1. The document discusses different compression techniques for text, audio, images, and video.
2. It provides examples of compression ratios achieved using lossy and lossless compression methods. For example, text compression can achieve 3:1 ratios using Lempel-Ziv coding while audio compression can achieve ratios between 3:1 to 24:1 using MP3.
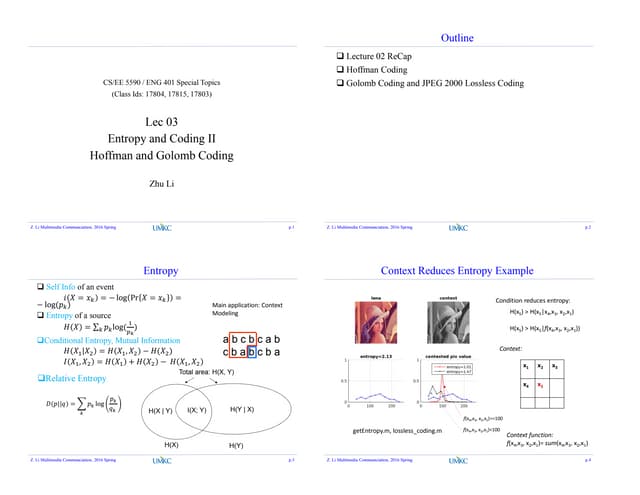
3. The techniques discussed include entropy encoding, run-length encoding, Huffman coding, discrete cosine transforms, and differential encoding which takes advantage of redundancies in the data. The best approach depends on the type of data and acceptable quality.