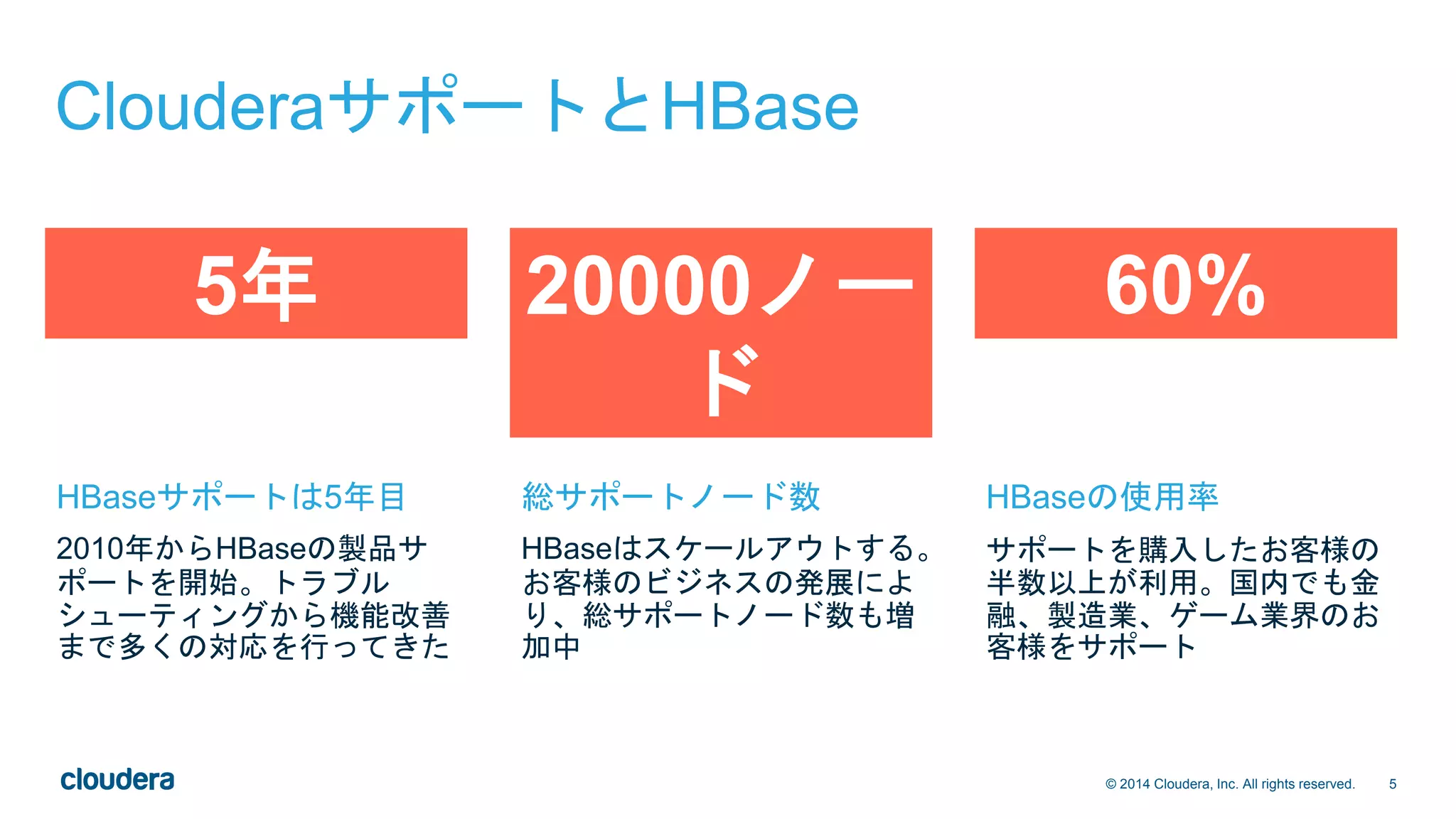
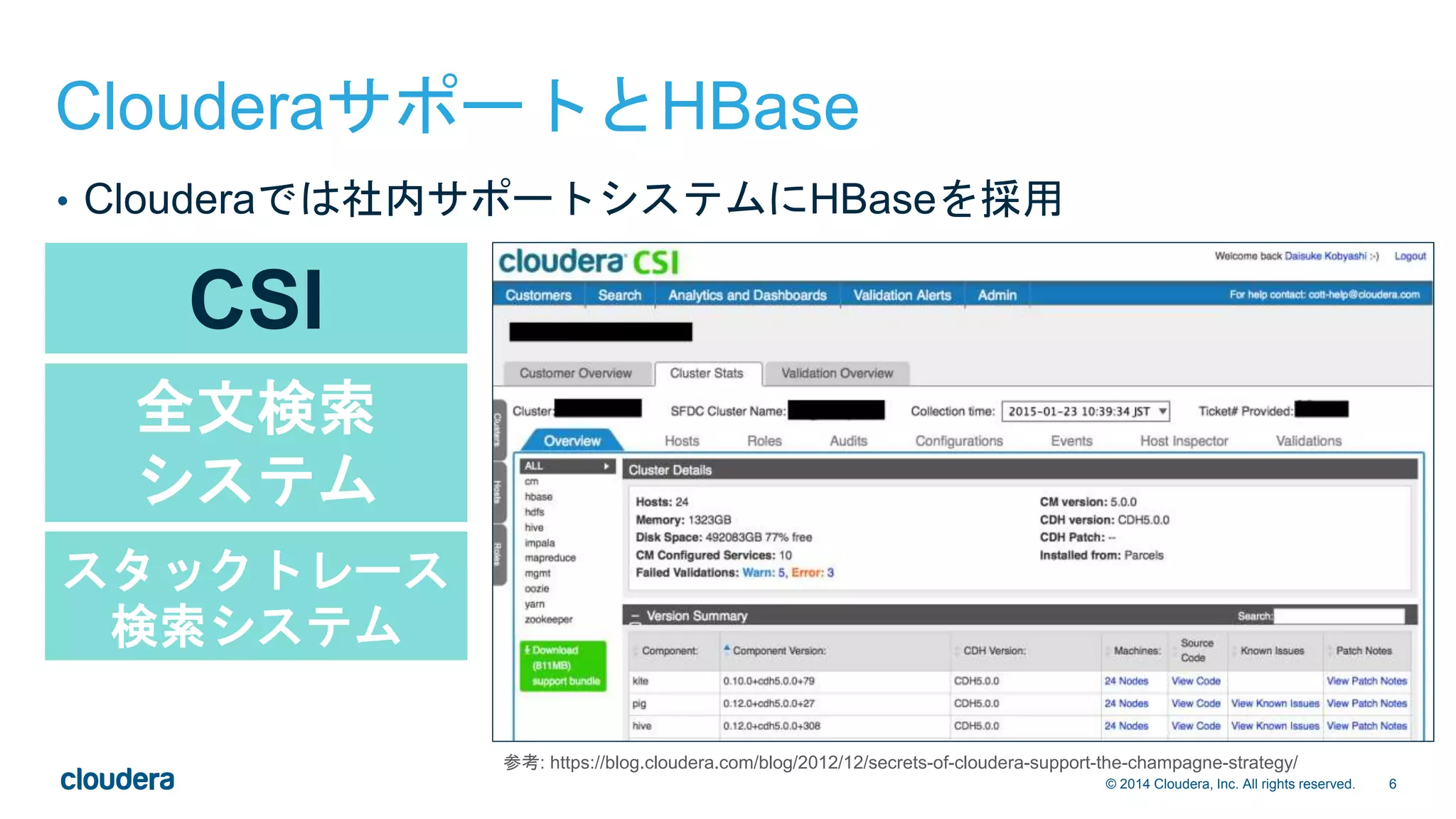
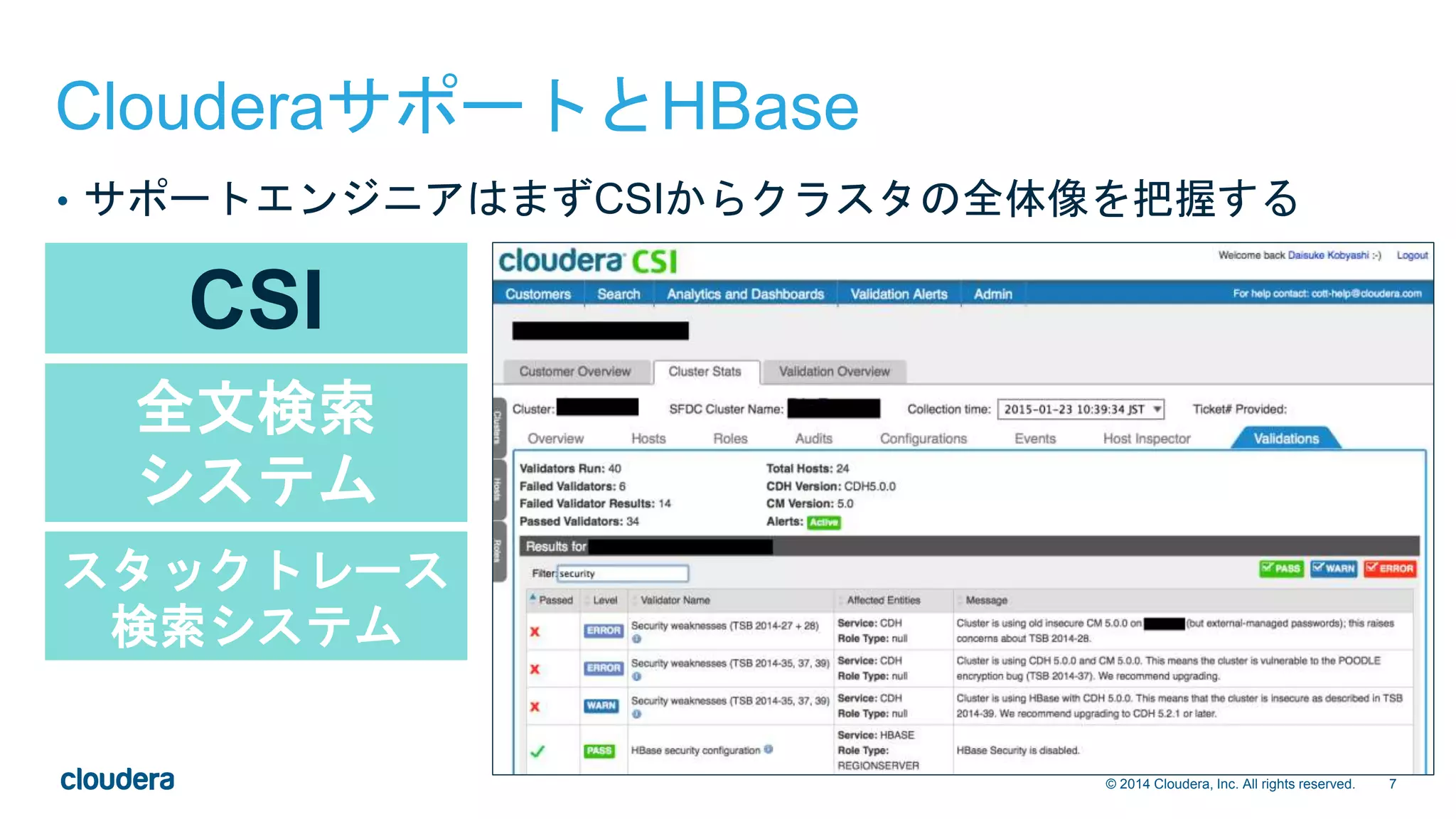
2015/02/02 開催の、HBase徹底入門記念セミナーで発表した資料です。 http://eventregist.com/e/2Hiwrc2WFhyu ClouderaサポートチームとHBaseの関係や、推奨設定、トラブルシューティング例などを紹介しています。




![11© 2014 Cloudera, Inc. All rights reserved.
クラスタ構築時の注意点
• THP(Transparent Huge Page)は無効にする
• 有効になっていると深刻なパフォーマンス劣化を招きます [1]
• リージョン数の見積もり、モニタリングは慎重に
• リージョンが多すぎるとMTTR (Mean Time to Recovery: 平均修復時間)の増加、
パフォーマンス劣化につながります
• HBase徹底入門を読みましょう
• 2015/01時点で最新の情報が網羅されている
• 実際の構築経験をベースに執筆されている
[1] http://www.cloudera.com/content/cloudera/en/documentation/core/latest/topics/cdh_admin_performance.html を確認](https://image.slidesharecdn.com/hbasebookevent20150202-150202210242-conversion-gate02/75/HBase-hbase_ca-11-2048.jpg)




![16© 2014 Cloudera, Inc. All rights reserved.
