Recommended
PPTX
PostgreSQLクエリ実行の基礎知識 ~Explainを読み解こう~
PDF
ヤフー社内でやってるMySQLチューニングセミナー大公開
PDF
なぜ、いま リレーショナルモデルなのか(理論から学ぶデータベース実践入門読書会スペシャル)
PDF
PDF
SQLアンチパターン - 開発者を待ち受ける25の落とし穴 (拡大版)
PDF
PDF
MySQL 5.7にやられないためにおぼえておいてほしいこと
PPTX
SQL Server Performance Tuning Essentials
PDF
PostgreSQL SQLチューニング入門 実践編(pgcon14j)
PPTX
pg_bigmで全文検索するときに気を付けたい5つのポイント(第23回PostgreSQLアンカンファレンス@オンライン 発表資料)
PDF
PostgreSQLの実行計画を読み解こう(OSC2015 Spring/Tokyo)
PDF
pg_hint_planを知る(第37回PostgreSQLアンカンファレンス@オンライン 発表資料)
PDF
SQLアンチパターン 幻の第26章「とりあえず削除フラグ」
PDF
PDF
Memoizeの仕組み(第41回PostgreSQLアンカンファレンス@オンライン 発表資料)
PPTX
PostgreSQL 12は ここがスゴイ! ~性能改善やpluggable storage engineなどの新機能を徹底解説~ (NTTデータ テクノ...
PDF
PDF
ODP
Goのサーバサイド実装におけるレイヤ設計とレイヤ内実装について考える
PPTX
PostgreSQL14の pg_stat_statements 改善(第23回PostgreSQLアンカンファレンス@オンライン 発表資料)
PDF
DDD x CQRS 更新系と参照系で異なるORMを併用して上手くいった話
PDF
PDF
PDF
Apache Arrow - データ処理ツールの次世代プラットフォーム
PDF
オンライン物理バックアップの排他モードと非排他モードについて(第15回PostgreSQLアンカンファレンス@オンライン 発表資料)
PDF
PDF
PDF
PostgreSQLのgitレポジトリから見える2022年の開発状況(第38回PostgreSQLアンカンファレンス@オンライン 発表資料)
PDF
PDF
More Related Content
PPTX
PostgreSQLクエリ実行の基礎知識 ~Explainを読み解こう~
PDF
ヤフー社内でやってるMySQLチューニングセミナー大公開
PDF
なぜ、いま リレーショナルモデルなのか(理論から学ぶデータベース実践入門読書会スペシャル)
PDF
PDF
SQLアンチパターン - 開発者を待ち受ける25の落とし穴 (拡大版)
PDF
PDF
MySQL 5.7にやられないためにおぼえておいてほしいこと
PPTX
SQL Server Performance Tuning Essentials
What's hot
PDF
PostgreSQL SQLチューニング入門 実践編(pgcon14j)
PPTX
pg_bigmで全文検索するときに気を付けたい5つのポイント(第23回PostgreSQLアンカンファレンス@オンライン 発表資料)
PDF
PostgreSQLの実行計画を読み解こう(OSC2015 Spring/Tokyo)
PDF
pg_hint_planを知る(第37回PostgreSQLアンカンファレンス@オンライン 発表資料)
PDF
SQLアンチパターン 幻の第26章「とりあえず削除フラグ」
PDF
PDF
Memoizeの仕組み(第41回PostgreSQLアンカンファレンス@オンライン 発表資料)
PPTX
PostgreSQL 12は ここがスゴイ! ~性能改善やpluggable storage engineなどの新機能を徹底解説~ (NTTデータ テクノ...
