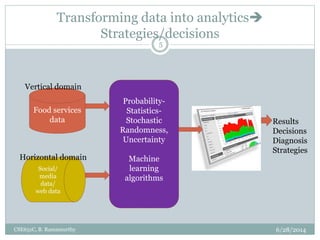
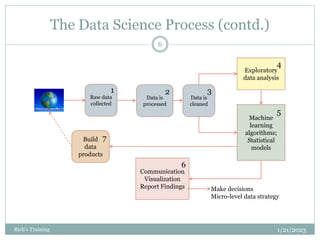
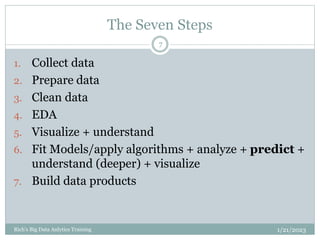
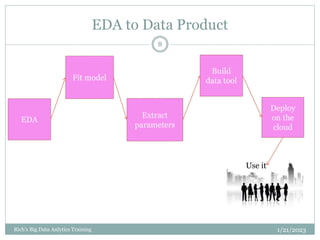
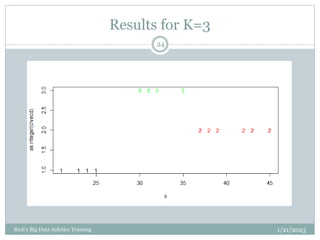
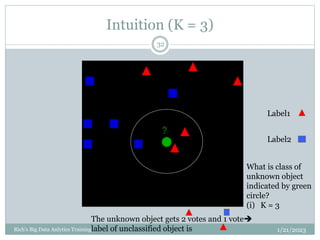
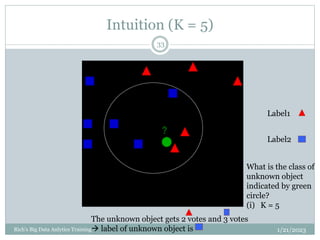
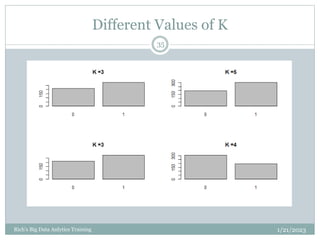
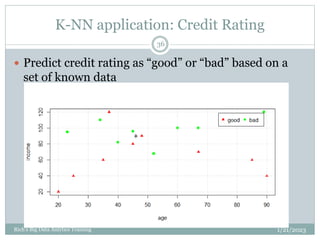
The document provides an overview of topics to be covered in a data analytics training, including a review of previous concepts and an introduction to new topics. It discusses the data science process, linear regression, k-means clustering, k-nearest neighbors (k-NN) classification, and provides examples of applying these machine learning algorithms to real datasets. Sample R code is also included to demonstrate k-means and k-NN algorithms on synthetic data. The goal is for students to gain hands-on experience applying different analytical techniques through worked examples and exercises using real data.