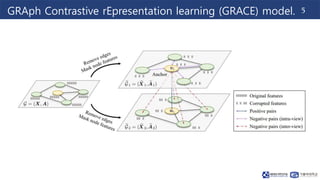
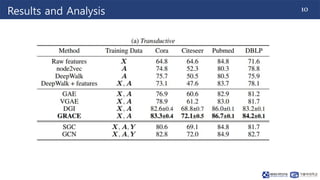
This document summarizes a research paper on graph contrastive representation learning (GRACE) using an unsupervised framework. GRACE generates two graph views through random corruption, then trains a model with a contrastive loss to maximize agreement between node embeddings in the two views. It considers corruption at both the topology and node attribute levels. Experiments on citation networks show GRACE achieves competitive performance for transductive and inductive node classification tasks.














![[NS][Lab_Seminar_240617]A Survey on Graph Neural Networks and Graph Transform...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar240617asurvey-240624082546-9e44d3fd-thumbnail.jpg?width=640&height=640&fit=bounds)



![[NS][Lab_Seminar_250224]GraphAdapter.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar250224graphadapter-250224130027-8504e9dc-thumbnail.jpg?width=640&height=640&fit=bounds)




![250623_JW_labseminar[STRATEGIES FOR PRE-TRAINING GRAPH NEURAL NETWORKS].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/250623jwlabseminarcontextpred-250627073644-0949d35d-thumbnail.jpg?width=640&height=640&fit=bounds)
![250602_JW_labseminar[Graph Contrastive Learning Automated].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/250602jwlabseminarjoao-250602114133-ad86c61a-thumbnail.jpg?width=640&height=640&fit=bounds)




















