PDF
PDF
ODP
Goのサーバサイド実装におけるレイヤ設計とレイヤ内実装について考える
PPTX
PostgreSQL14の pg_stat_statements 改善(第23回PostgreSQLアンカンファレンス@オンライン 発表資料)
PDF
DDD x CQRS 更新系と参照系で異なるORMを併用して上手くいった話
PDF
PDF
PDF
Apache Arrow - データ処理ツールの次世代プラットフォーム
PDF
オンライン物理バックアップの排他モードと非排他モードについて(第15回PostgreSQLアンカンファレンス@オンライン 発表資料)
PDF
PDF
PDF
PostgreSQLのgitレポジトリから見える2022年の開発状況(第38回PostgreSQLアンカンファレンス@オンライン 発表資料)
Viewers also liked
PDF
PDF
PDF
PostgreSQLアーキテクチャ入門(PostgreSQL Conference 2012)
PDF
PDF
【SQLインジェクション対策】徳丸先生に怒られない、動的SQLの安全な組み立て方
PDF
PDF
PDF
Datalogからsqlへの トランスレータを書いた話
ODP
Data analytics with hadoop hive on multiple data centers
PDF
Cloudera Manager4.0とNameNode-HAセミナー資料
PDF
Lars George HBase Seminar with O'REILLY Oct.12 2012
PDF
20120830 DBリファクタリング読書会第三回
PPTX
PPTX
Future of HCatalog - Hadoop Summit 2012
PPTX
Writing Yarn Applications Hadoop Summit 2012
