Downloaded 12 times

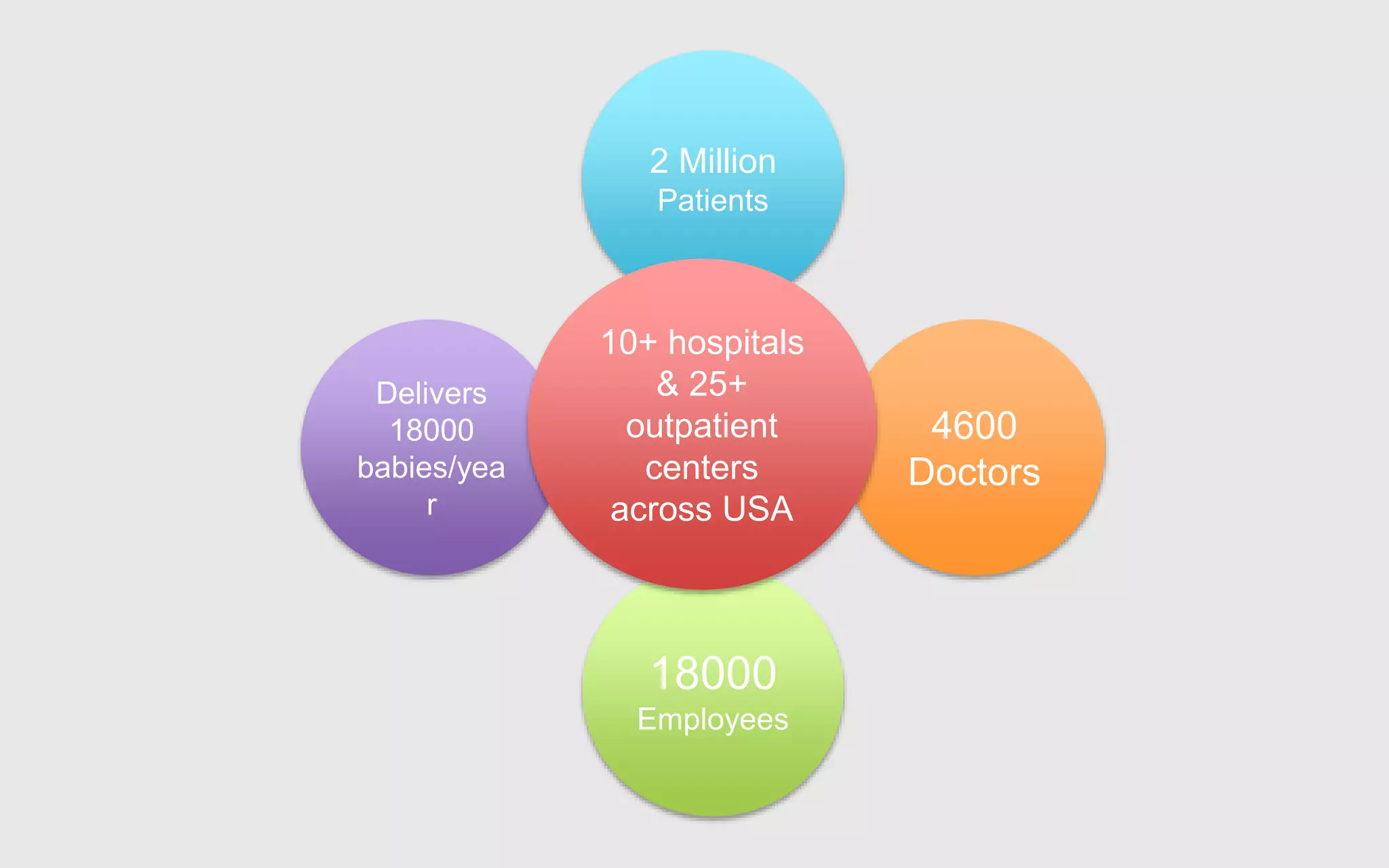

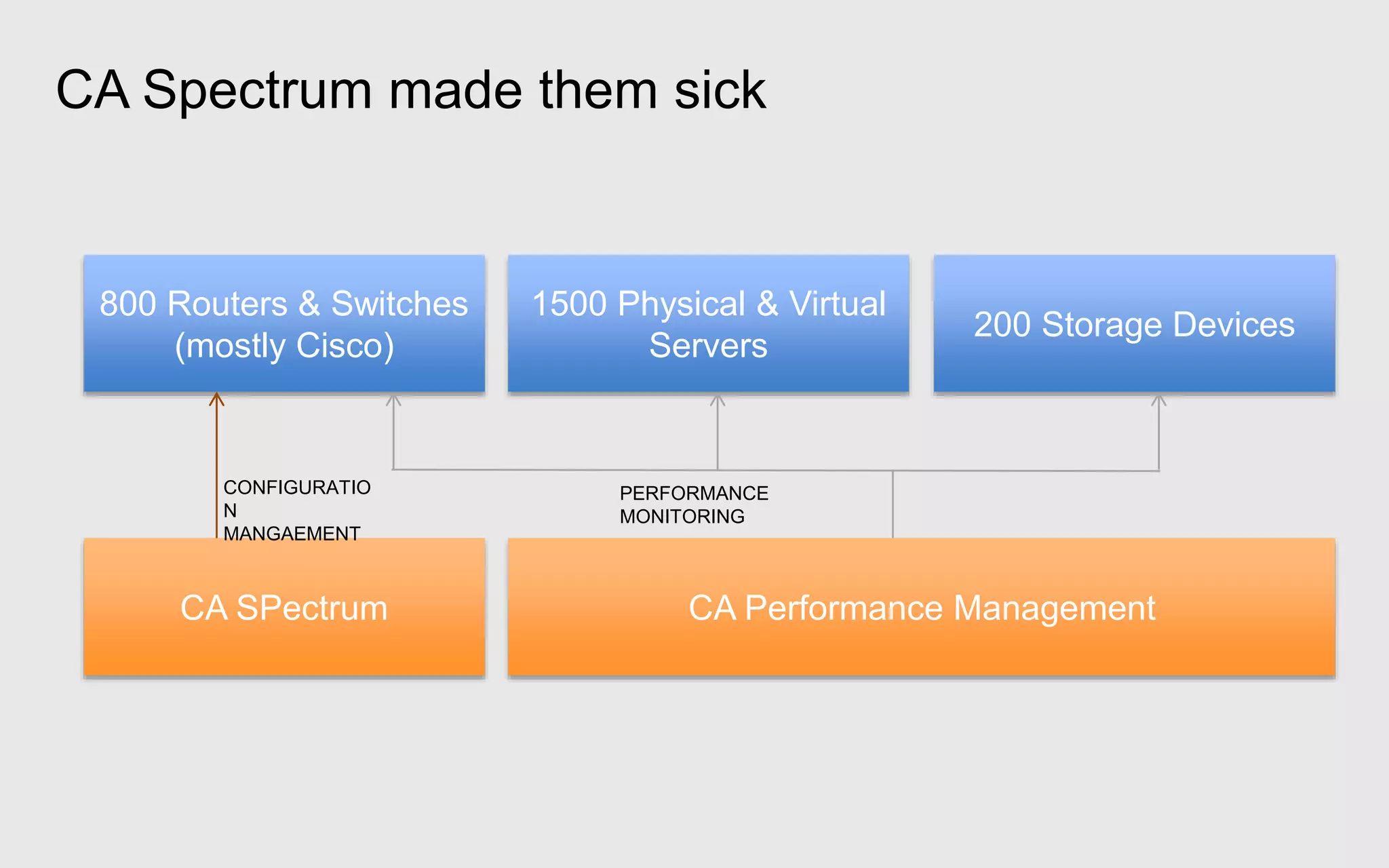

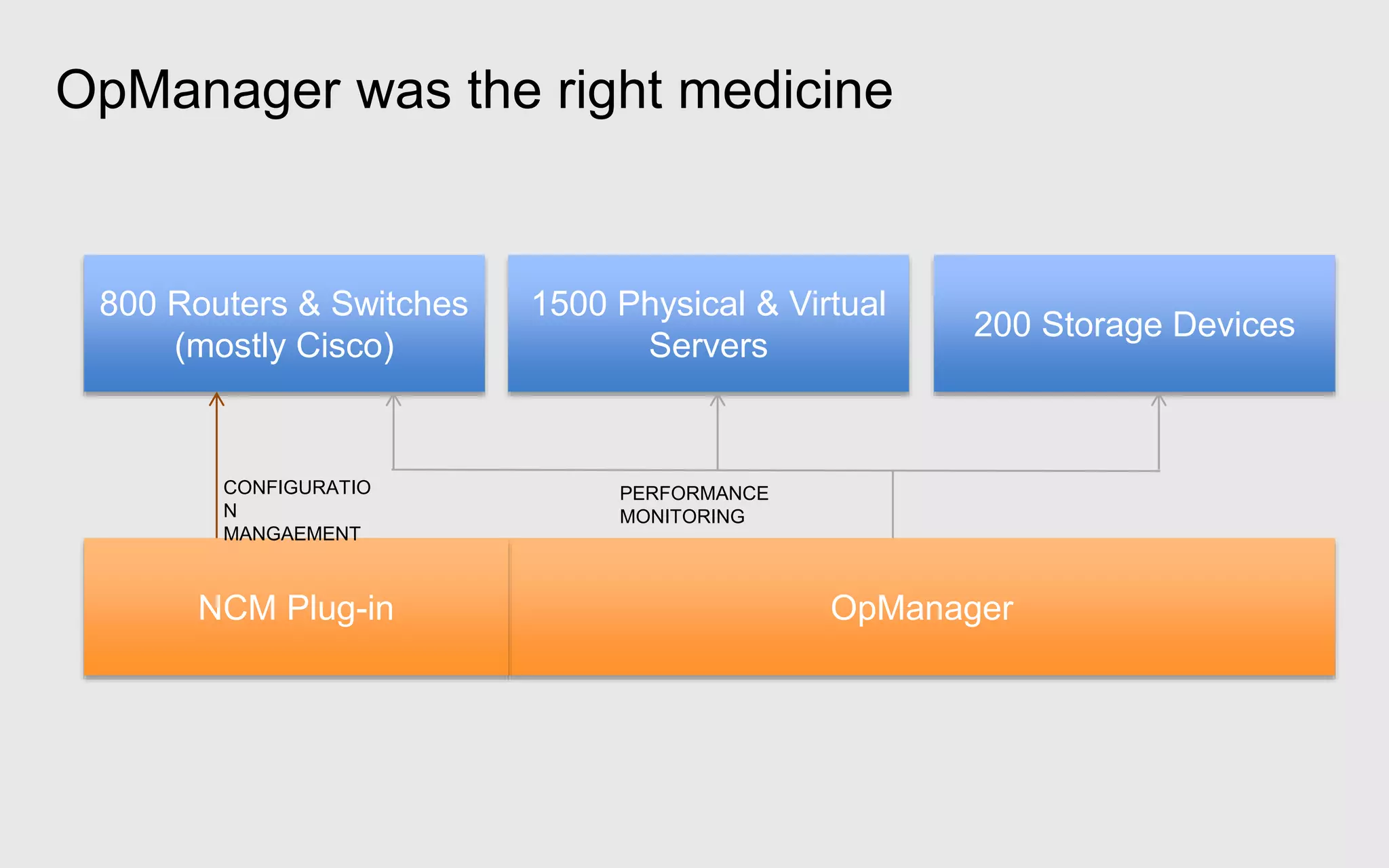

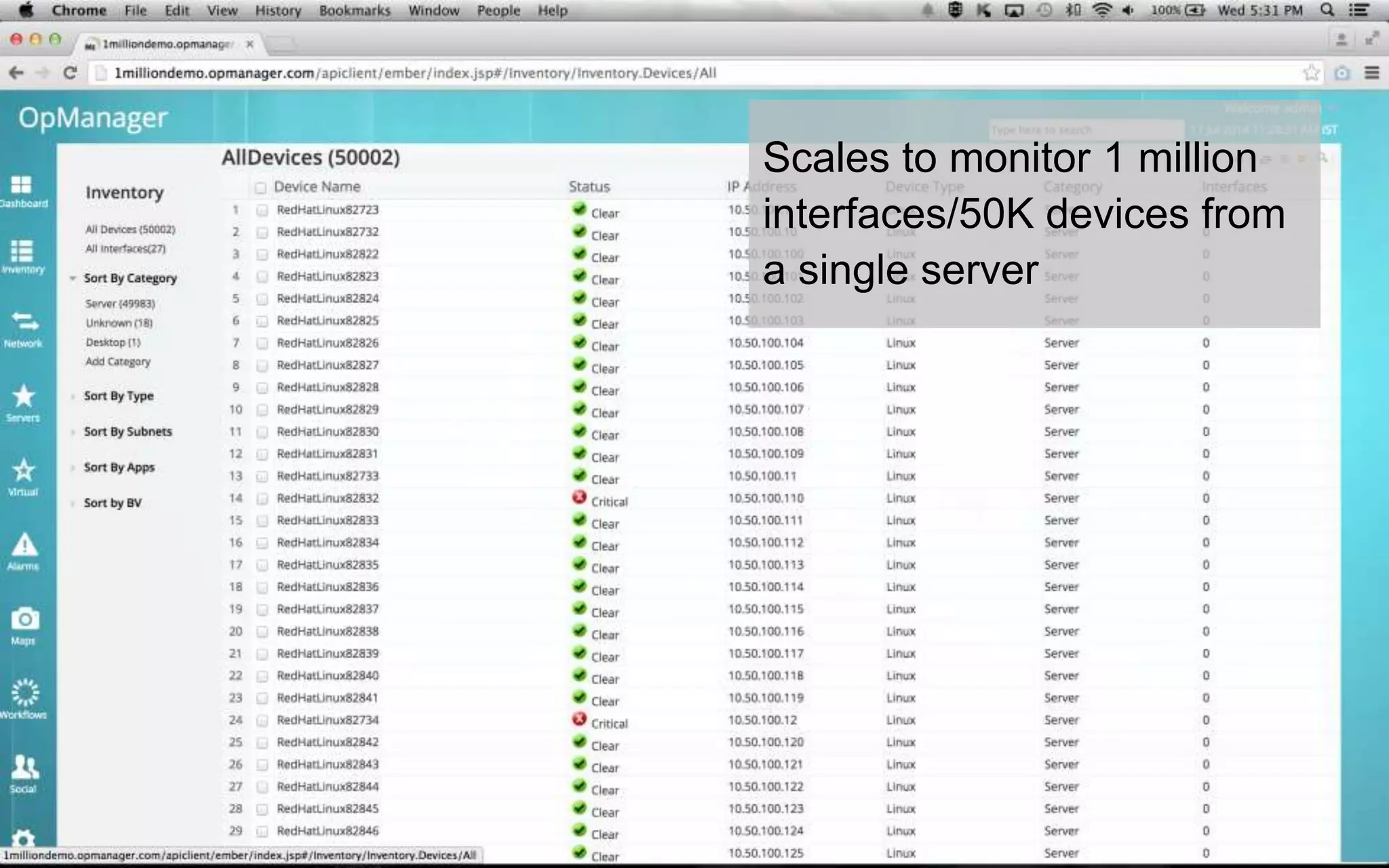
