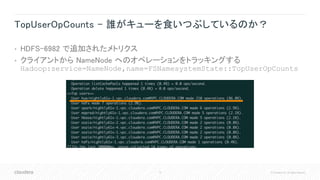
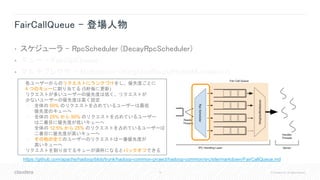
#41 例えば、NameNodeやDataNodeに独立したディスクが割り当てられているか、ですとかクラスタ内の平均ファイルサイズの確認をして small files problem が発生していないかを確認してくれます。あるいは、障害が発生しやすい設定がされていないか、JVMのオプションで推奨されないものが設定されていないか、といったレビューも自動で走っています。それに、ある程度のデータ量のクラスタでは、スナップショットがとられているかどうかもチェックしてくれます。万が一オペミスでデータを削除してしまったようなケースは冗談のように思うかもしれませんけど定期的に上がってくる障害報告でして、そのようなケースでもスナップショットを取っていればデータロストは避けられるわけです。なので、スナップショットを取っているかいないかでサポートの負荷が全然違いますので、こういったチェックも行っているわけです。で、この結果はサポートや開発だけじゃなくて、営業SEやコンサルのメンバーも見れるので、お客様とのミーティング中にアドバイスに使ったりもできるわけですね





![11 © Cloudera, Inc. All rights reserved.
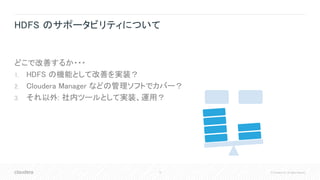
HDFS のサポータビリティについて
• HDFS の障害は影響範囲が大きい
• オンプレミス環境でビッグデータ処理を行う上でデファクトスタンダードの分散ストレージ
• HDFS が [止まる, 遅い] と全てのアプリケーションに影響が出る
• サポートでは顧客によって環境がまるで違う
• バージョンは?適用済みのパッチは?ノード数は?
• ファイル数やブロック数は?ハンドラの数は?
• そもそも顧客が知らない
• いろんなワークロードを流していると、管理者が全てを把握するのは難しい
• どのログに着目すればいいのかを判断するのに、ある程度の経験値が求められる
• サポータビリティの向上はサポート、開発チームにとって最優先事項](https://image.slidesharecdn.com/2019hcjhdfssupportability-190315032209/85/HDFS-Supportaiblity-Improvements-11-320.jpg)

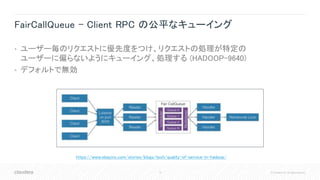
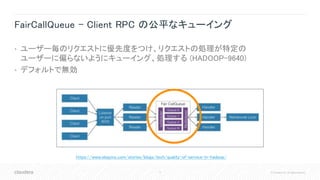
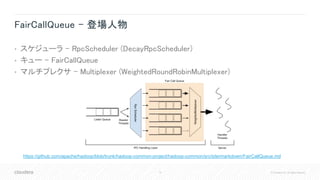
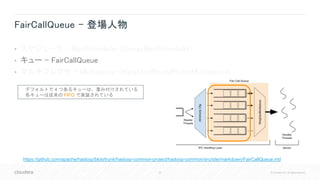
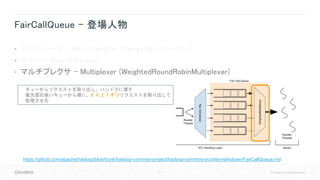



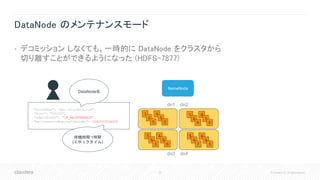





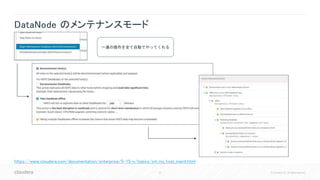

![37 © Cloudera, Inc. All rights reserved.
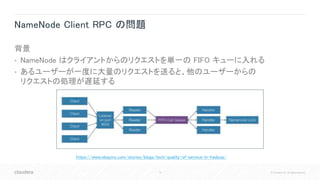
SendPacketDownstreamAvgInfo - パイプライン DataNode のメトリクス
• パイプラインの最後の DataNode への転送時間をトラッキング(HDFS-10917)
• 全ての DataNode は、パイプラインの最後から二番目となった時に
最後の DataNode への転送にかかった時間を移動平均で記録
dn1 dn2 dn3
dn2はdn3への
転送時間を記録
"name" : "Hadoop:service=DataNode,name=DataNodeInfo",
"SendPacketDownstreamAvgInfo" : "{
"[172.31.112.242:9864]RollingAvgTime":0.8711560381546584,
"[172.31.113.53:9864]RollingAvgTime":0.4051608579088472}",
自身以外の
DataNode](https://image.slidesharecdn.com/2019hcjhdfssupportability-190315032209/85/HDFS-Supportaiblity-Improvements-37-320.jpg)



























![[db tech showcase Tokyo 2016] A32: Oracle脳で考えるSQL Server運用 by 株式会社インサイトテクノロジー...](https://cdn.slidesharecdn.com/ss_thumbnails/tehahj7vqmsswpgrzrq6-signature-4c7632456c9c538ff9d2a30431910153be9e17d570b88fac06692ab02f11f222-poli-160725043205-thumbnail.jpg?width=640&height=640&fit=bounds)










































