Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Cloudera Japan
2,471 views
Lars George HBase Seminar with O'REILLY Oct.12 2012
2012年10月12日 オライリー社と共催したセミナー HBase本出版イベントでのLars Georgeの資料です。
Read more
10
Save
Share
Embed
Embed presentation
Download
Downloaded 56 times
1
/ 41
2
/ 41
3
/ 41
4
/ 41
5
/ 41
6
/ 41
7
/ 41
8
/ 41
9
/ 41
10
/ 41
11
/ 41
12
/ 41
13
/ 41
14
/ 41
15
/ 41
16
/ 41
17
/ 41
18
/ 41
19
/ 41
20
/ 41
21
/ 41
22
/ 41
23
/ 41
24
/ 41
25
/ 41
26
/ 41
27
/ 41
28
/ 41
29
/ 41
30
/ 41
31
/ 41
32
/ 41
33
/ 41
34
/ 41
35
/ 41
36
/ 41
37
/ 41
38
/ 41
39
/ 41
40
/ 41
41
/ 41
More Related Content
PDF
刊行記念セミナー「HBase徹底入門」
by
cyberagent
PDF
PHPで大規模ブラウザゲームを開発してわかったこと
by
Kentaro Matsui
PDF
File Server on Azure IaaS
by
junichi anno
PPTX
HBase×Impalaで作るアドテク 「GMOプライベートDMP」@HBaseMeetupTokyo2015Summer
by
Michio Katano
PPTX
初心者向け負荷軽減のはなし
by
Oonishi Takaaki
PDF
スケーラブルなシステムのためのHBaseスキーマ設計 #hcj13w
by
Cloudera Japan
PPTX
100億超メッセージ/日のサービスを 支えるHBase運用におけるチャレンジ
by
LINE Corporation
PPTX
Windows Azure Storage:Best Practices and Internals
by
Takekazu Omi
刊行記念セミナー「HBase徹底入門」
by
cyberagent
PHPで大規模ブラウザゲームを開発してわかったこと
by
Kentaro Matsui
File Server on Azure IaaS
by
junichi anno
HBase×Impalaで作るアドテク 「GMOプライベートDMP」@HBaseMeetupTokyo2015Summer
by
Michio Katano
初心者向け負荷軽減のはなし
by
Oonishi Takaaki
スケーラブルなシステムのためのHBaseスキーマ設計 #hcj13w
by
Cloudera Japan
100億超メッセージ/日のサービスを 支えるHBase運用におけるチャレンジ
by
LINE Corporation
Windows Azure Storage:Best Practices and Internals
by
Takekazu Omi
What's hot
PDF
Couchbase server入門
by
Yusuke Komatsu
PDF
20分でわかるHBase
by
Sho Shimauchi
PPTX
Windows azureを知ろう ロール&ストレージ編
by
Chiho Otonashi
PDF
20130413 JAWS-UG北陸 美人CDP
by
真吾 吉田
PDF
20130330 JAWS-UG広島 美人CDP
by
真吾 吉田
PDF
Osc2012 spring HBase Report
by
Seiichiro Ishida
PDF
HBaseCon 2012 参加レポート
by
NTT DATA OSS Professional Services
PDF
MySQL カジュアル 福岡 03
by
Aya Komuro
PDF
今日から使えるCouchbaseシステムアーキテクチャデザインパターン集
by
Couchbase Japan KK
PPTX
AmazonのDNSサービス Amazon Route 53の使いかたと裏側
by
Yasuhiro Araki, Ph.D
PDF
HBaseを用いたグラフDB「Hornet」の設計と運用
by
Toshihiro Suzuki
PPTX
Couchbase 101 ja
by
Couchbase Japan KK
PDF
JBoss AS7 rev2
by
nekop
PDF
なぜApache HBaseを選ぶのか? #cwt2013
by
Cloudera Japan
PDF
Lampで作るソーシャルアプリの負荷対策~アプリとインフラの調和のテクニック~
by
KLab株式会社
PDF
目指せ1秒切り!ECサイト表示高速化のワザ
by
Kohei MATSUSHITA
PDF
Guide to Cassandra for Production Deployments
by
smdkk
PDF
Awsを学ぶ上で必要となる前提知識(DNS/LB)
by
聡 大久保
Couchbase server入門
by
Yusuke Komatsu
20分でわかるHBase
by
Sho Shimauchi
Windows azureを知ろう ロール&ストレージ編
by
Chiho Otonashi
20130413 JAWS-UG北陸 美人CDP
by
真吾 吉田
20130330 JAWS-UG広島 美人CDP
by
真吾 吉田
Osc2012 spring HBase Report
by
Seiichiro Ishida
