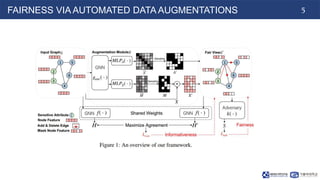
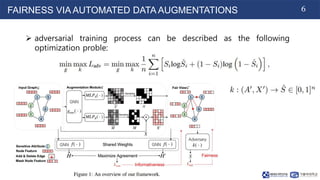
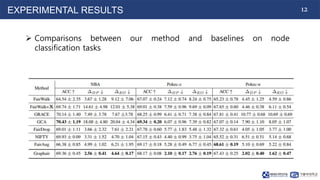
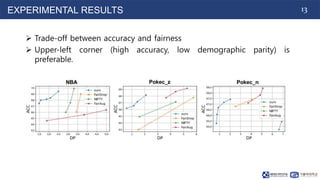
The document proposes Graphair, a method for fair graph representation learning via automated data augmentations. Graphair uses an adversarial process to automatically discover fairness-aware data augmentation strategies for different graph datasets. The augmentation process modifies graphs by perturbing edges and masking node features. Graphair aims to learn representations that achieve demographic parity and equal opportunity while preserving predictive accuracy. Experimental results on node classification tasks show Graphair achieves better fairness metrics than baselines while maintaining high accuracy.