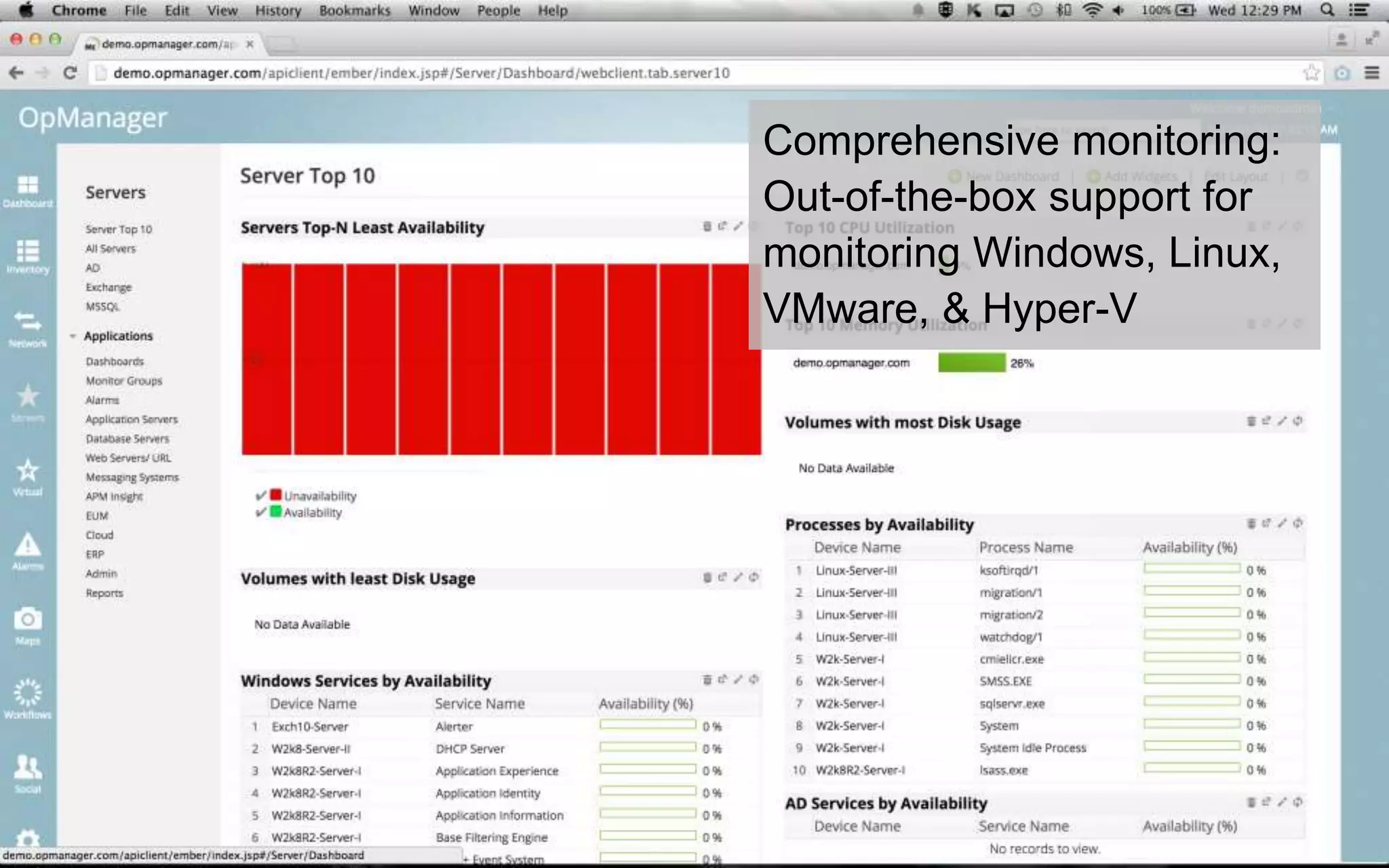
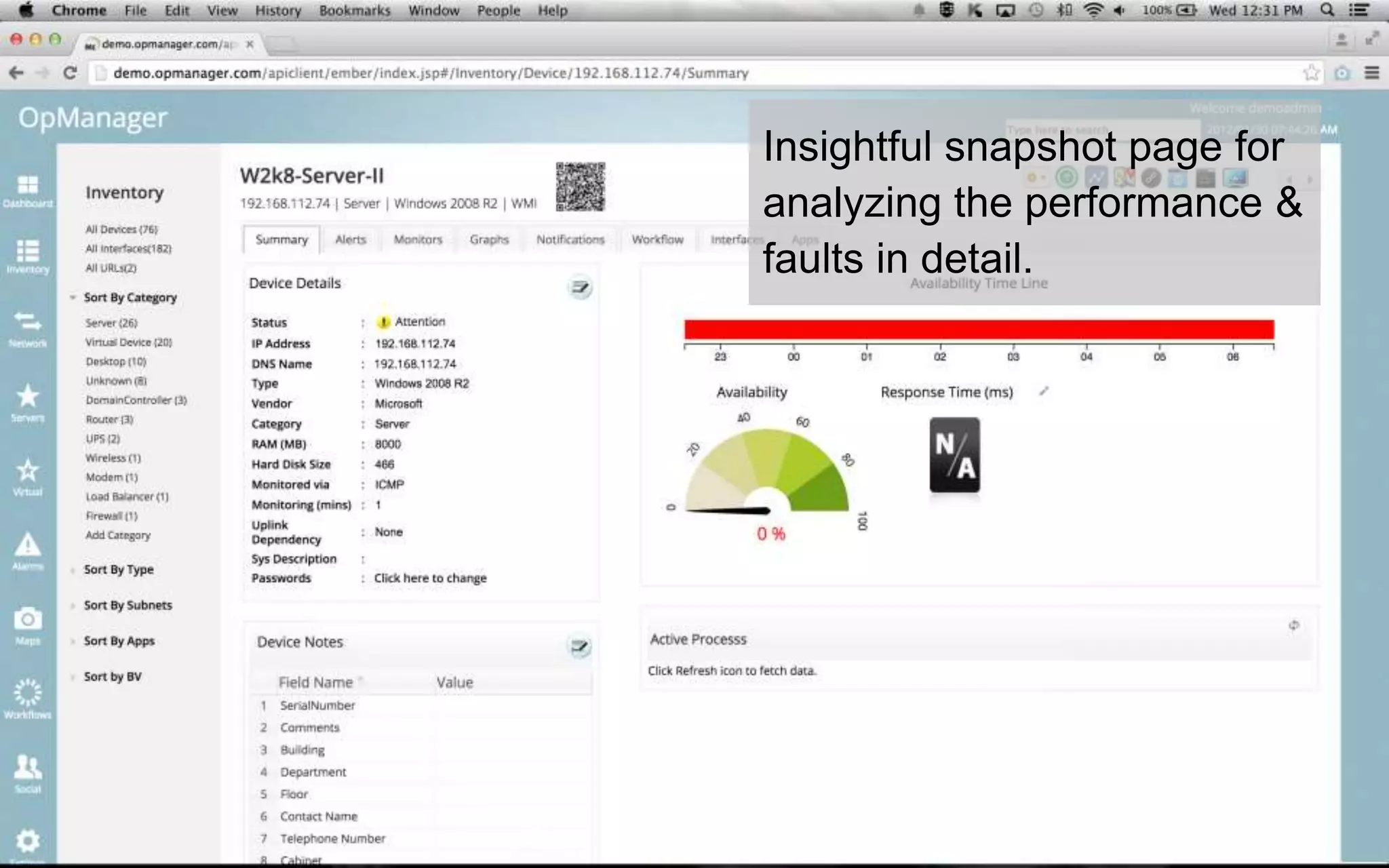
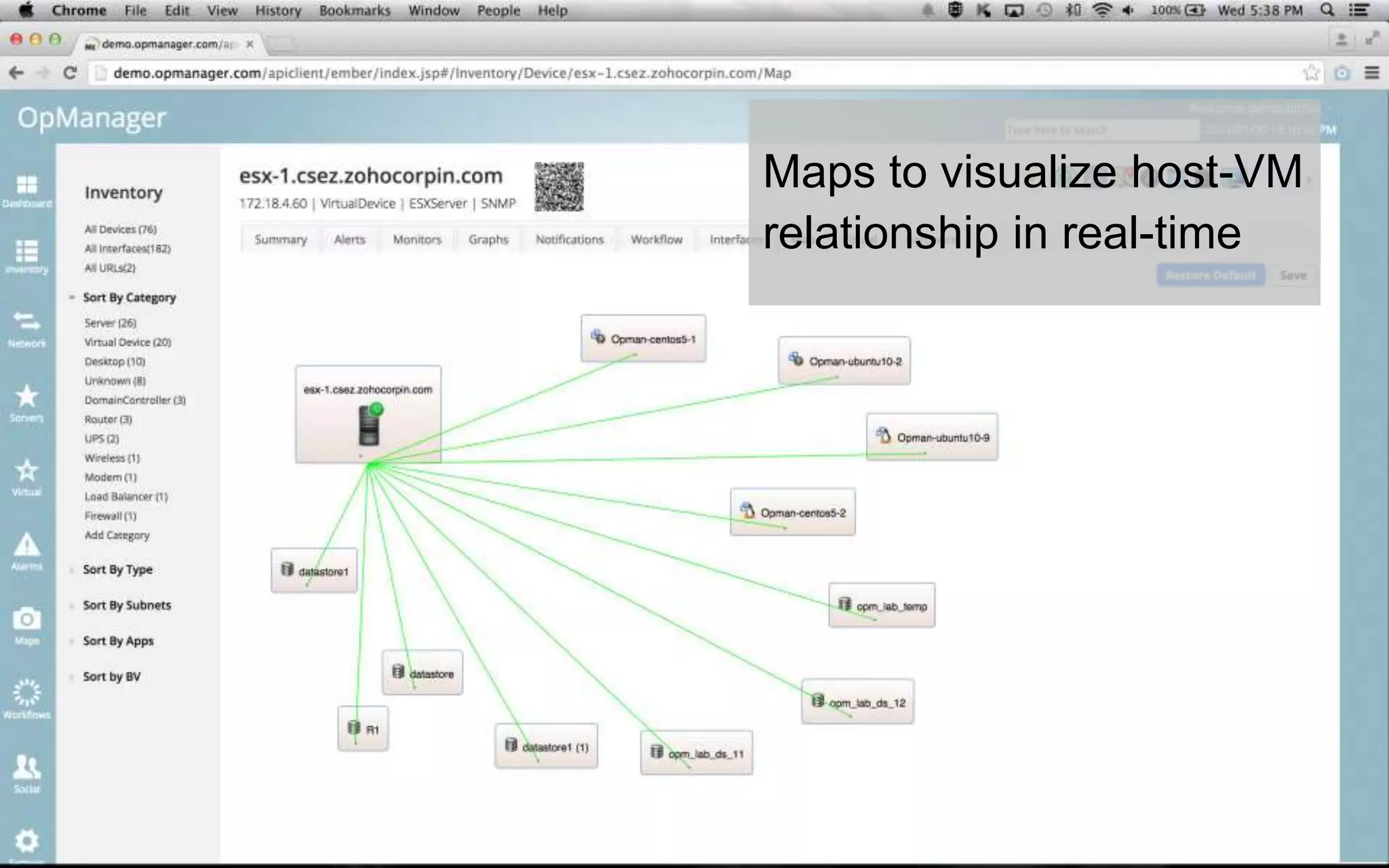
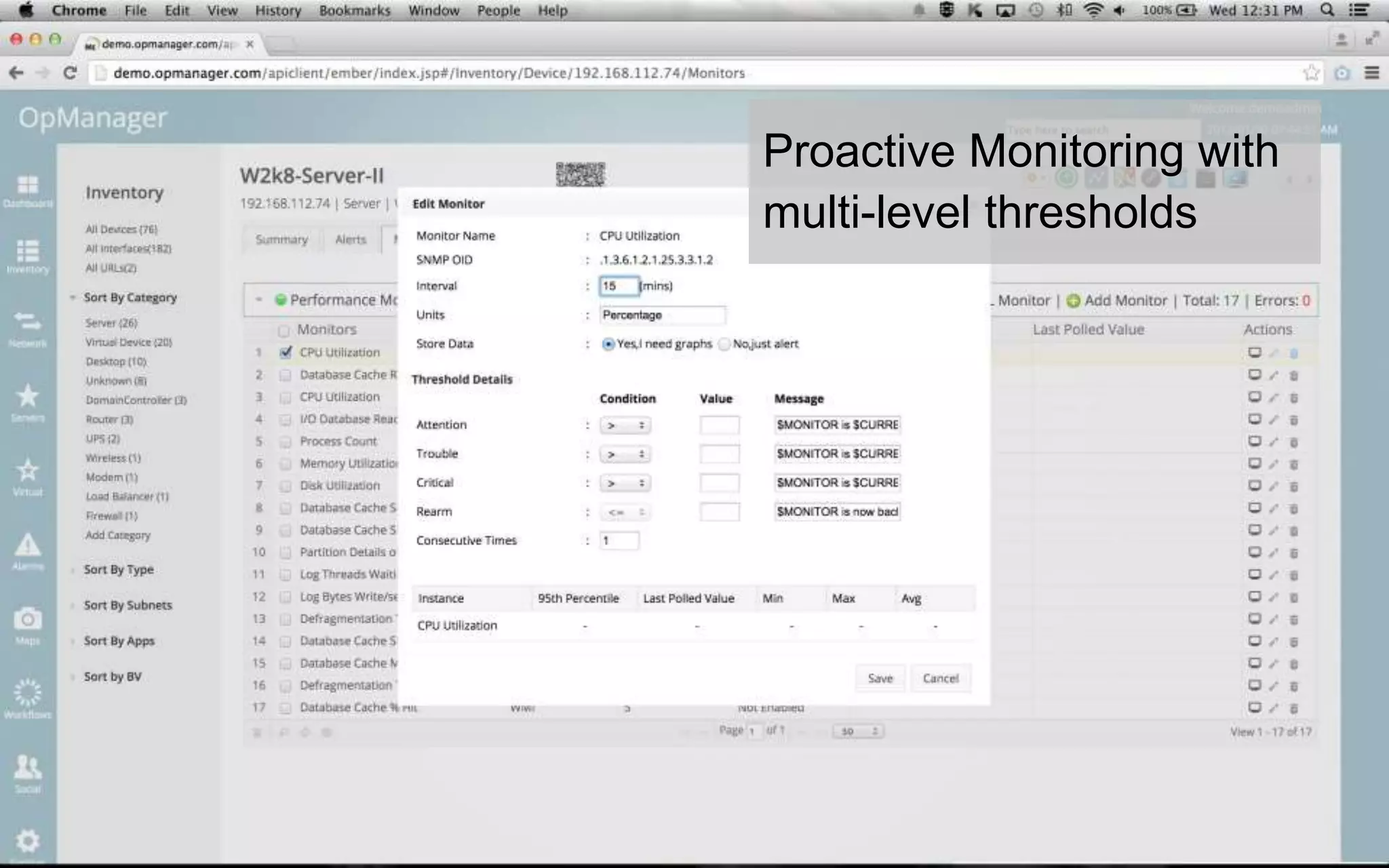
