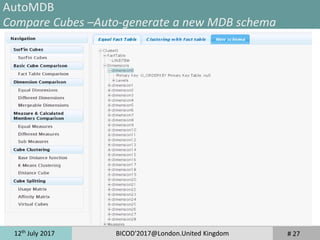
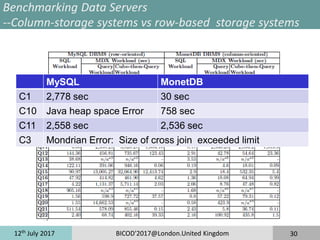
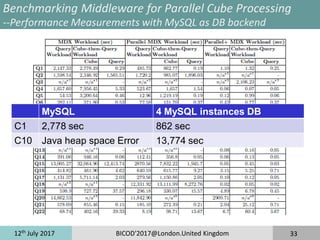
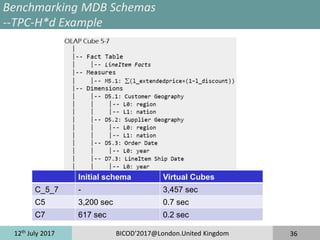
The document discusses taming the size and cardinality of OLAP data cubes over big data. It presents an overview of data warehouse systems and architectures, OLAP cubes, and decision support system benchmarks. It then introduces the TPC-H*d benchmark for evaluating multi-dimensional databases and the AutoMDB tool for automating multi-dimensional database design. Lastly, it discusses application scenarios for benchmarking data servers, multi-dimensional database schemas, and parallel OLAP servers.






![12th
July 2017 BICOD'2017@London.United Kingdom 10
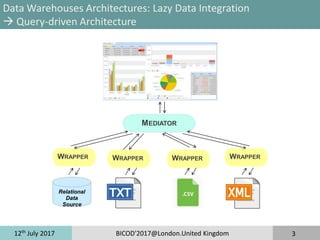
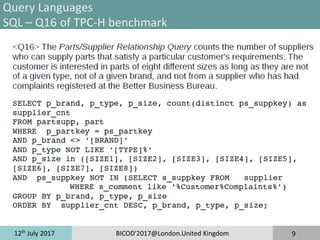
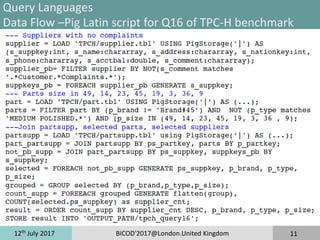
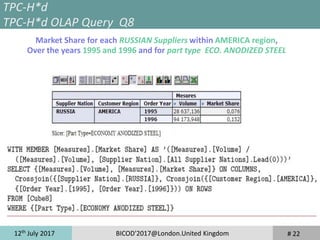
Query Languages
MDX –Q16 of TPC-H Benchmark
WITH SET [Brands] AS 'Except({[Part Brand].Members}, {[Part
Brand].[Brand#45 ]})'
SET [Types] AS 'Filter({[Part Type].Members}, (NOT ([Part
Type].CurrentMember.Name MATCHES "(?i)MEDIUM POLISHED.*")))'
SET [Sizes] AS 'Filter({[Part Size].Members}, ([Part Size].CurrentMember IN
{[Part Size].[3], [Part Size].[9], [Part Size].[14], [Part Size].[19], [Part Size].[23],
[Part Size].[36], [Part Size].[45], [Part Size].[49]}))'
SELECT [Measures].[Supplier Count] ON COLUMNS,
nonemptyCrossjoin(nonemptyCrossjoin([Brands], [Types]), [Sizes]) ON ROWS
FROM [Cube16]](https://image.slidesharecdn.com/bicod2017-171123094407/85/Bicod2017-10-320.jpg)


