Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
LINE Corporation
1,832 views
100億超メッセージ/日のサービスを 支えるHBase運用におけるチャレンジ
HBase Meetup Tokyo Summer 2015 での講演資料です
Technology
◦
Read more
11
Save
Share
Embed
Embed presentation
1
/ 22
2
/ 22
3
/ 22
4
/ 22
5
/ 22
6
/ 22
7
/ 22
8
/ 22
9
/ 22
10
/ 22
11
/ 22
12
/ 22
13
/ 22
14
/ 22
15
/ 22
16
/ 22
17
/ 22
18
/ 22
19
/ 22
20
/ 22
21
/ 22
22
/ 22
More Related Content
PDF
Hadoopのシステム設計・運用のポイント
by
Cloudera Japan
PDF
スケーラブルなシステムのためのHBaseスキーマ設計 #hcj13w
by
Cloudera Japan
PDF
なぜApache HBaseを選ぶのか? #cwt2013
by
Cloudera Japan
PDF
HBaseを用いたグラフDB「Hornet」の設計と運用
by
Toshihiro Suzuki
PPTX
HBase×Impalaで作るアドテク 「GMOプライベートDMP」@HBaseMeetupTokyo2015Summer
by
Michio Katano
PDF
Osc2012 spring HBase Report
by
Seiichiro Ishida
PDF
20分でわかるHBase
by
Sho Shimauchi
PDF
HBase at Ameba
by
Toshihiro Suzuki
Hadoopのシステム設計・運用のポイント
by
Cloudera Japan
スケーラブルなシステムのためのHBaseスキーマ設計 #hcj13w
by
Cloudera Japan
なぜApache HBaseを選ぶのか? #cwt2013
by
Cloudera Japan
HBaseを用いたグラフDB「Hornet」の設計と運用
by
Toshihiro Suzuki
HBase×Impalaで作るアドテク 「GMOプライベートDMP」@HBaseMeetupTokyo2015Summer
by
Michio Katano
Osc2012 spring HBase Report
by
Seiichiro Ishida
20分でわかるHBase
by
Sho Shimauchi
HBase at Ameba
by
Toshihiro Suzuki
What's hot
PPTX
Hadoop Troubleshooting 101 - Japanese Version
by
Cloudera, Inc.
PDF
マルチテナント Hadoop クラスタのためのモニタリング Best Practice
by
Hadoop / Spark Conference Japan
PPT
Apache Hive 紹介
by
あしたのオープンソース研究所
PPTX
Introduction to Impala ~Hadoop用のSQLエンジン~ #hcj13w
by
Cloudera Japan
PPTX
HDFS Supportaiblity Improvements
by
Cloudera Japan
PDF
刊行記念セミナー「HBase徹底入門」
by
cyberagent
PDF
Apache Drill Overview - Tokyo Apache Drill Meetup 2015/09/15
by
MapR Technologies Japan
PDF
Cloudera Impalaをサービスに組み込むときに苦労した話
by
Yukinori Suda
PDF
MapReduce/Spark/Tezのフェアな性能比較に向けて (Cloudera World Tokyo 2014 LT講演)
by
Hadoop / Spark Conference Japan
PDF
HDFS HA セミナー #hadoop
by
Cloudera Japan
PDF
[db tech showcase Tokyo 2014] L32: Apache Cassandraに注目!!(IoT, Bigdata、NoSQLのバ...
by
Insight Technology, Inc.
PDF
Hadoop入門
by
Preferred Networks
PDF
HBaseCon 2012 参加レポート
by
NTT DATA OSS Professional Services
PPTX
Cloudera大阪セミナー 20130219
by
Cloudera Japan
PDF
Kuduを調べてみた #dogenzakalt
by
Toshihiro Suzuki
PDF
5分でわかる Apache HBase 最新版 #hcj2014
by
Cloudera Japan
PDF
Hadoop事始め
by
You&I
PDF
Evolution of Impala #hcj2014
by
Cloudera Japan
PDF
CDH4.1オーバービュー
by
Cloudera Japan
PDF
MapR M7 技術概要
by
MapR Technologies Japan
Hadoop Troubleshooting 101 - Japanese Version
by
Cloudera, Inc.