HBaseCon 2012 参加レポート
by
NTT DATA OSS Professional Services
MySQL カジュアル 福岡 03
by
Aya Komuro
今日から使えるCouchbaseシステムアーキテクチャデザインパターン集
by
Couchbase Japan KK
AmazonのDNSサービス Amazon Route 53の使いかたと裏側
by
Yasuhiro Araki, Ph.D
HBaseを用いたグラフDB「Hornet」の設計と運用
by
Toshihiro Suzuki
Couchbase 101 ja
by
Couchbase Japan KK
JBoss AS7 rev2
by
nekop
なぜApache HBaseを選ぶのか? #cwt2013
by
Cloudera Japan
Lampで作るソーシャルアプリの負荷対策~アプリとインフラの調和のテクニック~
by
KLab株式会社
目指せ1秒切り!ECサイト表示高速化のワザ
by
Kohei MATSUSHITA
Guide to Cassandra for Production Deployments
by
smdkk
Awsを学ぶ上で必要となる前提知識(DNS/LB)
by
聡 大久保
Viewers also liked
PDF
Database smells
by
Mikiya Okuno
ODP
Data analytics with hadoop hive on multiple data centers
by
Hirotaka Niisato
PPTX
Writing Yarn Applications Hadoop Summit 2012
by
Hortonworks
PDF
20120830 DBリファクタリング読書会第三回
by
都元ダイスケ Miyamoto
PDF
【17-E-3】 オンライン機械学習で実現する大規模データ処理
by
Developers Summit
PDF
Cloudera Manager4.0とNameNode-HAセミナー資料
by
Cloudera Japan
PPTX
Future of HCatalog - Hadoop Summit 2012
by
Hortonworks
PDF
PostgreSQLの実行計画を読み解こう(OSC2015 Spring/Tokyo)
by
Satoshi Yamada
PDF
並列データベースシステムの概念と原理
by
Makoto Yui
PDF
あなたの知らないPostgreSQL監視の世界
by
Yoshinori Nakanishi
KEY
Hadoop Summit 2012 - Hadoop and Vertica: The Data Analytics Platform at Twitter
by
Bill Graham
PDF
【SQLインジェクション対策】徳丸先生に怒られない、動的SQLの安全な組み立て方
by
kwatch
PPTX
SQLチューニング入門 入門編
by
Miki Shimogai
PDF
Datalogからsqlへの トランスレータを書いた話
by
Yuki Takeichi
PPTX
ならば(その弐)
by
Tomoaki Hiramoto
PPTX
PostgreSQLクエリ実行の基礎知識 ~Explainを読み解こう~
by
Miki Shimogai
Database smells
by
Mikiya Okuno
Data analytics with hadoop hive on multiple data centers
by
Hirotaka Niisato
Writing Yarn Applications Hadoop Summit 2012
by
Hortonworks
20120830 DBリファクタリング読書会第三回
by
都元ダイスケ Miyamoto
【17-E-3】 オンライン機械学習で実現する大規模データ処理
by
Developers Summit
Cloudera Manager4.0とNameNode-HAセミナー資料
by
Cloudera Japan
Future of HCatalog - Hadoop Summit 2012
by
Hortonworks
PostgreSQLの実行計画を読み解こう(OSC2015 Spring/Tokyo)
by
Satoshi Yamada
並列データベースシステムの概念と原理
by
Makoto Yui
あなたの知らないPostgreSQL監視の世界
by
Yoshinori Nakanishi
Hadoop Summit 2012 - Hadoop and Vertica: The Data Analytics Platform at Twitter
by
Bill Graham
【SQLインジェクション対策】徳丸先生に怒られない、動的SQLの安全な組み立て方
by
kwatch
SQLチューニング入門 入門編
by
Miki Shimogai
Datalogからsqlへの トランスレータを書いた話
by
Yuki Takeichi
ならば(その弐)
by
Tomoaki Hiramoto
PostgreSQLクエリ実行の基礎知識 ~Explainを読み解こう~
by
Miki Shimogai
Similar to Lars George HBase Seminar with O'REILLY Oct.12 2012
PPTX
Cloudera大阪セミナー 20130219
by
Cloudera Japan
PPT
081108huge_data.ppt
by
Naoya Ito
PDF
Hadoop operation chaper 4
by
Yukinori Suda
PDF
Facebookのリアルタイム Big Data 処理
by
maruyama097
PDF
【Hpcstudy】みんな、ベンチマークどうやってるの?