![12th
July 2017 BICOD'2017@London.United Kingdom 14
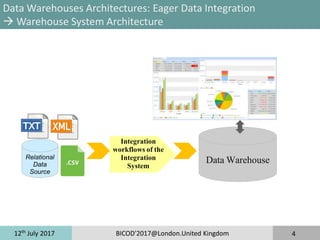
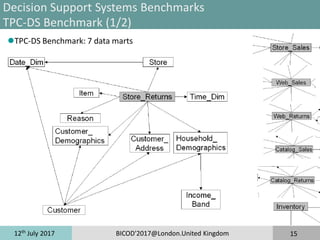
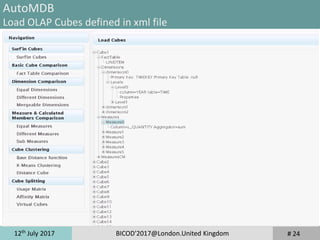
Decision Support Systems Benchmarks
TPC-H Benchmark (2/2)
TPC-H Benchmark 2 Metrics
»QphH@Size is the number of queries processed per hour, that the system
under test can handle for a fixed load
»$/QphH@Size represents the ratio of cost to performance, where the cost is
the cost of ownership of the SUT (hardware,software, maintenance).
Variants of TPC-H Benchmarks
TPC-H*d Benchmark [Cuzzocrea and Moussa, 2013]
»Turning TPC-H benchmark into a Multi-dimensional benchmark
»Few schema changes
»Same TPC-H workload
»2 MDX workloads: query workload cube-then-query workload
SSB: Star Schema Benchmark [O’Neil et al., 2012]
»Turning TPC-H benchmark into star-schema
»Workload composed of 12 queries
TPC-H translated into Pig Latin (Apache Hadoop Ecosystem) [Moussa,2012]
»22 pig latin scripts which load and process TPC-H raw data files (.tbl files)](https://image.slidesharecdn.com/bicod2017-171123094407/85/Bicod2017-14-320.jpg)












![12th
July 2017 BICOD'2017@London.United Kingdom 38
Future Work
Intelligent Recommenders for the selection of Indexes and
Materialized Views
Indexes and physical structures that can significantly accelerate
performance
XML description of each cube allows us to recommend
Recommenders for performance tuning
»AutoAdmin research project at Microsoft, which explores techniques
to make databases self-tuning [Agrawal et al., 2000]
»Alerter Approach [Hose et al., 2008]: support the aggregate
configuration of an OLAP server by (1) continuously monitoring
information about the workload and the benefit of aggregation tables
and (2) alerting the DBA if changes to the current configuration would
be beneficial
»Semi-Automatic Index Tuning: keeping DBAs in the loop [Schnaiter and
Polyzotis, 2012] Online workload analysis with decisions delegated to
the DBA. The solution takes into account index interactions](https://image.slidesharecdn.com/bicod2017-171123094407/85/Bicod2017-38-320.jpg)




![12th
July 2017 BICOD'2017@London.United Kingdom 44
Decision Support Systems Benchmarks
TPC-DI Benchmark (1/3)
[Poess et al. 2014]
For benchmarking Data Integration technologies
Synthetic Data of a Factious Retail Brokerage Firm
»Internal Trading system data, Internal Human resources data, Internal
CRM System and External data
»Different data scales
»Data extracted from different sources:
»Structured (csv)
»Semi-structured data (xml)
»Multi record (nested data)
»Change Data Capture (CDS)
18 Complex Data Integration Tasks
Load large volumes of historical data
Load incremental updates
Execute complex transformations
Check and ensure consistency of data](https://image.slidesharecdn.com/bicod2017-171123094407/85/Bicod2017-44-320.jpg)



























![Introducing TiDB [Delivered: 09/27/18 at NYC SQL Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/nycmysqlintroducingtidb-180928024621-thumbnail.jpg?width=640&height=640&fit=bounds)






































![Polymer [ बहुलक ] Chemistry Notes PDF - Irfanullah Mehar - JJ Sir Chemistry.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/polymerchemistrynotespdf-irfanullahmehar-jjsirchemistry-260210172118-3f9b37f7-thumbnail.jpg?width=640&height=640&fit=bounds)