マルチテナント Hadoop クラスタのためのモニタリング Best Practice
by
Hadoop / Spark Conference Japan
Apache Hive 紹介
by
あしたのオープンソース研究所
Introduction to Impala ~Hadoop用のSQLエンジン~ #hcj13w
by
Cloudera Japan
HDFS Supportaiblity Improvements
by
Cloudera Japan
刊行記念セミナー「HBase徹底入門」
by
cyberagent
Apache Drill Overview - Tokyo Apache Drill Meetup 2015/09/15
by
MapR Technologies Japan
Cloudera Impalaをサービスに組み込むときに苦労した話
by
Yukinori Suda
MapReduce/Spark/Tezのフェアな性能比較に向けて (Cloudera World Tokyo 2014 LT講演)
by
Hadoop / Spark Conference Japan
HDFS HA セミナー #hadoop
by
Cloudera Japan
[db tech showcase Tokyo 2014] L32: Apache Cassandraに注目!!(IoT, Bigdata、NoSQLのバ...
by
Insight Technology, Inc.
Hadoop入門
by
Preferred Networks
HBaseCon 2012 参加レポート
by
NTT DATA OSS Professional Services
Cloudera大阪セミナー 20130219
by
Cloudera Japan
Kuduを調べてみた #dogenzakalt
by
Toshihiro Suzuki
5分でわかる Apache HBase 最新版 #hcj2014
by
Cloudera Japan
Hadoop事始め
by
You&I
Evolution of Impala #hcj2014
by
Cloudera Japan
CDH4.1オーバービュー
by
Cloudera Japan
MapR M7 技術概要
by
MapR Technologies Japan
Viewers also liked
PPTX
HBaseサポート最前線 #hbase_ca
by
Cloudera Japan
PPTX
HBase スキーマ設計のポイント
by
daisuke-a-matsui
PDF
ベイズ推定とDeep Learningを使用したレコメンドエンジン開発
by
LINE Corporation
PDF
Akka ActorとAMQPでLINEのメッセージングパイプラインをリプレースした話
by
LINE Corporation
PDF
HBaseとRedisを使った100億超/日メッセージを処理するLINEのストレージ
by
LINE Corporation
PPT
Cassandraのしくみ データの読み書き編
by
Yuki Morishita
PDF
LINE Platform Development Chronicle
by
LINE Corporation
PDF
LINE for Apple Watch
by
LINE Corporation
ODP
Hbase, Cách thức lưu trữ và tìm kiếm
by
Tuan Bach Van
PPTX
LINE 2016 エンジニアインターン 01
by
LINE Corporation
PDF
HBase活用事例 #hbase_ca
by
Cloudera Japan
PDF
20150625 cloudera
by
Recruit Technologies
PDF
Intern2015 03
by
LINE Corporation
PDF
テレビ東京 meets LINE ビジネスコネクト
by
LINE Corporation
PDF
4年に渡る LINE Android アプリの進化とチャレンジ
by
LINE Corporation
PDF
グローバルなネットワーク環境と複数OSに対応するための LINE Game Client Platform 開発戦略
by
LINE Corporation
PDF
巨大化するスタンプ・着せかえ販売システム、その危機と復活の記録
by
LINE Corporation
PDF
リアルタイム画風変換とその未来
by
LINE Corporation
PDF
Webサービスの国際化にあたり LINE Creators Market 開発がどのように行われたか
by
LINE Corporation
PDF
ビッグデータを活用するための分析プラットフォーム 〜データ集計した先に求められる分析技術〜
by
LINE Corporation
HBaseサポート最前線 #hbase_ca
by
Cloudera Japan
HBase スキーマ設計のポイント
by
daisuke-a-matsui
ベイズ推定とDeep Learningを使用したレコメンドエンジン開発
by
LINE Corporation