リージョンスプリットポリシー
• ConstantSizeRegionSplitPolicy
• CDH4.1 (0.92) までのスプリットポリシー
• 一定のサイズに達したリージョンを分割
• IncreasingToUpperBoundRegionSplitPolicy
• CDH4.2 (0.94) 以降でデフォルトのスプリットポリシー
• 以下の条件を比較し、小さい方を上限として採用
1. リージョン数 (同一サーバ上、同一テーブル内) ^ 3 ([2]) * フラッシュサイズ * 2
2. hbase.hregion.max.filesizeの設定値
• リージョンをクラスタ全体へ分散し、パフォーマンスの向上を図ることが目的
• ローリング再起動 (デコミッション) 時にリージョン数が増加する場合あり [3]
[2] CDH5.0以前、5.1以降で算出式が変更されているので注意。詳しくはHBASE-10501
[3] 一時的にリージョン数が減ることが原因。詳しくはHBASE-12451](https://image.slidesharecdn.com/hbasebookevent20150202-150202210242-conversion-gate02/75/HBase-hbase_ca-16-2048.jpg)
![17© 2014 Cloudera, Inc. All rights reserved.
リージョンスプリットポリシー
• ConstantSizeRegionSplitPolicy
• CDH4.1 (0.92) までのスプリットポリシー
• 一定のサイズに達したリージョンを分割
• IncreasingToUpperBoundRegionSplitPolicy
• CDH4.2 (0.94) 以降でデフォルトのスプリットポリシー
• 以下の条件を比較し、小さい方を上限として採用
1. リージョン数 (同一サーバ上、同一テーブル内) ^ 3 ([2]) * フラッシュサイズ * 2
2. hbase.hregion.max.filesizeの設定値
• リージョンをクラスタ全体へ分散し、パフォーマンスの向上を図ることが目的
• ローリング再起動 (デコミッション) 時にリージョン数が増加する場合あり [3]
[2] CDH5.0以前、5.1以降で算出式が変更されているので注意。詳しくはHBASE-10501
[3] 一時的にリージョン数が減ることが原因。詳しくはHBASE-12451](https://image.slidesharecdn.com/hbasebookevent20150202-150202210242-conversion-gate02/75/HBase-hbase_ca-17-2048.jpg)
![18© 2014 Cloudera, Inc. All rights reserved.
リージョンスプリットポリシー
• ConstantSizeRegionSplitPolicy
• CDH4.1 (0.92) までのスプリットポリシー
• 一定のサイズに達したリージョンを分割
