





![Conversion Count HQL
INSERT OVERWRITE TABLE conversion_click
PARTITION (log_date= :logDate, log_number=:logNumber)
SELECT regexp_extract(request, 'convid=([a-zA-Z0-9%])', 1),
regexp_extract(request, 'convflg=(A|B){1}', 1),
count(1),
:logMonth,
:logWeek
FROM parsed_log
WHERE request RLIKE 'convid=[a-zA-Z0-9%]'
AND request RLIKE 'convflg=(A|B){1}'
AND log_date = :logDate
AND log_number = :logNumber
GROUP BY regexp_extract(request, 'convid=([a-zA-Z0-9%])', 1),
regexp_extract(request, 'convflg=(A|B){1}', 1)](https://image.slidesharecdn.com/dataanalyticswithhadoophiveonmultipledatacenters-120729214722-phpapp02/85/Data-analytics-with-hadoop-hive-on-multiple-data-centers-8-320.jpg)
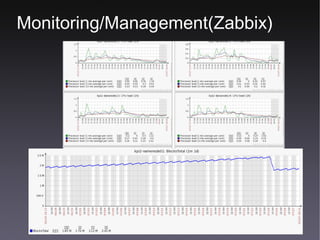




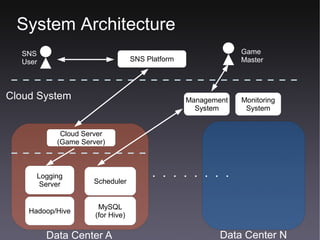
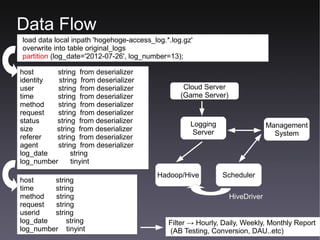
This document discusses GMO Internet's data analytics system for analyzing social game data from over 500 game titles across multiple data centers in Japan and the US. It summarizes the system's architecture, which uses Hadoop/Hive to process logging data from game servers into hourly, daily, weekly, and monthly reports on key performance indicators. The system partitions and stores large volumes of data across multiple NameNodes and processes over 6 million blocks and 44,000 jobs per day to generate conversion counts and other analytics for A/B testing.






































































