KEY
Hadoop Summit 2012 - Hadoop and Vertica: The Data Analytics Platform at Twitter
PDF
【17-E-3】 オンライン機械学習で実現する大規模データ処理
Similar to SQLチューニング入門 入門編
PDF
PPTX
押さえておきたい、PostgreSQL 13 の新機能!! (PostgreSQL Conference Japan 2020講演資料)
PDF
PostgreSQL18新機能紹介(db tech showcase 2025 発表資料)
PDF
JPUGしくみ+アプリケーション勉強会(第20回)
PDF
PostgreSQL17対応版 EXPLAINオプションについて (第49回PostgreSQLアンカンファレンス@東京 発表資料)
PDF
PDF
PostgreSQL実行計画入門@関西PostgreSQL勉強会
PDF
YugabyteDBの実行計画を眺める(NewSQL/分散SQLデータベースよろず勉強会 #3 発表資料)
PDF
PDF
PDF
Introduction of Oracle Database Architecture
PDF
RailsエンジニアのためのSQLチューニング速習会
PDF
PDF
ODP
PostgreSQL 9.2 新機能 - OSC 2012 Kansai@Kyoto
PDF
PDF
PPT
20090107 Postgre Sqlチューニング(Sql編)
PDF
PDF
PostgreSQL 9.2 新機能 - 新潟オープンソースセミナー2012
SQLチューニング入門 入門編 1. 2. 自己紹介
• 氏名下雅意美紀
• 所属TIS株式会社
• 略歴2014年:TIS株式会社に入社