Akka ActorとAMQPでLINEのメッセージングパイプラインをリプレースした話
by
LINE Corporation
HBaseとRedisを使った100億超/日メッセージを処理するLINEのストレージ
by
LINE Corporation
Cassandraのしくみ データの読み書き編
by
Yuki Morishita
LINE Platform Development Chronicle
by
LINE Corporation
LINE for Apple Watch
by
LINE Corporation
Hbase, Cách thức lưu trữ và tìm kiếm
by
Tuan Bach Van
LINE 2016 エンジニアインターン 01
by
LINE Corporation
HBase活用事例 #hbase_ca
by
Cloudera Japan
20150625 cloudera
by
Recruit Technologies
Intern2015 03
by
LINE Corporation
テレビ東京 meets LINE ビジネスコネクト
by
LINE Corporation
4年に渡る LINE Android アプリの進化とチャレンジ
by
LINE Corporation
グローバルなネットワーク環境と複数OSに対応するための LINE Game Client Platform 開発戦略
by
LINE Corporation
巨大化するスタンプ・着せかえ販売システム、その危機と復活の記録
by
LINE Corporation
リアルタイム画風変換とその未来
by
LINE Corporation
Webサービスの国際化にあたり LINE Creators Market 開発がどのように行われたか
by
LINE Corporation
ビッグデータを活用するための分析プラットフォーム 〜データ集計した先に求められる分析技術〜
by
LINE Corporation
Similar to 100億超メッセージ/日のサービスを 支えるHBase運用におけるチャレンジ
PDF
1000台規模のHadoopクラスタをHive/Tezアプリケーションにあわせてパフォーマンスチューニングした話
by
Yahoo!デベロッパーネットワーク
PDF
今日から使えるCouchbaseシステムアーキテクチャデザインパターン集
by
Couchbase Japan KK
PDF
MapReduce/YARNの仕組みを知る
by
日本ヒューレット・パッカード株式会社
PPT
Hadoop ~Yahoo! JAPANの活用について~
by
Yahoo!デベロッパーネットワーク
PDF
知っておきたいFirebase の色んな上限について
by
Kenichi Tatsuhama
PDF
ストリーム処理エンジン「Zero」の開発と運用
by
Eiichi Sato
PPTX
500+のサーバーで動く LINE Ads PlatformをささえるSpring
by
LINE Corporation
PDF
マルチスレッド問題の特定と再現に頑張った話
by
LINE Corporation
PDF
『じゃらん』『ホットペッパーグルメ』を支えるクラウド・データ基盤
by
Recruit Lifestyle Co., Ltd.
PDF
Dockerを活用したリクルートグループ開発基盤の構築
by
Recruit Technologies
PDF
Hadoop, NoSQL, GlusterFSの概要
by
日本ヒューレット・パッカード株式会社
PDF
HBase Across the World #LINE_DM
by
Cloudera Japan
PDF
Lars George HBase Seminar with O'REILLY Oct.12 2012
by
Cloudera Japan
PPT
Hadoopの紹介
by
bigt23
PDF
20120423 hbase勉強会
by
Toshiaki Toyama
PDF
Facebookのリアルタイム Big Data 処理
by
maruyama097
1000台規模のHadoopクラスタをHive/Tezアプリケーションにあわせてパフォーマンスチューニングした話
by
Yahoo!デベロッパーネットワーク
今日から使えるCouchbaseシステムアーキテクチャデザインパターン集
by
Couchbase Japan KK
MapReduce/YARNの仕組みを知る
by
日本ヒューレット・パッカード株式会社
Hadoop ~Yahoo! JAPANの活用について~
by
Yahoo!デベロッパーネットワーク
知っておきたいFirebase の色んな上限について
by
Kenichi Tatsuhama
ストリーム処理エンジン「Zero」の開発と運用
by
Eiichi Sato
500+のサーバーで動く LINE Ads PlatformをささえるSpring
by
LINE Corporation
マルチスレッド問題の特定と再現に頑張った話
by
LINE Corporation
『じゃらん』『ホットペッパーグルメ』を支えるクラウド・データ基盤
by
Recruit Lifestyle Co., Ltd.
