Downloaded 14 times




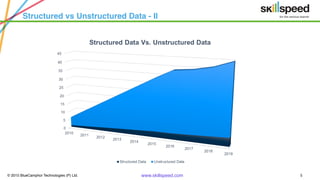
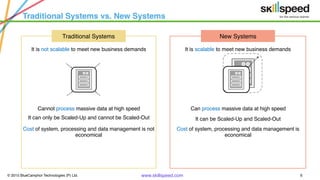

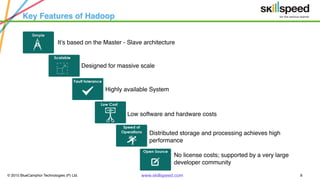
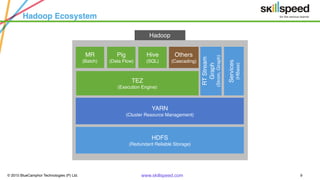
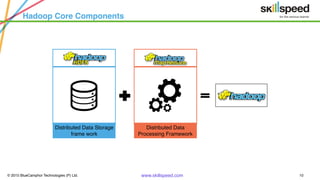

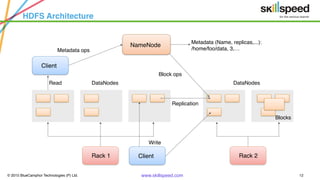
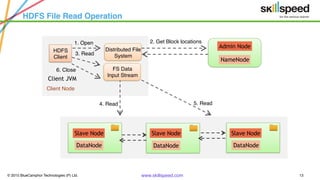
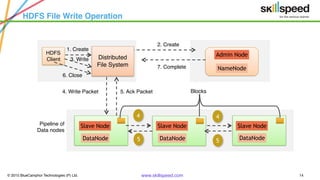
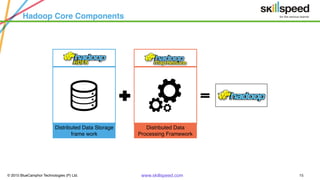

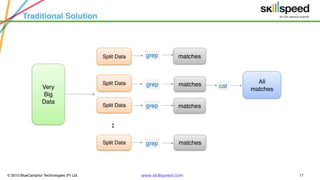
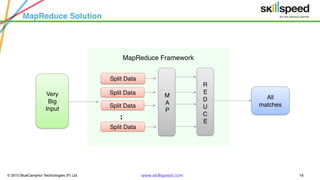
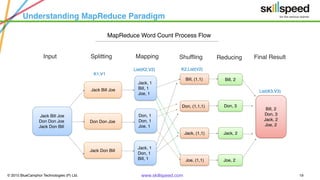
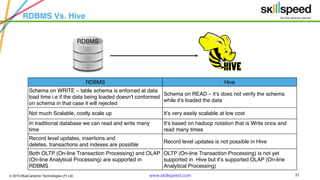





This document provides an overview of Hadoop and related big data technologies. It begins with defining big data and discussing why traditional systems are inadequate. It then introduces Hadoop as a framework for distributed storage and processing of large datasets. The key components of Hadoop - HDFS for storage and MapReduce for processing - are described at a high level. HDFS architecture and read/write operations are outlined. MapReduce paradigm and an example word count job are also summarized. Finally, Hive is introduced as a data warehouse tool built on Hadoop that provides SQL-like queries for large datasets.





























![Spark手把手:[e2-spk-s03]](https://cdn.slidesharecdn.com/ss_thumbnails/e2-spk-s03slides-160619033258-thumbnail.jpg?width=640&height=640&fit=bounds)
![Spark手把手:[e2-spk-s01]](https://cdn.slidesharecdn.com/ss_thumbnails/e2-spk-s01slides-160609233431-thumbnail.jpg?width=640&height=640&fit=bounds)
![Spark手把手:[e2-spk-s02]](https://cdn.slidesharecdn.com/ss_thumbnails/e2-spk-s02slides-160611131623-thumbnail.jpg?width=640&height=640&fit=bounds)


![Spark手把手:[e2-spk-s04]](https://cdn.slidesharecdn.com/ss_thumbnails/e2-spk-s04slides-160708052705-thumbnail.jpg?width=640&height=640&fit=bounds)












































![[DSC Europe 25] Mikhail Rozhkov - AI Product Canvas: From Business Goals to T...](https://cdn.slidesharecdn.com/ss_thumbnails/d53doddtpgfqivmzqel6-mikhail-rozhkov-ai-product-canvas-v1-260121115910-9dd517a7-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Egor Krasheninnikov - The Control Stack: Building Guardrails ...](https://cdn.slidesharecdn.com/ss_thumbnails/3lzcz7hxqmo51mtalv4u-the-control-stack-260119101520-ea90841a-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Tali Fulman - Guild Meetings, Then What? Building Data Commun...](https://cdn.slidesharecdn.com/ss_thumbnails/fgohhi33rwmhqdowdj5k-tali-fulman-guild-meetings-then-what-building-data-communities-that-actually-ch-260120105855-528492c3-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Andrzej Kowalczyk - AI - how to start small and grow in the f...](https://cdn.slidesharecdn.com/ss_thumbnails/oy1zmo94qv6vpcqjvno2-andrzej-kowalczyk-ai-how-to-start-small-and-grow-in-the-future-1-260119121559-cf093b23-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dubravko Culibrk - Deep Learning for Mammography.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/yiscimuktacgqoiu4dkp-deep-learning-for-mammography-260119121559-aad59182-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Paula Garcia Esteban -Building the Future: The Role of Data S...](https://cdn.slidesharecdn.com/ss_thumbnails/9ld1r1bsqpwve8qfvphy-paula-garcia-esteban-building-the-future-260122103838-4171f5cb-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Harshvardhan Jain - From Pre-Trained to Purpose-Built: Fine-T...](https://cdn.slidesharecdn.com/ss_thumbnails/zru4zmiseku5tgvu2dgw-harshvardhan-jain-from-pre-trained-to-purpose-built-fine-tuning-llms-for-high-i-260119101520-8335585f-thumbnail.jpg?width=640&height=640&fit=bounds)