• PostgreSQL歴= 入社歴
• 日頃のPostgreSQLとのふれあい
業務で日々勉強する以外にも、JPUGのしくみ分科会や
(http://www.postgresql.jp/wg/shikumi/study30_materials)、
PGEConsなど、PostgreSQLのコミュニティにも参加しています。
2
3. PostgreSQL SQLチューニング入門
入門編
本セッションの目標
PostgreSQLがSQL実行時に内部でどのような処理を行っている
かを知りましょう。
SQLチューニングで使用するExplainコマンドが出力する実行計
画を読めるようになりましょう。
アジェンダ
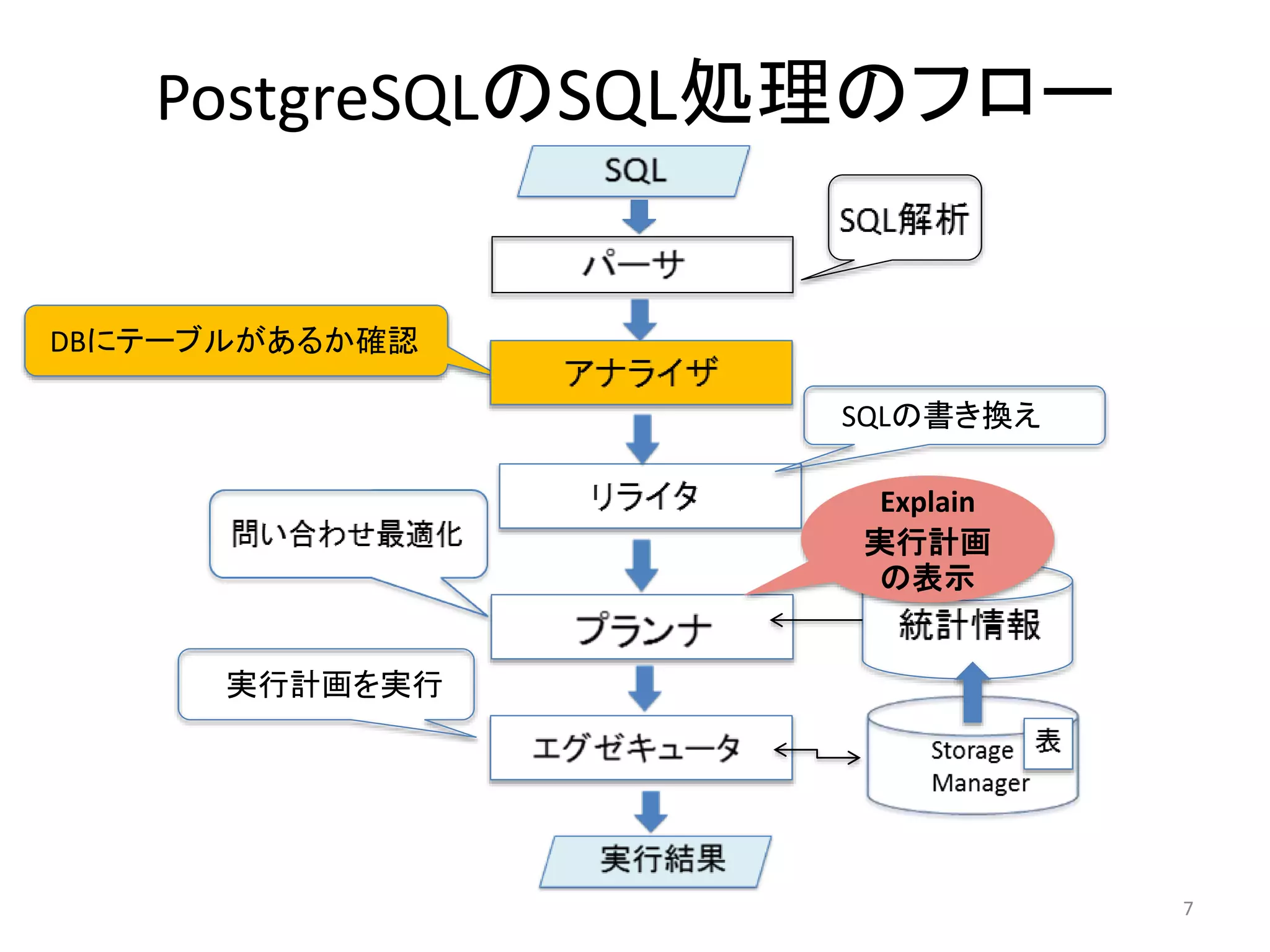
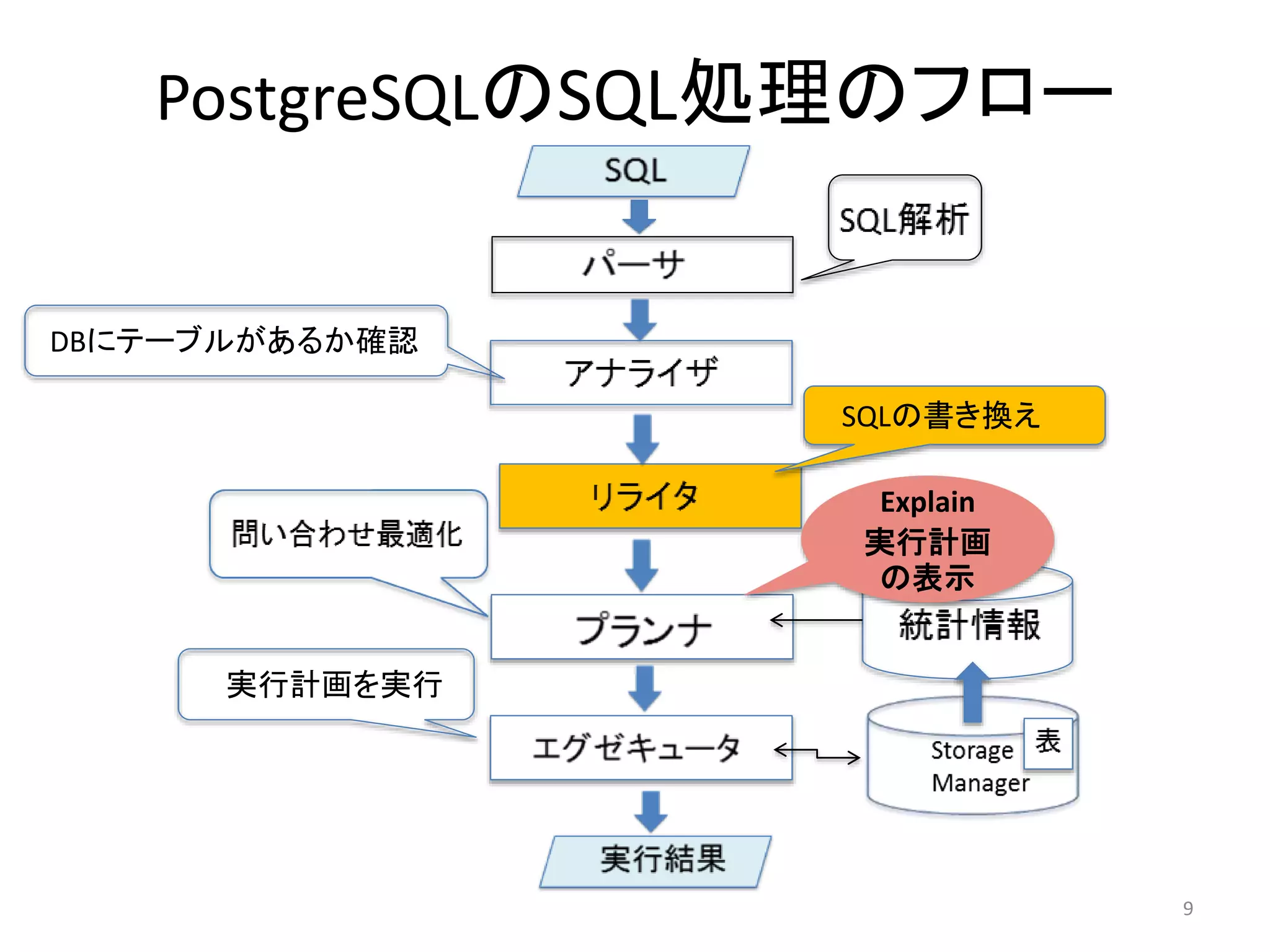
・PostgreSQLのSQL実行の概要