by
Seiichiro Ishida
PDF
Hadoop, NoSQL, GlusterFSの概要
by
日本ヒューレット・パッカード株式会社
PDF
HBase活用事例 #hbase_ca
by
Cloudera Japan
PDF
HBase Across the World #LINE_DM
by
Cloudera Japan
PDF
Amazon EC2 HPCインスタンス - AWSマイスターシリーズ
by
Amazon Web Services Japan
PDF
20120117 13 meister-elasti_cache-public
by
Amazon Web Services Japan
KEY
NHN techcon-20120519-fujimoto
by
Masaki Fujimoto
PDF
HBase Meetup Tokyo Summer 2015 #hbasejp
by
Cloudera Japan
PPTX
Hadoopソースコードリーディング8/MapRを使ってみた
by
Recruit Technologies
PDF
20121205 nosql(okuyama fs)セミナー資料
by
Takahiro Iwase
PDF
Amazon ElastiCache - AWSマイスターシリーズ
by
SORACOM, INC
PDF
We Should Know About in this SocialNetwork Era 2011_1112
by
Masahito Zembutsu
PDF
Apache Kuduは何がそんなに「速い」DBなのか? #dbts2017
by
Cloudera Japan
PPTX
HBaseサポート最前線 #hbase_ca
by
Cloudera Japan
PDF
「新製品 Kudu 及び RecordServiceの概要」 #cwt2015
by
Cloudera Japan
PDF
クラウドセキュリティ基礎
by
Masahiro NAKAYAMA
Cloudera大阪セミナー 20130219
by
Cloudera Japan
081108huge_data.ppt
by
Naoya Ito
Hadoop operation chaper 4
by
Yukinori Suda
Facebookのリアルタイム Big Data 処理
by
maruyama097
【Hpcstudy】みんな、ベンチマークどうやってるの?
by
Seiichiro Ishida
Hadoop, NoSQL, GlusterFSの概要
by
日本ヒューレット・パッカード株式会社
HBase活用事例 #hbase_ca
by
Cloudera Japan
HBase Across the World #LINE_DM
by
Cloudera Japan
Amazon EC2 HPCインスタンス - AWSマイスターシリーズ
by
Amazon Web Services Japan
20120117 13 meister-elasti_cache-public
by
Amazon Web Services Japan
NHN techcon-20120519-fujimoto
by
Masaki Fujimoto
HBase Meetup Tokyo Summer 2015 #hbasejp
by
Cloudera Japan
Hadoopソースコードリーディング8/MapRを使ってみた
by
Recruit Technologies
20121205 nosql(okuyama fs)セミナー資料
by
Takahiro Iwase
Amazon ElastiCache - AWSマイスターシリーズ
by
SORACOM, INC
We Should Know About in this SocialNetwork Era 2011_1112
by
Masahito Zembutsu
Apache Kuduは何がそんなに「速い」DBなのか? #dbts2017
by
Cloudera Japan
HBaseサポート最前線 #hbase_ca
by
Cloudera Japan
「新製品 Kudu 及び RecordServiceの概要」 #cwt2015
by
Cloudera Japan
クラウドセキュリティ基礎
by
Masahiro NAKAYAMA
More from Cloudera Japan
PPTX
Impala + Kudu を用いたデータウェアハウス構築の勘所 (仮)
by
Cloudera Japan
PPTX
機械学習の定番プラットフォームSparkの紹介
by
Cloudera Japan
PPTX
HDFS Supportaiblity Improvements
by
Cloudera Japan
PDF
分散DB Apache Kuduのアーキテクチャ DBの性能と一貫性を両立させる仕組み 「HybridTime」とは
by
Cloudera Japan
PDF
Apache Impalaパフォーマンスチューニング #dbts2018
by
Cloudera Japan
PDF
Apache Hadoop YARNとマルチテナントにおけるリソース管理
by
Cloudera Japan
PDF
Cloudera のサポートエンジニアリング #supennight
by
Cloudera Japan
PDF
Train, predict, serve: How to go into production your machine learning model
by
Cloudera Japan
PDF
Apache Kuduを使った分析システムの裏側