Dockerを活用したリクルートグループ開発基盤の構築
by
Recruit Technologies
Hadoop, NoSQL, GlusterFSの概要
by
日本ヒューレット・パッカード株式会社
HBase Across the World #LINE_DM
by
Cloudera Japan
Lars George HBase Seminar with O'REILLY Oct.12 2012
by
Cloudera Japan
Hadoopの紹介
by
bigt23
20120423 hbase勉強会
by
Toshiaki Toyama
Facebookのリアルタイム Big Data 処理
by
maruyama097
More from LINE Corporation
PDF
在 LINE 私有雲中使用 Managed Kubernetes
by
LINE Corporation
PDF
LINE Chatbot - 活動報名報到設計分享
by
LINE Corporation
PDF
LINE 新星計劃介紹與新創團隊分享
by
LINE Corporation
PDF
LINE 區塊鏈平台及代幣經濟 - LINK Chain及LINK介紹
by
LINE Corporation
PDF
LINE TODAY高效率的敏捷測試開發技巧
by
LINE Corporation
PDF
LINE Platform API Update - 打造一個更好的Chatbot服務
by
LINE Corporation
PDF
LINE Pay - 一卡通支付新體驗
by
LINE Corporation
PPTX
GA Test Automation
by
LINE Corporation
PDF
LINE 技術合作夥伴與應用分享
by
LINE Corporation
PDF
LINE 開發者社群經營與技術推廣
by
LINE Corporation
PDF
The Magic of LINE 購物 Testing
by
LINE Corporation
PDF
日本開發者大會短講分享
by
LINE Corporation
PDF
Reduce dependency on Rx with Kotlin Coroutines
by
LINE Corporation
PDF
LINE Things - LINE IoT平台新技術分享
by
LINE Corporation
PDF
Feature Detection for UI Testing
by
LINE Corporation
PDF
Use Kotlin scripts and Clova SDK to build your Clova extension
by
LINE Corporation
PDF
UI Automation Test with JUnit5
by
LINE Corporation
PDF
Kotlin/NativeでAndroidのNativeメソッドを実装してみた
by
LINE Corporation
PDF
JJUG CCC 2018 Fall 懇親会LT
by
LINE Corporation
PDF
Keynote - LINE 的技術策略佈局與跨國產品開發
by
LINE Corporation
在 LINE 私有雲中使用 Managed Kubernetes
by
LINE Corporation
LINE Chatbot - 活動報名報到設計分享
by
LINE Corporation
LINE 新星計劃介紹與新創團隊分享
by
LINE Corporation
LINE 區塊鏈平台及代幣經濟 - LINK Chain及LINK介紹
by
LINE Corporation
LINE TODAY高效率的敏捷測試開發技巧
by
LINE Corporation
LINE Platform API Update - 打造一個更好的Chatbot服務
by
LINE Corporation
LINE Pay - 一卡通支付新體驗
by
LINE Corporation
GA Test Automation
by
LINE Corporation
LINE 技術合作夥伴與應用分享
by
LINE Corporation
LINE 開發者社群經營與技術推廣
by
LINE Corporation
The Magic of LINE 購物 Testing
by
LINE Corporation
日本開發者大會短講分享
by
LINE Corporation
Reduce dependency on Rx with Kotlin Coroutines
by
LINE Corporation
LINE Things - LINE IoT平台新技術分享
by
LINE Corporation
Feature Detection for UI Testing
by
LINE Corporation
Use Kotlin scripts and Clova SDK to build your Clova extension
by
LINE Corporation
UI Automation Test with JUnit5
by
LINE Corporation
Kotlin/NativeでAndroidのNativeメソッドを実装してみた
by
LINE Corporation
JJUG CCC 2018 Fall 懇親会LT
by
LINE Corporation
Keynote - LINE 的技術策略佈局與跨國產品開發
by
LINE Corporation
100億超メッセージ/日のサービスを 支えるHBase運用におけるチャレンジ
1.
