES and VILLAGES
all English labels from DBpedia 2014
Similarity measures and atomic LS
Ed-Join [3]: Levenshtein string distance
PPJoin+ [4]: Jaccard, Overlap, Cosine and Trigrams string similarity measures
θ ∈ [0.5, 1]
Evaluation metric: root mean squared error (RMSE)
Georgala Hoffmann Ngonga Ngomo (InfAI) September 15, 2017 12 / 23](https://image.slidesharecdn.com/slideswiplanner-181023183656/85/An-Evaluation-of-Models-for-Runtime-Approximation-in-Link-Discovery-12-320.jpg)

![Experiment 1
Q1 : How do our models fit each class separately?
Split S and T into non-overlapping parts of equal size
Training with the first half:
selection of 15 source and 15 target random samples of random sizes
comparison each source sample with each target sample 3 times
Testing with the second half:
execution of Ed-Join and PPJoin+ with random θ ∈ [0.5, 1]
store real execution runtime
100 experiments to test each model on each dataset
Georgala Hoffmann Ngonga Ngomo (InfAI) September 15, 2017 14 / 23](https://image.slidesharecdn.com/slideswiplanner-181023183656/85/An-Evaluation-of-Models-for-Runtime-Approximation-in-Link-Discovery-14-320.jpg)
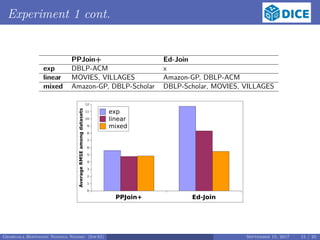


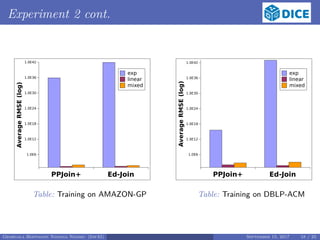
![Experiment 3
Q3 : How do our models perform when trained on a large dataset?
Train on English labels of DBpedia,
Test on Amazon-GP, DBLP-ACM, MOVIES and VILLAGES
Training:
same as in Q1, but
15 source and 15 target random samples of various sizes between 10, 000 and
100, 000
the samples were taken from the English labels of DBpedia
Testing:
use of the EAGLE [1] to learn 100 LSs for each testing dataset
use of evaluation models obtained by training
execution of 100 LSs by HELIOS against the four datasets
Georgala Hoffmann Ngonga Ngomo (InfAI) September 15, 2017 19 / 23](https://image.slidesharecdn.com/slideswiplanner-181023183656/85/An-Evaluation-of-Models-for-Runtime-Approximation-in-Link-Discovery-19-320.jpg)
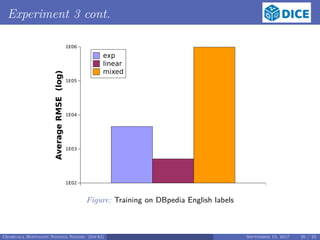




The document evaluates different models for runtime approximation in link discovery, focusing on three models: linear, exponential, and mixed. It analyzes their effectiveness across six datasets, concluding that linear models generally outperform others while mixed and exponential models are less adequate. Future work will explore additional models and features for runtime estimation.











![[Paper Introduction] A Context-Aware Topic Model for Statistical Machine Tran...](https://cdn.slidesharecdn.com/ss_thumbnails/20150910mtstudyoda-150910065338-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)











































