by
Cloudera Japan
PDF
Cloudera in the Cloud #CWT2017
by
Cloudera Japan
PDF
先行事例から学ぶ IoT / ビッグデータの始め方
by
Cloudera Japan
PPTX
Clouderaが提供するエンタープライズ向け運用、データ管理ツールの使い方 #CW2017
by
Cloudera Japan
PDF
How to go into production your machine learning models? #CWT2017
by
Cloudera Japan
PDF
Apache Kudu - Updatable Analytical Storage #rakutentech
by
Cloudera Japan
PPTX
Hue 4.0 / Hue Meetup Tokyo #huejp
by
Cloudera Japan
PDF
Cloudera Data Science WorkbenchとPySparkで 好きなPythonライブラリを 分散で使う #cadeda
by
Cloudera Japan
PDF
Cloudera + MicrosoftでHadoopするのがイイらしい。 #CWT2016
by
Cloudera Japan
PDF
Cloud Native Hadoop #cwt2016
by
Cloudera Japan
PDF
大規模データに対するデータサイエンスの進め方 #CWT2016
by
Cloudera Japan
PDF
#cwt2016 Apache Kudu 構成とテーブル設計
by
Cloudera Japan
Impala + Kudu を用いたデータウェアハウス構築の勘所 (仮)
by
Cloudera Japan
機械学習の定番プラットフォームSparkの紹介
by
Cloudera Japan
HDFS Supportaiblity Improvements
by
Cloudera Japan
分散DB Apache Kuduのアーキテクチャ DBの性能と一貫性を両立させる仕組み 「HybridTime」とは
by
Cloudera Japan
Apache Impalaパフォーマンスチューニング #dbts2018
by
Cloudera Japan
Apache Hadoop YARNとマルチテナントにおけるリソース管理
by
Cloudera Japan
Cloudera のサポートエンジニアリング #supennight
by
Cloudera Japan
Train, predict, serve: How to go into production your machine learning model
by
Cloudera Japan
Apache Kuduを使った分析システムの裏側
by
Cloudera Japan
Cloudera in the Cloud #CWT2017
by
Cloudera Japan
先行事例から学ぶ IoT / ビッグデータの始め方
by
Cloudera Japan
Clouderaが提供するエンタープライズ向け運用、データ管理ツールの使い方 #CW2017
by
Cloudera Japan
How to go into production your machine learning models? #CWT2017
by
Cloudera Japan
Apache Kudu - Updatable Analytical Storage #rakutentech
by
Cloudera Japan
Hue 4.0 / Hue Meetup Tokyo #huejp
by
Cloudera Japan
Cloudera Data Science WorkbenchとPySparkで 好きなPythonライブラリを 分散で使う #cadeda
by
Cloudera Japan
Cloudera + MicrosoftでHadoopするのがイイらしい。 #CWT2016
by
Cloudera Japan
Cloud Native Hadoop #cwt2016
by
Cloudera Japan
大規模データに対するデータサイエンスの進め方 #CWT2016
by
Cloudera Japan
#cwt2016 Apache Kudu 構成とテーブル設計
by
Cloudera Japan
Lars George HBase Seminar with O'REILLY Oct.12 2012
1.
HBASE IN JAPAN Overview,
Current Status and Future Lars George Director EMEA Services
2.
自己紹介 • Cloudera EMEAのディレクター
• 全地域におけるHadoopプロジェクトのコンサルタント • Apacheのコミッター • HbaseとWhirr • O’Reilly 書籍の著者 Hbase -The Definitive Guide • 日本語版も販売中! • 連絡先 • lars@cloudera.com • @larsgeorge 日本語版も出ました!
3.
アジェンダ • HBaseの紹介 • プロジェクトの現状 •
クラスタのサイジング
4.
HBASEの紹介
5.
HBaseとは? • 分散 • 列指向 •
多次元 • 高可用性 • 高パフォーマンス • ストレージシステム プロジェクトの目的 数十億の行 * 数百万の列 * 数千のバージョン 数千のコモディティサーバを通じ、ペタバイトのデータ量を処理
6.