• IncreasingToUpperBoundRegionSplitPolicy
• CDH4.2 (0.94) 以降でデフォルトのスプリットポリシー
• 以下の条件を比較し、小さい方を上限として採用
1. リージョン数 (同一サーバ上、同一テーブル内) ^ 3 ([2]) * フラッシュサイズ * 2
2. hbase.hregion.max.filesizeの設定値
• リージョンをクラスタ全体へ分散し、パフォーマンスの向上を図ることが目的
• ローリング再起動 (デコミッション) 時にリージョン数が増加する場合あり [3]
[2] CDH5.0以前、5.1以降で算出式が変更されているので注意。詳しくはHBASE-10501
[3] 一時的にリージョン数が減ることが原因。詳しくはHBASE-12451](https://image.slidesharecdn.com/hbasebookevent20150202-150202210242-conversion-gate02/75/HBase-hbase_ca-18-2048.jpg)



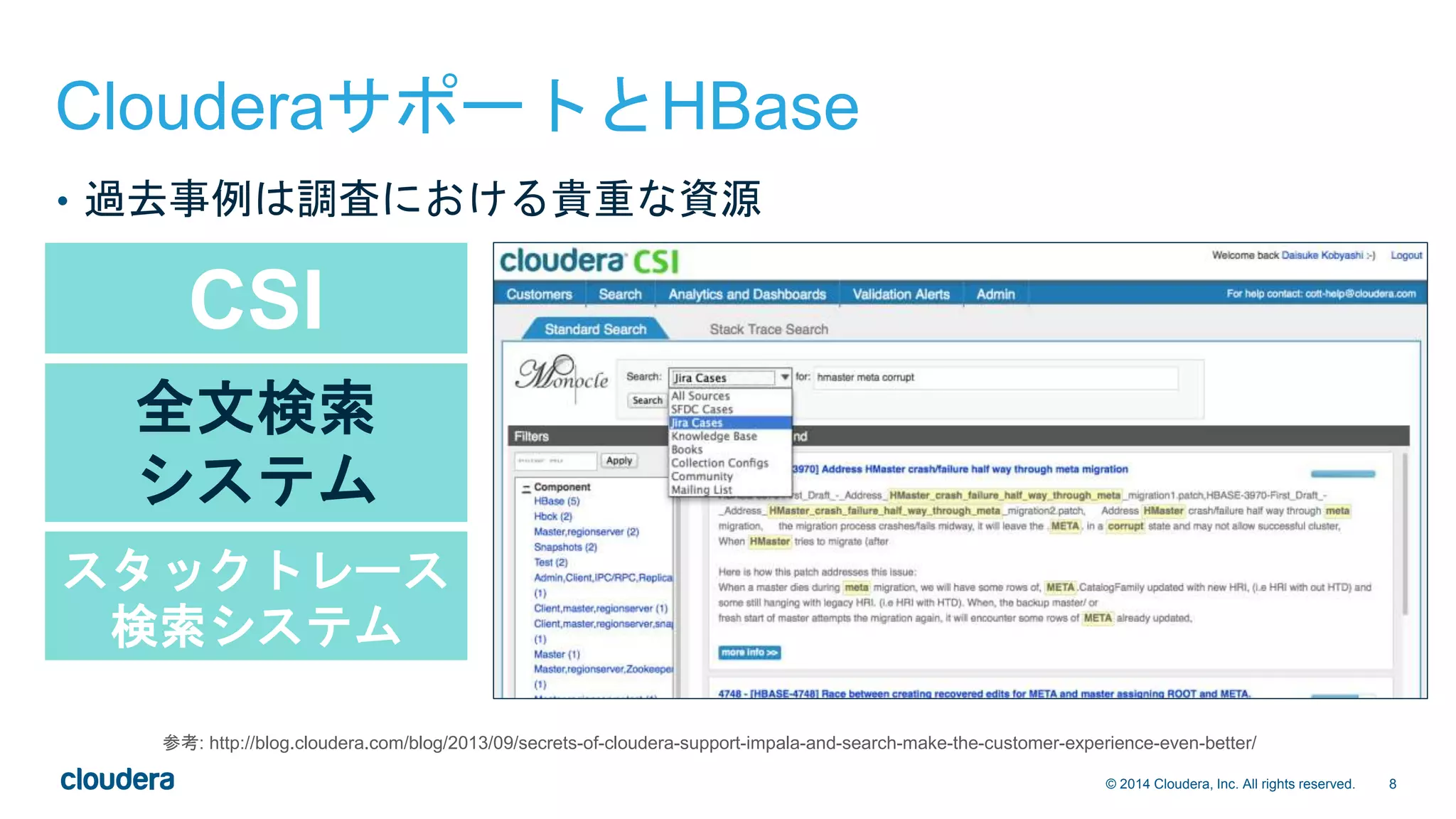
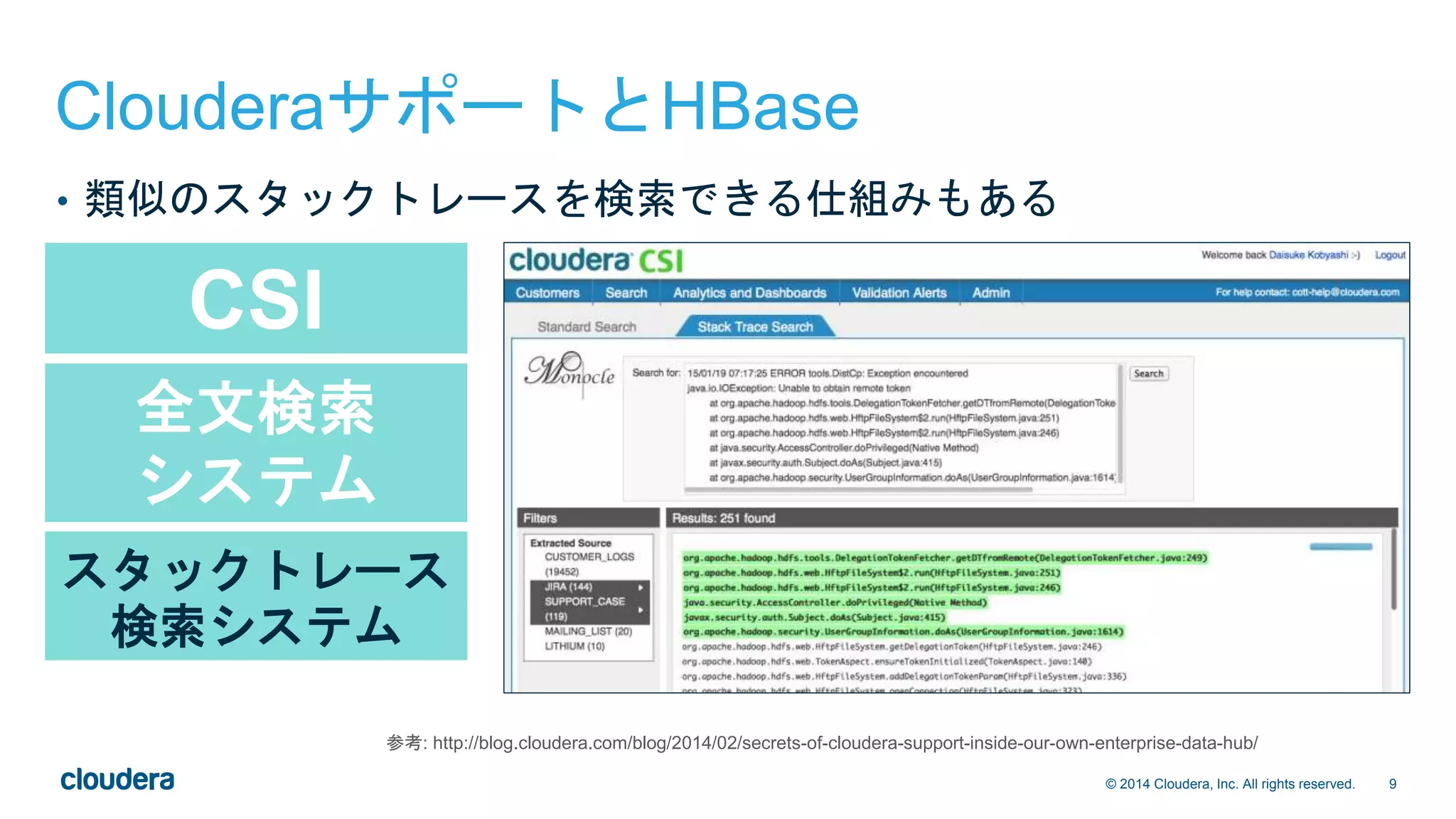
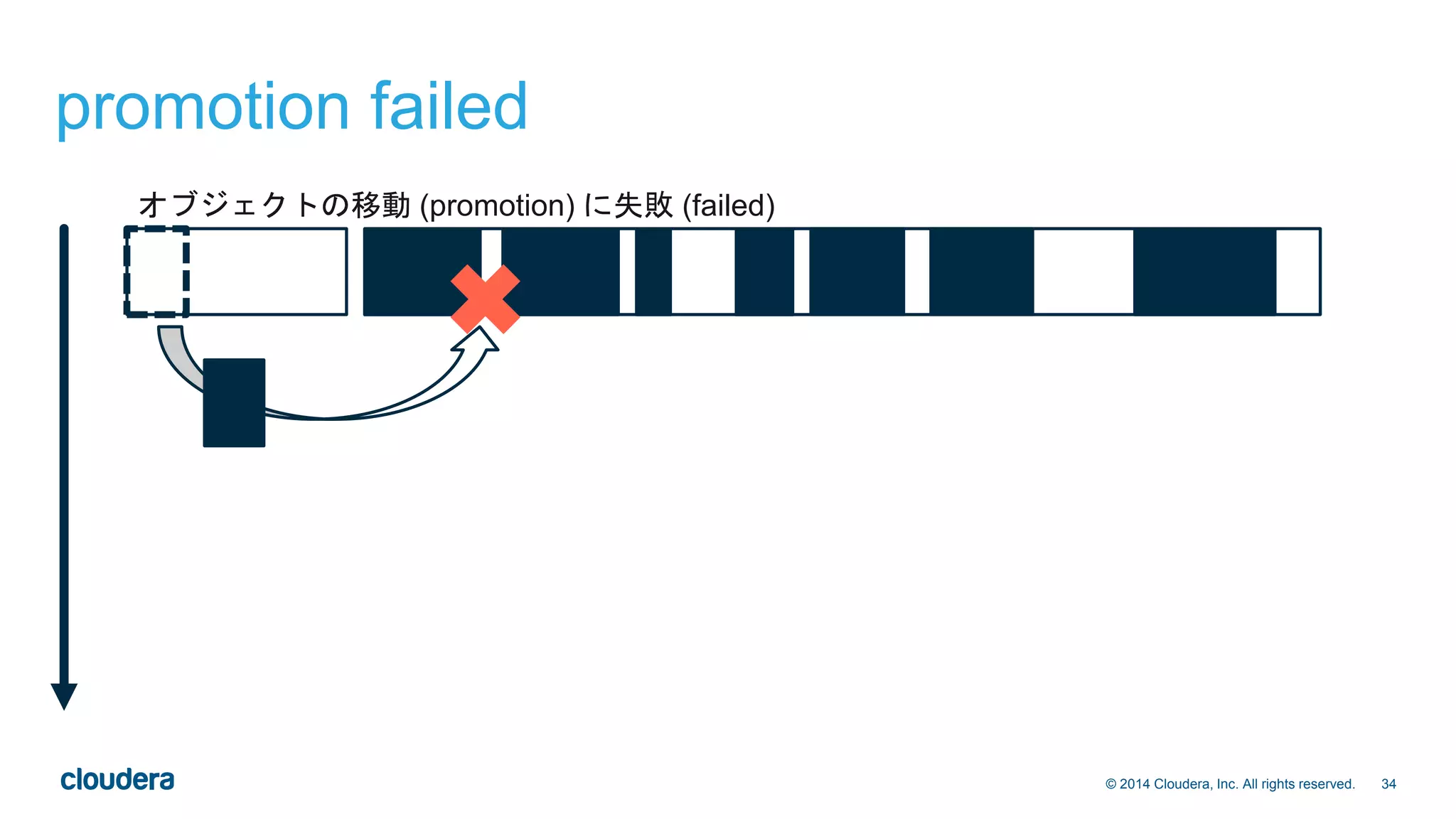
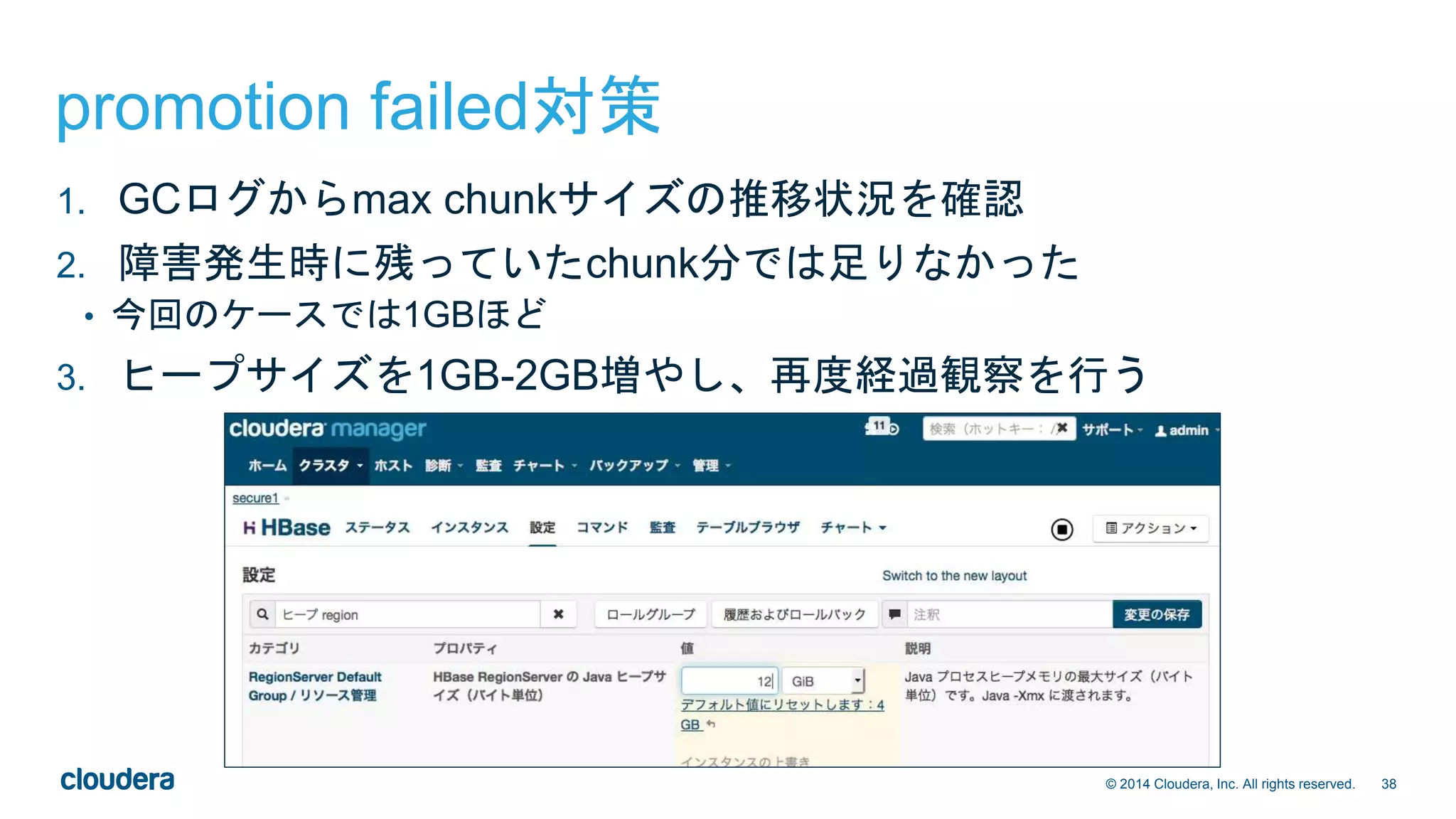
![22© 2014 Cloudera, Inc. All rights reserved.
