Downloaded 53 times









![Date Meeting Title Speaker Link
20150122 Advanced Data Manipulation Mike McCann [Slide]
20150121 Berkeley Institute for Data Science Pipelines for Data Analysis Hadley Wickham [Video]
20150114 RStudio Webinar Data Wrangling with R Garrett Grolemund [Slide][Video][Data]
20150113 Upstate Data Analytics Wallace Campbell [Video][Data]
20141202 Sheffield R Users Group how to find help online, data manipulation with plyr and dplyr Mathew Hall [Slide]
20141126 Budapest BI Introduction to the dplyr R package Romain Francois [Slide]
20141111 LA R users group Benchmarking dplyr and data.table (with biggish data) Szilard Pafka [Slide][Data]
20141025 ACM DataScience Camp Data Manipulation Using R Ram Narasimhan [Slide][Video]
20141022 Becoming a data ninja with dplyr Devin Pastoor [Slide]
20141007 Davis R Users' Group dplyr: Data manipulation in R made easy Michael A. Levy [Slide][Video]
20140825 RStudio Webinar Hands-on dplyr tutorial for faster data manipulation in R [Slide][Video]
20140701 USER2014 dplyr: a grammar of data manipulation Hadley Wickham [Video]
20140630 USER2014 Data manipulation with dplyr Hadley Wickham [Slide][Video][Data]
20140214 Stanford HCI Group Expressing yourself in R Hadley Wickham [Slide][Data]
See updated list at: https://github.com/lifan0127/meetup_dplyr_talk](https://image.slidesharecdn.com/caahc1i3te0meodvfkag-signature-f81f3e920f2e654d815d82e81c638aa1acc6e4924adac05342d3b318cc69d562-poli-150224051755-conversion-gate01/85/Learn-to-use-dplyr-Feb-2015-Philly-R-User-Meetup-10-320.jpg)


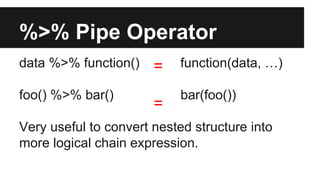
The document provides an overview of the dplyr package for R, highlighting its features such as unified syntax, fast C++ implementation, and support for various data backends. It outlines basic operators like select, filter, and mutate, along with examples demonstrating their usage on weather data. Additional resources and references for learning and exploring dplyr further are also included.










![[Paper Reading] Steering Query Optimizers: A Practical Take on Big Data Workl...](https://cdn.slidesharecdn.com/ss_thumbnails/steersigmod21-210913065908-thumbnail.jpg?width=640&height=640&fit=bounds)




















































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)

















![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)