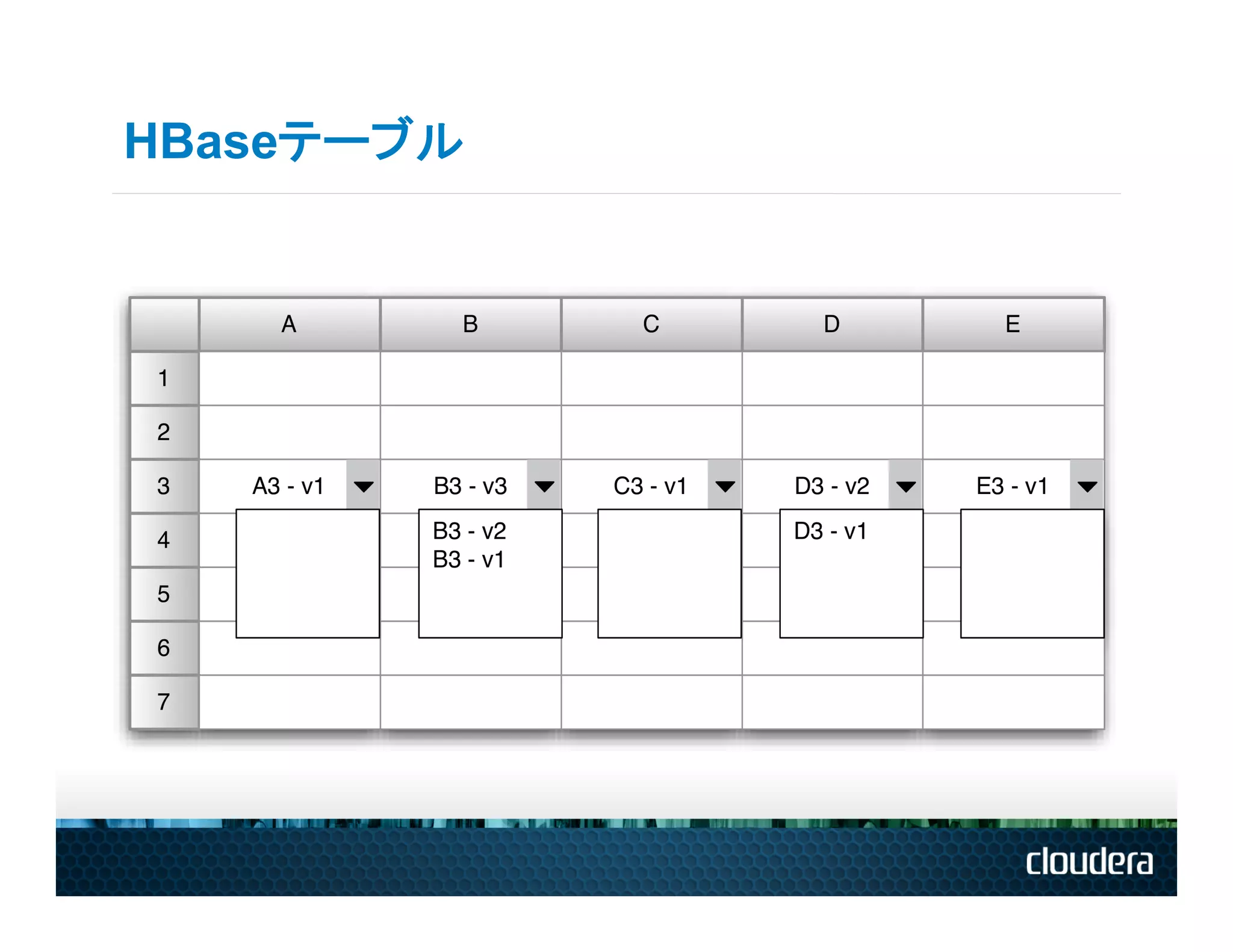
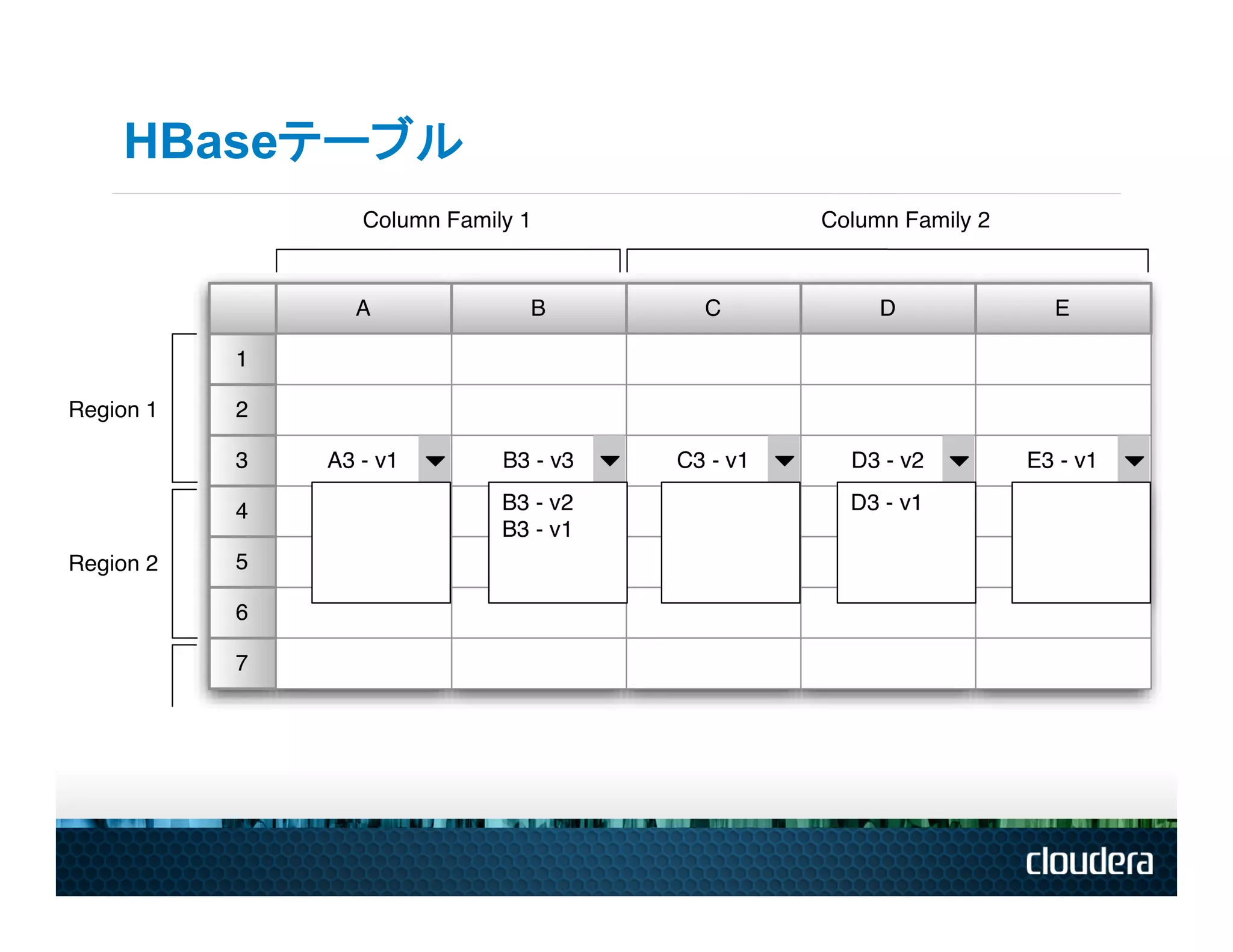
HBaseテーブル
7.
HBaseテーブル
8.
HBase テーブル
9.
HBaseテーブル
10.
HBaseテーブル
11.
HBaseテーブル
12.
HBaseテーブル
13.
HBaseのテーブルとは • テーブルは行の辞書順(アルファベット順)でソートされている • テーブルスキーマは、列ファミリを定義するのみ
• それぞれの列ファミリは、任意の列の数で構成 • それぞれの列は、任意の数のバージョンで構成 • それぞれの列は、挿入時のみに存在 • 一つの列ファミリ内の列は、一緒にソート・格納 • テーブル名を除くすべてはbyte[] (テーブル、行、列ファミリ:列、タイムスタンプ)->値
14.
Java API • CRUD
• get: 行全体または部分から値を引き出す (R) • put: 行の生成と更新 (CU) • delete: セル、1列、複数列または行の削除 (D) Result get(Get get) throws IOException; void put(Put put) throws IOException; void delete(Delete delete) throws IOException;
15.
Java API (続き) •
CRUD+SI • scan: 任意の行の数をスキャン (S) • increment: 列の値をインクリメント (I) ResultScanner getScanner(Scan scan) throws IOException; Result increment(Increment increment) throws IOException ;
16.
Java API (続き) •
CRUD+SI+CAS • アトミックのコンペア・アンド・スワップ (CAS) • get、check、put操作の組み合わせ • 完全なトランザクション機能がないことを補う
17.
その他の特徴 • I/Oを効率よく利用するバッチ操作 • プッシュダウン式に述部処理するフィルタ
• 強力なコンパレータを用いた行キーや列名のフィルタ • 圧縮アルゴリズムの選択 • ブルームフィルタと時間ベースのストアファイル選択 • アトミックな追記とputs+deletes • マルチオペレーション • サーバーサイドのカスタムコードサポート • …
18.
