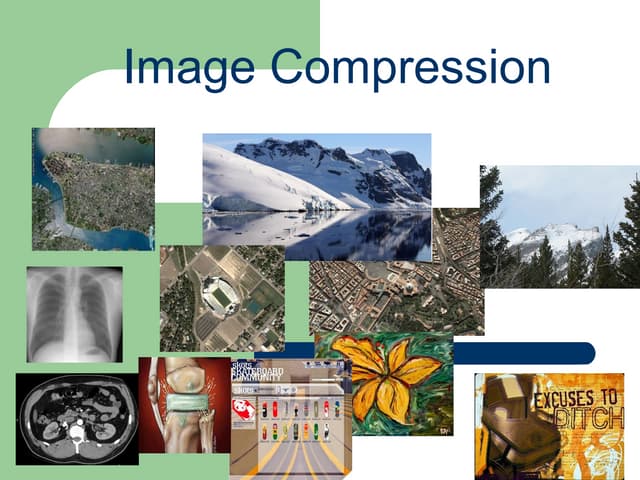
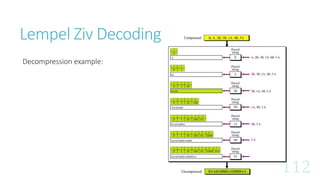
Data compression reduces the size of data files by removing redundant information while preserving the essential content. It aims to reduce storage space and transmission times. There are two main types of compression: lossless, which preserves all original data, and lossy, which sacrifices some quality for higher compression ratios. Common lossless methods are run-length encoding, Huffman coding, and Lempel-Ziv encoding, while lossy methods include JPEG, MPEG, and MP3.










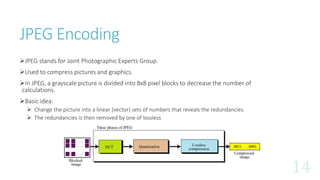
![JPEG Encoding - DCT
The DCT transformation matrix, with one DC coefficient [G(0,0)]
and 63 AC coefficient
The 8×8 sub-image matrix
The two dimensional DCT
The 8×8 sub-image shown in
8-bit grayscale
The quantized sub-image matrix after quantization.](https://image.slidesharecdn.com/datacompression-180704093657/85/Data-compression-15-320.jpg)