100億超メッセージ/日のサービスを 支えるHBase運用におけるチャレンジ LINE株式会社 開発1センター 坂井 隆一 ⓒ
2015 LINE CORPORATION
2.
自己紹介 坂井 隆一 • LINE入社前 ネットワーク関連のソフトウェア開発に従事 ストレージはほぼ未経験 •
2014年秋 LINEに入社 HBase開発・運用チームに配属 絶賛HBase修行中
3.
本日の話題 • LINEのHBase clusterの紹介 •
あるGCとの戦いの記録
4.
LINEのHBaseの用途と要求 • 主な用途 非同期メッセージングの実現 複数デバイス(smartphone +
desktop)への対応 social graph • 要求 低遅延 高可用性(HA) スケーラビリティ
5.
ストレージのHA構成 Redis + HBase
× 2 のHA構成 • LINE独自のsharded Redis clusters • HBase 0.90.6-cdh3u5 clusters • writeだけでなくreadも多重化 storage API Redis cluster HBase cluster HBase cluster messaging servers
6.
データの配置 ストレージの構成 データの性質 データの種類 Redis
+ HBase ×2 • 頻繁にアクセスされる データ • リアルタイムアクセス されるデータ • user information • message • event HBase ×2 • リアルタイム要求が 低めのデータ • social graph • message box HBase ×1 • HA要求が高くない データ • stats event : イベントを逐次処理するためのキュー
7.
Multi-tenancy or Small
Clusters? 現状は “small clusters” 構成 • multi-tenancy 巨大なclusterに複数のサービスを配置 • small clusters サービスごとに1つのclusterを運用 multi-tenancyに比べて”small”
8.
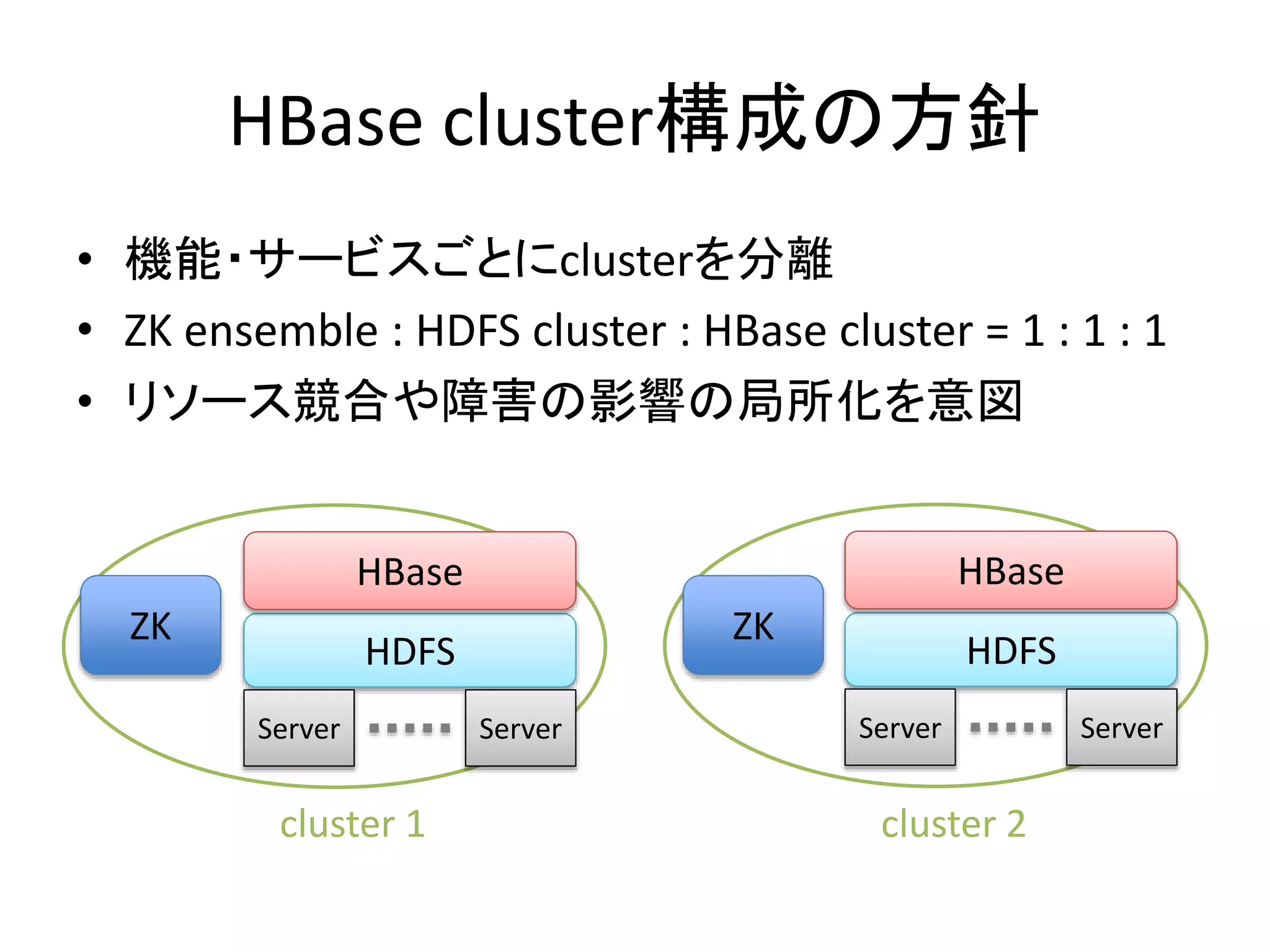