プロジェクトの状況
19.
最近のプロジェクトの状況 • HBase 0.90.x
“進化した概念” • マスターの書き直し – Zookeeper を超える • 行の中でのスキャニング • アルゴリズムとデータ構造のさらなる最適化 CDH3 • HBase 0.92.x “コプロセッサ” • マルチデータセンタレプリケーション • 任意のアクセス制御 • コプロセッサ CDH4
20.
最近のプロジェクトの状況(続) • HBase 0.94.x
“パフォーマンスリリース” • CRC読み込みの改善 • シークの最適化 • WAL圧縮 • プレフィックス圧縮(別名:ブロックエンコーディング) • アトミックな追記 • アトミック put+delete • マルチインクリメントとマルチアペンド • リージョンごとの(つまりローカルの) 複数行トランザクション • WALPlayer CDH4.x (間もなくリリース)
21.
最近のプロジェクトの状況(続) • HBase 0.96.x
“特異性” • Protobuf RPC • ローリングアップグレード • 複数バージョンのアクセス • Metrics V2 • プレビュー技術 • スナップショット • PrefixTrieブロックエンコーディング CDH5 ?
22.
クラスタのサイジング
23.
リソースの競合 • 読み込み・書き出しで同じ低レベルリソースを
奪い合う • ディスク (HDFS) とネットワークI/O • RPCハンドラとスレッド • そのほか、完全に別々のコードパスを実行
24.
メモリの共有 • デフォルトでは、各リージョンサーバは(与えられ
る最大量の)メモリを次のように割り当てる • 40%をインメモリストア (write ops) • 20%をブロックキャッシング (reads ops) • 残りの領域(ここでは40%)を、オブジェクトなど一般的な Java heapの利用にあてる • メモリの共有には微調整が必要
25.
Reads • リージョンサーバの適切な配置とリクエストの配分
• より高速な検索のためのクライアントのキャッシュ情報 • クライアントはより高速なルックアップのため情報を キャッシュする➜ 高速ウォームアップのための先読みオ プションを考慮 • 可能ならば、時間の範囲指定かブルームフィルタ を利用してストアファイルを削除 • ブロックキャッシュを試し、もしブロックが見つから なければディスクから読み込む
26.
ブロックキャッシュ • ブロックキャッシュの有効性を確認するため、
出力しているメトリクスを使用 • ヒット率と同時に、排除率を満たしているか 確認 ➜ ランダムリードは理想的ではない • 必要に応じて増減させて微調整するが、ヒープ の全体的な使用量を監視すること • ブロックキャッシュは絶対に必要 • 短時間でのメリットがあるので、少なくとも 10%に設定
27.
書き込み • クラスタサイズは、書き込みパフォーマンスによって 決定されることが多い •
Log structured merge tree ベース • 変更処理をインメモリストアと先行書き込みログ (WAL)の両方に格納 • 負荷が高いとき、一定のしきい値に基づき集約さ れたソートマップをフラッシュする • ペンディング状態の変更がないログは破棄 • ストアファイルの定期的なコンパクションを実行
28.
書き込みのパフォーマンス • クラスタ全体の書き込みパフォーマンスにある多
数のファクター • クラスタ全体の書き込みパフォーマンスに影響す る様々な要因 • キーの分散 ➜ リージョンのホットスポットを回避 • ハンドラ ➜ すぐに枯渇しないようにする • 先行書き込みログ ➜ 第一のボトルネック • コンパクション ➜ 間違ったチューニングは、増加し続け るバックグラウンドノイズの原因に
29.
先行書き込みログ(WAL) • 現在のところ、リージョンサーバに1つ
• 全ストア(列ファミリ)間で共有 • ファイル追記の呼び出しで同期 • 次のようなことを緩和するために実行 • WALの負荷軽減のため以下の機能を追加 • WAL圧縮 • リージョンサーバにつき複数のWAL ➜ ノードごとに複数 のリージョンサーバを起動する?
30.
先行書き込みログ(WAL)-続き • デフォルトのブロックサイズの95%にサイズ設定
• 64MB または 128MB、configを確認! • 復旧時間を削減するため、低い数字を保持 • リミットは32まで、増加させることは可能 • ログサイズを大きくするとともにブロッキング前の ログの数を増やす(あるいはどちらか) • 書き込みの分布及びフラッシュの頻度に基づき数 値を計算
31.
