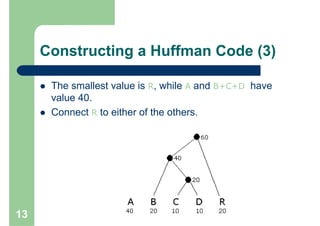
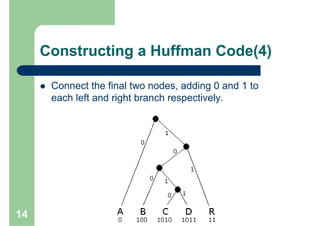
Huffman encoding is a variable-length encoding technique used for text compression that assigns shorter bit strings to more common characters and longer bit strings to less common characters. It uses a prefix code where no codeword is a prefix of another, allowing for unique decoding. The algorithm works by building a Huffman tree from the bottom up by repeatedly combining the two lowest frequency symbols into a node until a full tree is created, with codes read from the paths. This greedy approach results in an optimal prefix code that minimizes the expected codeword length, improving compression.















![Algorithm’s Correctness
It is proven that the greedy algorithm HUFFMAN is correct, as the
problem of determining an optimal prefix code exhibits the greedy-
choice and optimal-substructure properties.
Greedy Choice :Let C an alphabet in which each character c Є C has
frequency f[c]. Let x and y two characters in C having the lowest
frequencies. Then there exists an optimal prefix code for C in which
the codewords for x and y have the same length and differ only in the
last bit.
Optimal Substructure :Let C a given alphabet with frequency f[c]
defined for each character c Є C . Let x and y, two characters in C with
minimum frequency. Let C’ ,the alphabet C with characters x,y
removed and (new) character z added, so that C’ = C – {x,y} U {z};
define f for C’ as for C, except that f[z] = f[x] + f[y]. Let T’ ,any tree
representing an optimal prefix code for the alphabet C’. Then the tree
T, obtained from T’ by replacing the leaf node for z with an internal
node having x and y as children, represents an optimal prefix code for
the alphabet C.
17](https://image.slidesharecdn.com/huffmanencodingpr-100208222136-phpapp02/85/Huffman-Encoding-Pr-17-320.jpg)

























































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)

