HBase cluster構成の方針 • 機能・サービスごとにclusterを分離 •
ZK ensemble : HDFS cluster : HBase cluster = 1 : 1 : 1 • リソース競合や障害の影響の局所化を意図 HDFS HBase Server Server HDFS HBase Server Server ZK cluster 1 cluster 2 ZK
9.
主なHBase cluster message event
stats HBase version 0.90.6-cdh3u5 0.90.6-cdh3u5 0.94.27 RegionServers 250 170 500 Used Capacity 133 TB 134 TB 11 PB Peak Time Requests 約2,000,000 / sec 約2,000,000 /sec - RegionServerのspec(導入時期による違いあり) • CPU : 6 cores × 2 / 2.40 GHz • Memory : 192 GB (RegionServerのheapに31GB) • Storage : 3.0 TB ioDrive2 ※message, eventはHAのため上記specのclusterが×2
10.
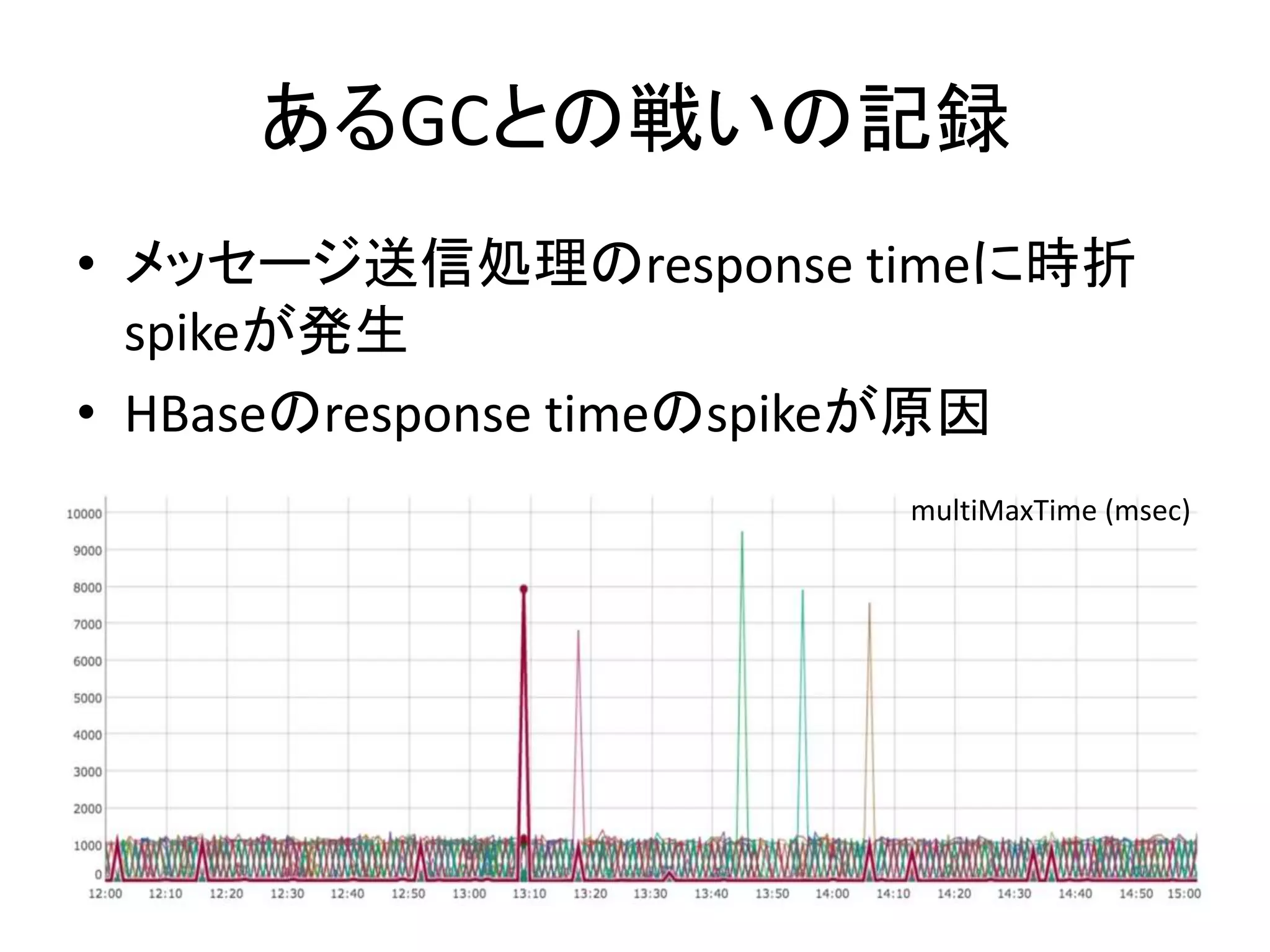
あるGCとの戦いの記録 • メッセージ送信処理のresponse timeに時折 spikeが発生 •
HBaseのresponse timeのspikeが原因 multiMaxTime (msec)
11.
spike発生時のRegionServer GC log •
new領域のpromotionに失敗 • full GCが発生して長時間のstop the world ※GCはCMSを使用 [GC 3439234.481: [ParNew (promotion failed): 235968K->214934K(235968K), 0.0474320 secs]3439234.528: [CMS: 11335704K->6744545K(16410692K), 7.5043760 secs] 11553160K->6744545K(16646660K), [CMS Perm : 25993K->25890K(43476K)], 7.5576600 secs] [Times: user=8.04 sys=0.00, real=7.55 secs]
12.
full GC付近のRegionServer log •
BlockCache evictionが多発 00:50:15,918 LruBlockCache: Block cache LRU eviction started; Attempting to free 731.93 MB of total=4.91 GB 00:50:15,935 LruBlockCache: Block cache LRU eviction completed; freed=859.86 MB, total=4.07 GB, single=1.12 GB, multi=3.74 GB, memory=0 KB ### ここでfull GC ### 00:50:28,546 LruBlockCache: Block cache LRU eviction started; Attempting to free 700.12 MB of total=4.88 GB 00:50:28,573 LruBlockCache: Block cache LRU eviction completed; freed=769.88 MB, total=4.13 GB, single=326.15 MB, multi=4.51 GB, memory=0 KB 00:50:28,887 LruBlockCache: Block cache LRU eviction started; Attempting to free 634.66 MB of total=4.81 GB 00:50:28,892 LruBlockCache: Block cache LRU eviction completed; freed=720.2 MB, total=4.11 GB, single=334.97 MB, multi=4.44 GB, memory=0 KB
13.