先行書き込みログ(WAL)-続き • 書き込みは全ストア間で同期させる •
1つの列ファミリに巨大なセルがあると、ほかの書き込み すべてが停止する • この場合RPCハンドラは、動くか全てブロックされるかの 二択になる • 書き込み時にWALを回避することができるが、これは本当 の耐障害性やレプリケーションを失うことを意味する • 依存データセットをリストアするため、コプロセッサを利用 することも可能かもしれない (preWALRestore)
32.
フラッシュ • すべての変更のための呼び出し(put、deleteな
ど)は、フラッシュのチェックの原因になる • しきい値に達したら、ディスクへのフラッシュとコン パクションのスケジューリングを行う • 新たにフラッシュされたファイルは、迅速に圧縮すること • コンパクションは、必要ならリージョンを分割すべ き場所に返っていく
33.
コンパクションストーム • ログの数が多すぎる、あるいはメモリ使用量が逼
迫することにより早過ぎるフラッシュが発生する • ファイルは設定されたフラッシュサイズより小さくなる • バックグラウンドでコンパクションを行い、小さいフ ラッシュを大きなストアファイルにマージするのは 大変 • 数百MBのリライトを何度も実行
34.
依存関係 • たった1つのトリガーがあれば、フラッシュは
全ストア/列ファミリ間で起こる • フラッシュサイズは、結合されている全スト アサイズと比較する • 多くの列ファミリはサイズが小さい • 例: 55MB + 5MB + 4MB
35.
数値について • 一般的なHDFSの書き込みパフォーマンス
は 35-50MB/秒 Cell Size OPS 0.5MB 70-100 100KB 350-500 10KB 3500-5000 ?? 1KB 35000-50000 ???? 競争こそ、実際に高みに至る道!
36.
もう少し数字を書く •
速度が低い現実の状況下では、15MB/秒 かそれ以下 • スレッドによるリソースの奪い合いは、大規模な 速度低下の原因になる Cell Size OPS 0.5MB 10 100KB 100 10KB 800 1KB 6000
37.
注釈 • リージョンXのフラッシュサイズに基づき、
memstoreサイズを計算 • フィルおよびフラッシュの比率に基づき、保存する ログの数を計算 • 最終的に、容量は次で決定される • Java Heap • リージョン数とサイズ • キーの分散
38.
Cheat Sheet #1
• 先行書き込みログの実行に十分以上の性能があ ることを確認 • 利用できるメムストア領域の許容範囲を超えてク ライアントが利用しないことを確認 • フラッシュサイズを大きく設定してもいいが、大き 過ぎないことを確認 • 先行書き込みログの使用状況を注意して監視
39.
Cheat Sheet #2
• 1ノードにつき、より多くのデータを格納できるよう 圧縮を有効にする • いくつかのレベルでバックグラウンドI/Oを固定す るため、コンパクションアルゴリズムを変更 • 別のテーブルに不均一のカラムファミリを置くこと を考慮 • ブロックキャッシュ、メムストアやすべてのキュー のメトリクスを慎重にチェック
40.
例 • 10GBのJava Xmx
heap • メムストアは40%使う(デフォルト) • 10GB Heap x 0.4 = 4GB • 推奨するフラッシュサイズは128MB • 4GB / 128MB = 最大 32 リージョン! • WALサイズは 128MB x 0.95% • 4GB / (128MB x 0.95) = ~33 部分的にコミットできないログ の最大保持量 • 20GBのリージョンサイズ • 20GB x 32リージョン = 640GBの生ストレージを使用
41.
Thank
ご清聴いただきまして、 You! まことにありがとうございました +1 (3) 6228-7930 cloudera.com twi1er.com/ Sales-jp@cloudera.com cloudera facebook.com/ cloudera 41
Download









![HBaseのテーブルとは
• テーブルは行の辞書順(アルファベット順)でソートされている
• テーブルスキーマは、列ファミリを定義するのみ
• それぞれの列ファミリは、任意の列の数で構成
• それぞれの列は、任意の数のバージョンで構成
• それぞれの列は、挿入時のみに存在
• 一つの列ファミリ内の列は、一緒にソート・格納
• テーブル名を除くすべてはbyte[]
(テーブル、行、列ファミリ:列、タイムスタンプ)->値](https://image.slidesharecdn.com/hbaseinjapanoct-122012japanese2-121015022350-phpapp01/75/Lars-George-HBase-Seminar-with-O-REILLY-Oct-12-2012-13-2048.jpg)