トラブルシューティング(1)
• リージョン不整合の検知
• hbckユーティリティ [1]
• hbck -details > /tmp/hbase-`date`.txt
• 主に以下の検査を行う
1. Region Consistency (一貫性)
• META、HDFS内の.regioninfo、実際のリージョンアサイン状況がすべて合致しているか
2. Integrity (整合性)
• 複数のリージョンでキーの範囲が重複していないか
• キーの順序が後退していないか
• リージョン間に穴が空いていないか
• 最後に表示される不整合件数が0であればOK
0 inconsistencies detected
[1] 詳細は http://hbase.apache.org/book.html#hbck.in.depth](https://image.slidesharecdn.com/hbasebookevent20150202-150202210242-conversion-gate02/75/HBase-hbase_ca-22-2048.jpg)



























![[db tech showcase Tokyo 2016] A32: Oracle脳で考えるSQL Server運用 by 株式会社インサイトテクノロジー...](https://cdn.slidesharecdn.com/ss_thumbnails/tehahj7vqmsswpgrzrq6-signature-4c7632456c9c538ff9d2a30431910153be9e17d570b88fac06692ab02f11f222-poli-160725043205-thumbnail.jpg?width=640&height=640&fit=bounds)








































![[DB tech showcase Tokyo 2015] B37 :オンプレミスからAWS上のSAP HANAまで高信頼DBシステム構築にHAクラス...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtechshowcasetokyo2015b37awssaphanadbhaby-150619150810-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DB tech showcase Tokyo 2015] B37 :オンプレミスからAWS上のSAP HANAまで高信頼DBシステム構築にHAクラスタリ...](https://cdn.slidesharecdn.com/ss_thumbnails/b37dbtechshowcasetokyo2015haclusteringsoftware20150612-150611165311-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)






