なぜBlockCache evictionが多発? 原因の可能性 • read
requestが多すぎる • 巨大なKeyValueをreadしている block cacheを大量に占有してしまうKeyValueがあ る? しかし、KeyValueサイズを調べたところ最大で 123KB
14.
KeyValue以外に何か? meta blockもblock cacheを使っている (HFile.java) public
ByteBuffer getMetaBlock(String metaBlockName, boolean cacheBlock) throws IOException { ... if(cacheBlock && cache != null) { cache.cacheBlock(name + "meta" + block, buf.duplicate(), inMemory); }
15.
meta blockの内容は? BloomFilterのmeta情報、そしてデータも! (StoreFile.java) ... ByteBuffer bloom
= reader.getMetaBlock(BLOOM_FILTER_DATA_KEY, true); … ByteBuffer b = reader.getMetaBlock(BLOOM_FILTER_META_KEY, false);
16.
BloomFilterのサイズを確認 $ hbase org.apache.hadoop.hbase.io.hfile.Hfile
–m –r XXXXX Block index size as per heapsize: 13860008 ... BloomSize: 164952448 No of Keys in bloom: 88121307 Max Keys for bloom: 88121307 Block Index: size=150648 164,952,448 B = 157 MB
17.
問題の原因 • 160MBのBloom filterのblockがcacheされる •
やがてGCの際にold領域にpromotionされる • old領域は多数の通常block (64KB)でフラグメ ンテーション状態 • 160MBの連続領域が確保できないとfull GC • HFile v1の問題 ⇒ HFile v2 (HBase 0.92〜)では解決済み
18.
問題の対策 問題のclusterではBloomFilterのチェックが効か ないアクセスをしていた ⇒ BloomFilterを作らないようにした io.storefile.bloom.max.keys • key数がこの設定値を越えるとBloomFilterを 作成しない
19.
問題の緩和策 別clusterではBloomFilterのサイズを下げた m: Bloom filterのbit数 n:
keyの最大数 e: 平均エラー率(defaultは0.01) m = - n´ln(e) (ln(2))2 e を 0.01 から 0.1 にすると m は 1/2
20.
GCとの戦いは続く • その他にもlong GC問題は発生 •
対策例 heap利用の最適化 MemStore領域とBlockCache領域のバランシング Java VM optionの最適化 Readを減らすschema/application設計 • BucketCache (HBase 0.96〜)が使えれば・・・
21.
まとめ • LINEのHBase cluster HAのため2
cluster構成 現状は multi-tenancy ではなく small clusters • 運用におけるチャレンジ 問題解決にはHBaseの深い理解が必要 新しいバージョンでは解決されている問題も・・・
22.
学んだこと HBase 0.90 はもう使わない方がいいらしい はやく
1.X になりたい ⇒ 現在進行中








![spike発生時のRegionServer GC log
• new領域のpromotionに失敗
• full GCが発生して長時間のstop the world
※GCはCMSを使用
[GC 3439234.481: [ParNew (promotion failed): 235968K->214934K(235968K),
0.0474320 secs]3439234.528: [CMS: 11335704K->6744545K(16410692K), 7.5043760
secs] 11553160K->6744545K(16646660K), [CMS Perm : 25993K->25890K(43476K)],
7.5576600 secs] [Times: user=8.04 sys=0.00, real=7.55 secs]](https://image.slidesharecdn.com/hbasemeetup2015-line-150714055939-lva1-app6892/75/100-HBase-11-2048.jpg)






























![[db tech showcase Tokyo 2014] L32: Apache Cassandraに注目!!(IoT, Bigdata、NoSQLのバ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtstokyo2014l32datastaxapachecassandraiotbigdatanosql-141120022255-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)
































