・Explain実行結果(実行計画)の読み方
・Explain演算子の種類
3
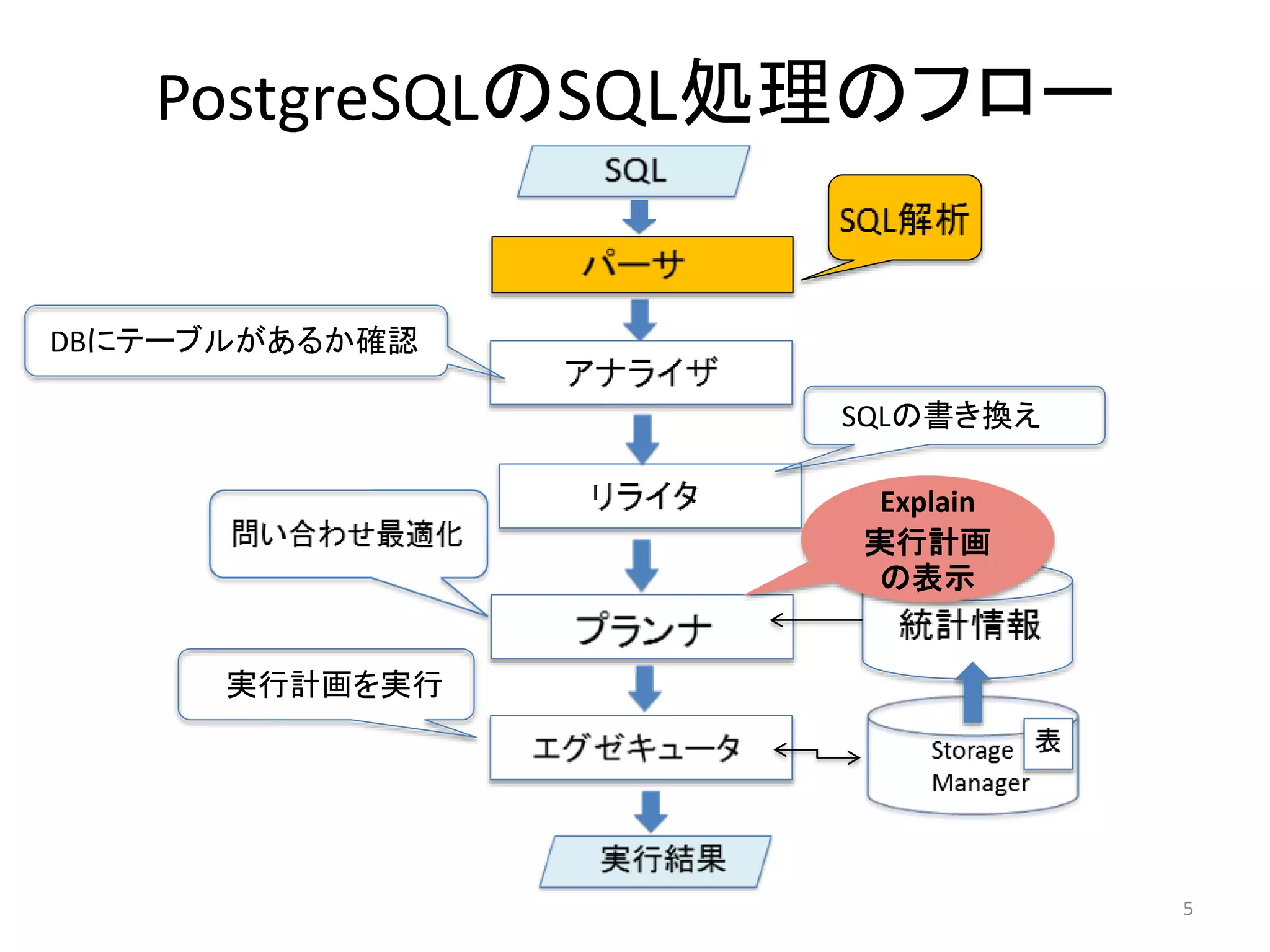
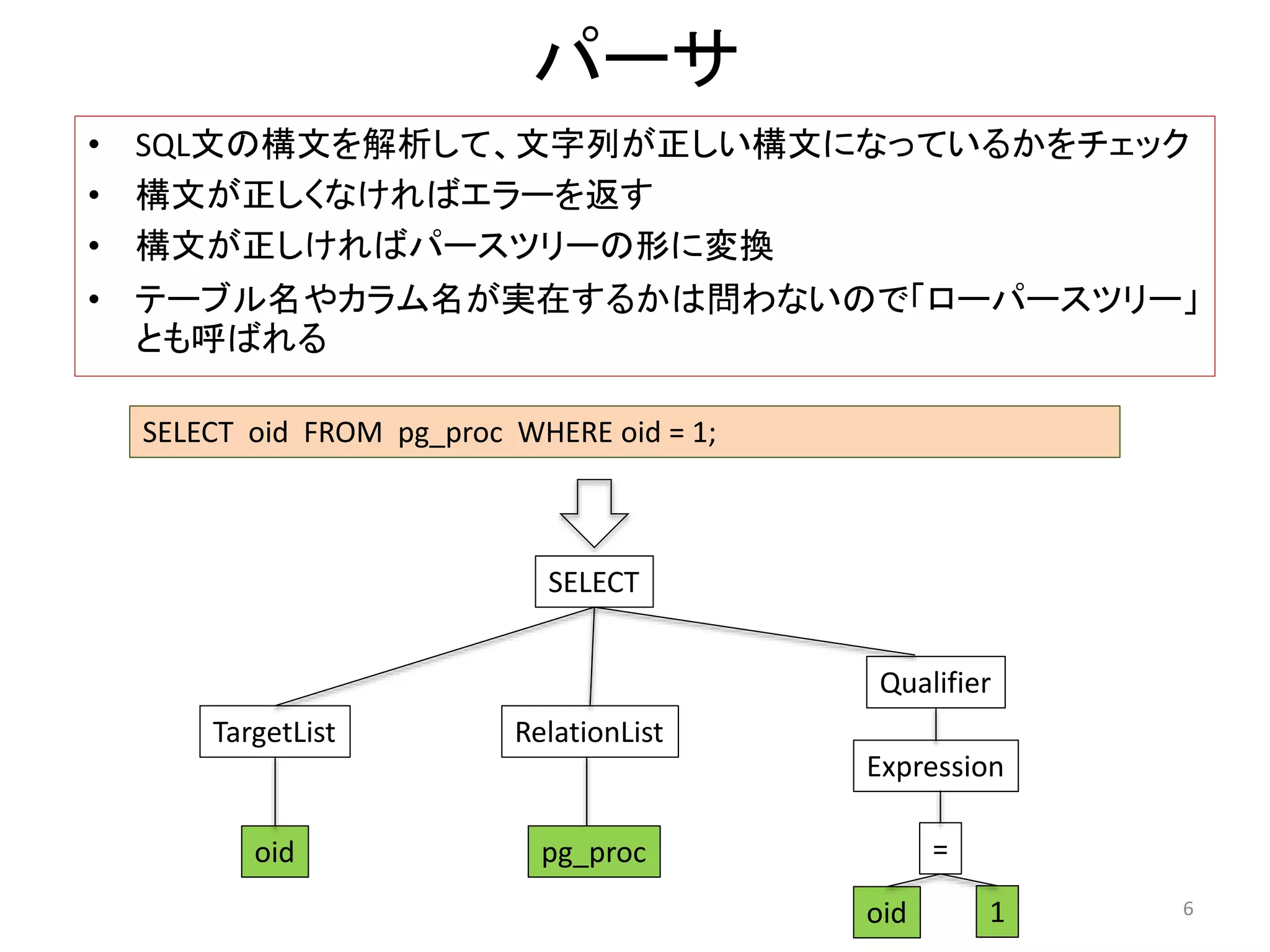
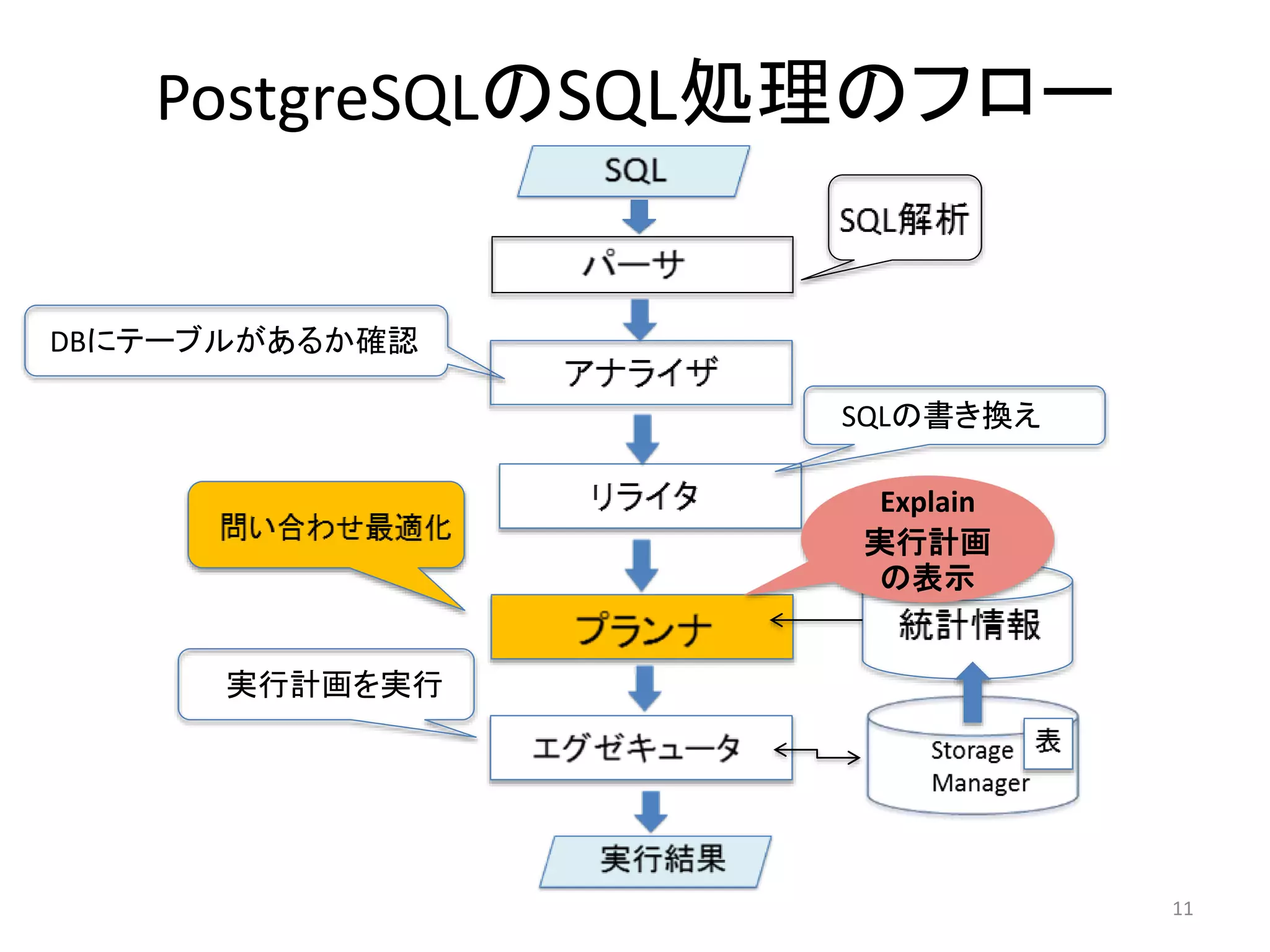
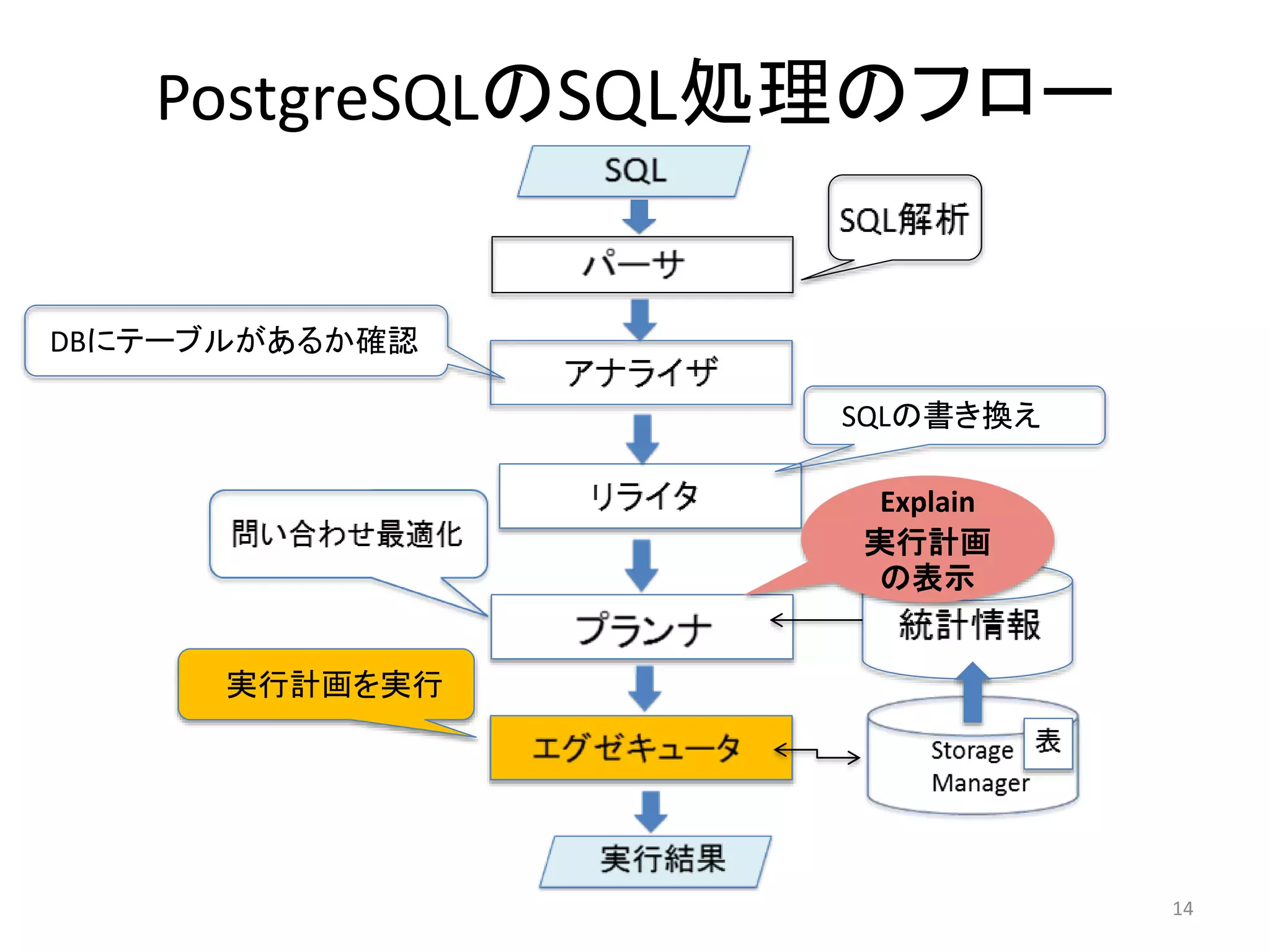
4. 5. 6. パーサ
• SQL文の構文を解析して、文字列が正しい構文になっているかをチェック
• 構文が正しくなければエラーを返す
• 構文が正しければパースツリーの形に変換
• テーブル名やカラム名が実在するかは問わないので「ローパースツリー」
とも呼ばれる
SELECT oid FROM pg_proc WHERE oid = 1;
SELECT
TargetList
oid