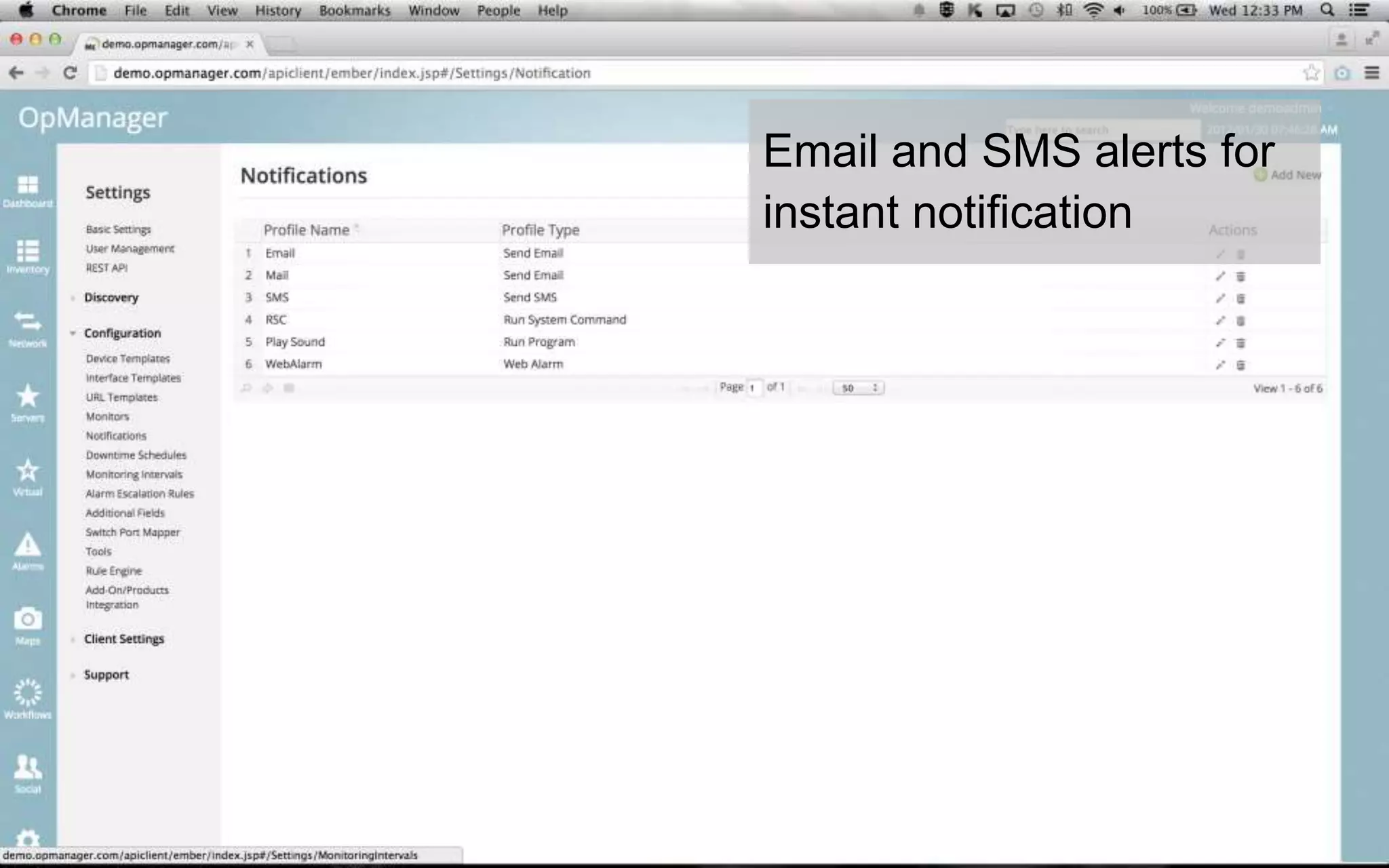
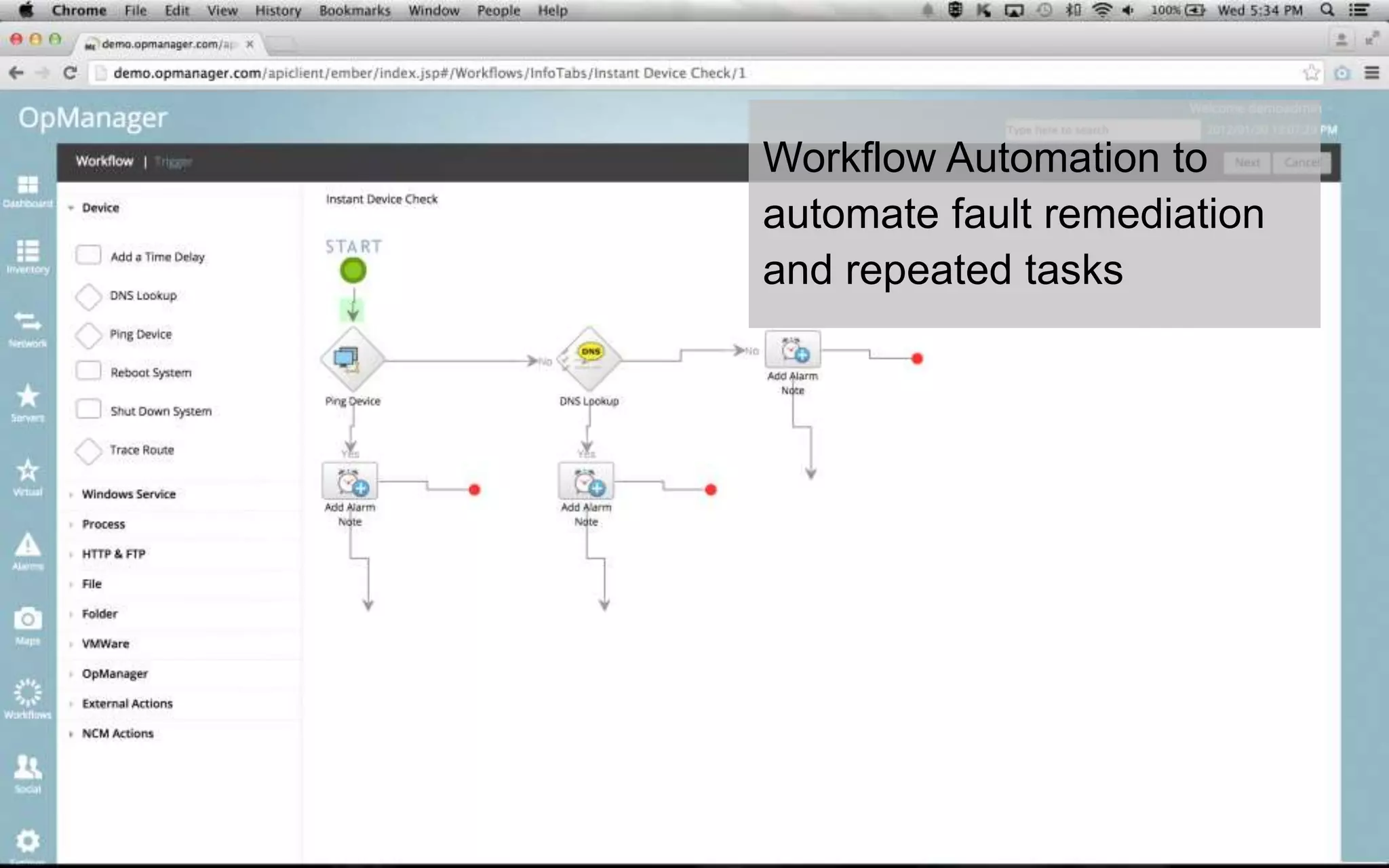
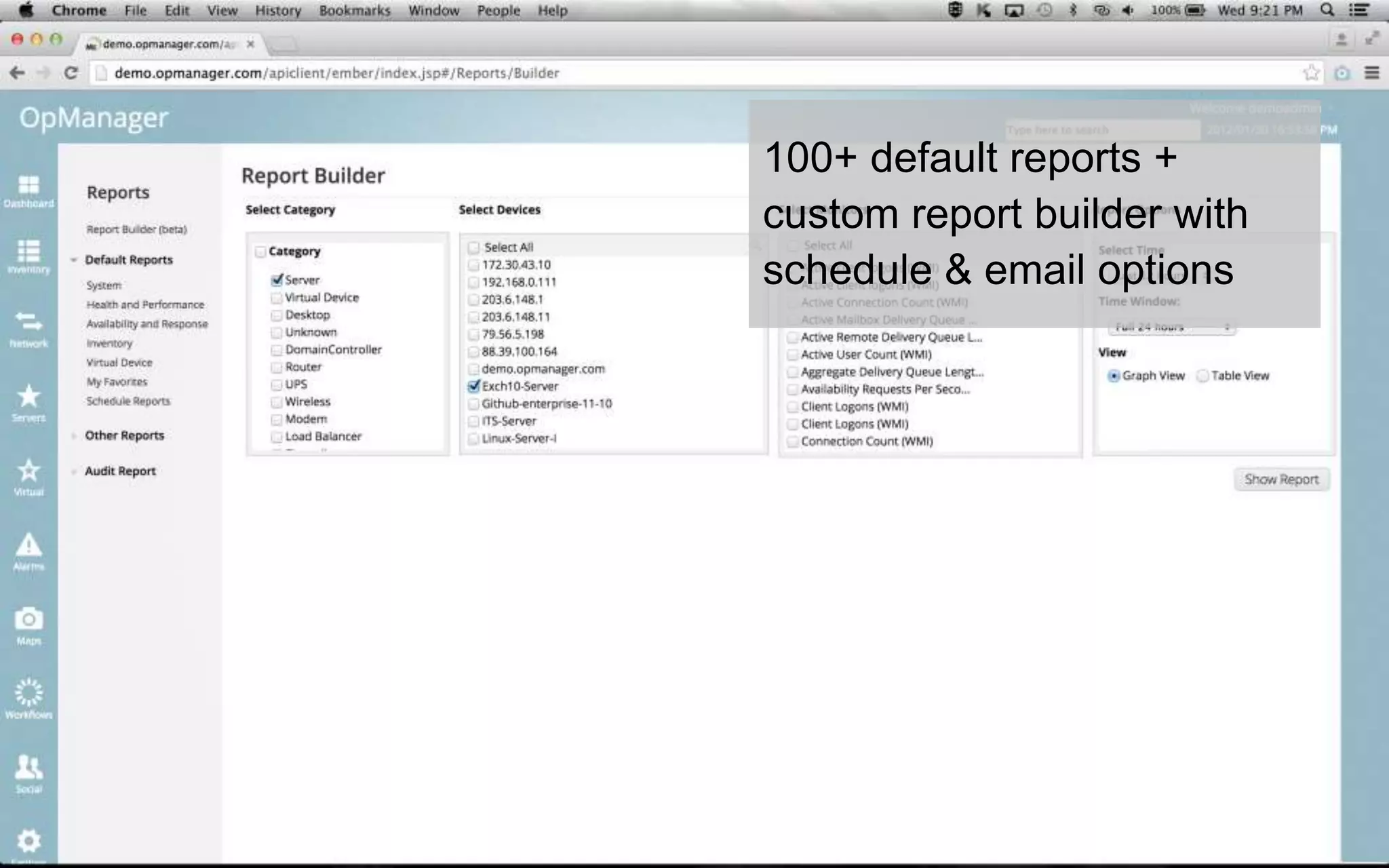
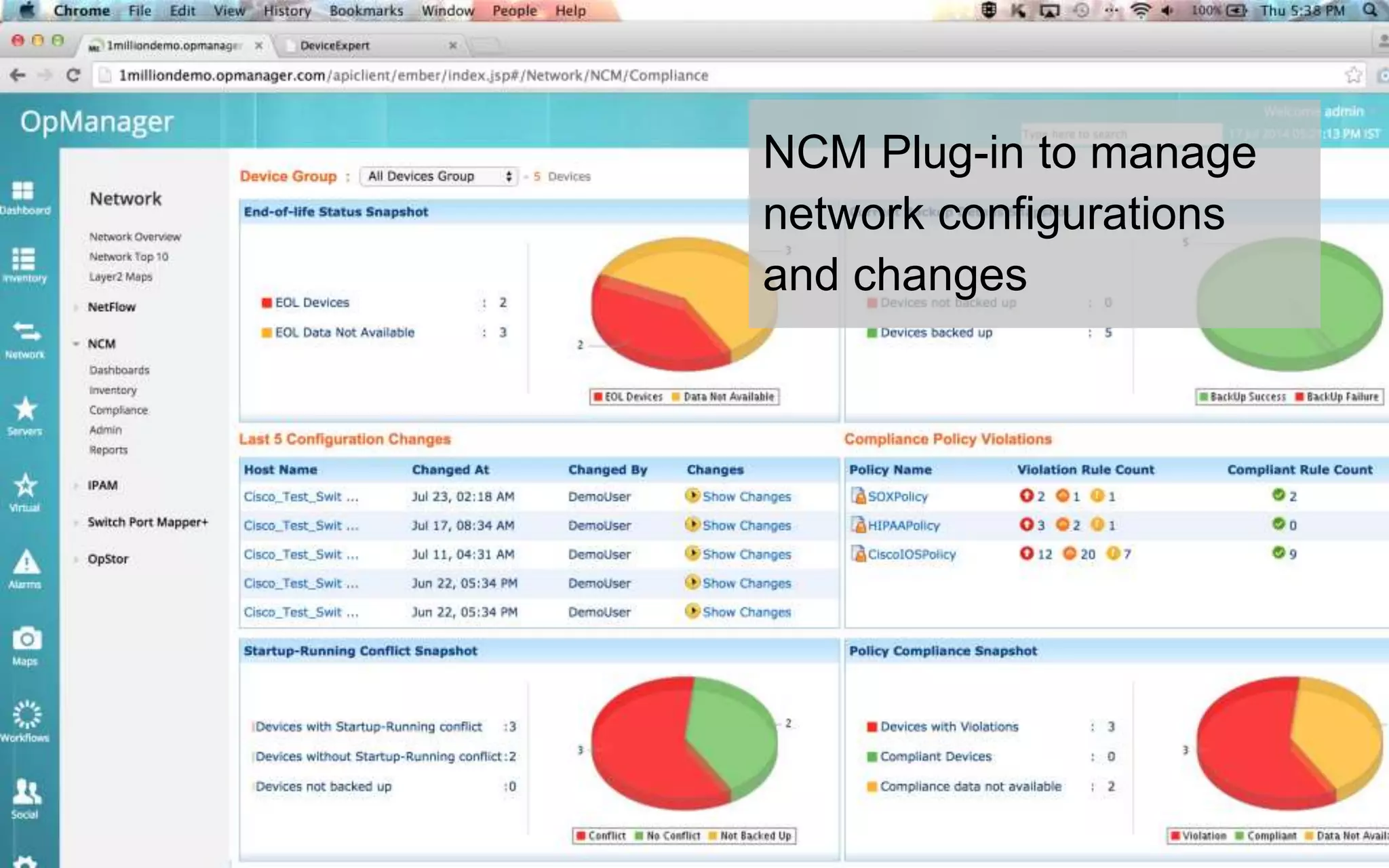

A leading healthcare provider in New Jersey has transitioned to using OpManager for monitoring 2,500 network devices and servers, replacing CA Spectrum due to its complexity and inefficiency. OpManager provides 24/7 access to IT services for doctors, features intuitive setup, tight integration of configuration management and performance monitoring, and comprehensive monitoring capabilities. The software supports various systems and offers proactive monitoring, alerts, workflow automation, and customizable reporting tools.






















































![Season 4 [Free OpManager training] Part2- Monitoring Server Performance](https://cdn.slidesharecdn.com/ss_thumbnails/part2servermonitoring-180719092630-thumbnail.jpg?width=640&height=640&fit=bounds)









