RelationList
pg_proc
Qualifier
Expression
=
oid 1 6
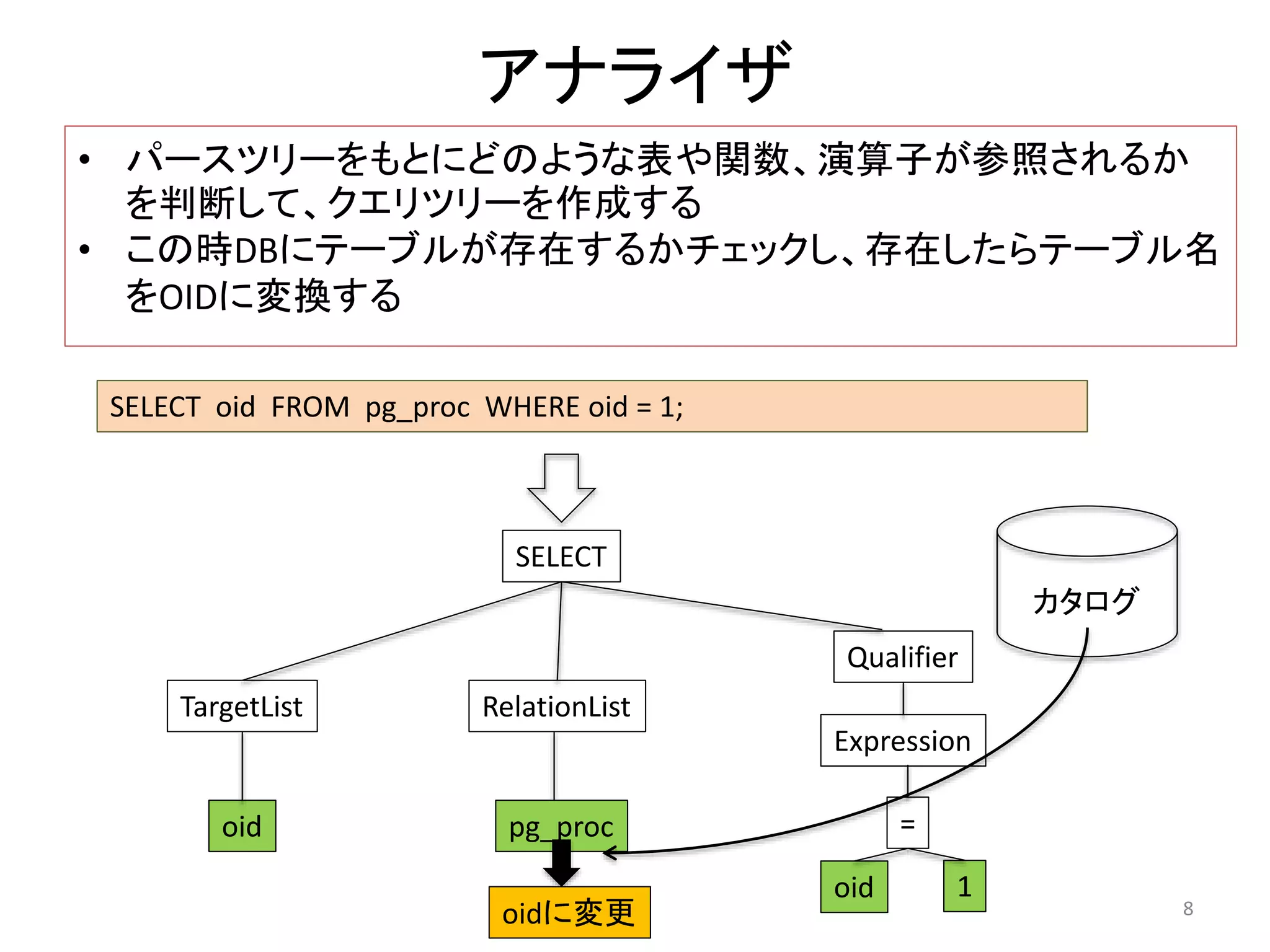
7. 8. アナライザ
• パースツリーをもとにどのような表や関数、演算子が参照されるか
を判断して、クエリツリーを作成する
• この時DBにテーブルが存在するかチェックし、存在したらテーブル名
をOIDに変換する
SELECT oid FROM pg_proc WHERE oid = 1;
SELECT
TargetList
oid
RelationList
pg_proc
Qualifier
Expression
=
oid 1
カタログ
oidに変更8
9. 10. 11. 12. プランナ
• クエリツリーを解析して、最も効率的にSQLを実行するための
データへのアクセス方法(アクセスパス)や結合などの処理を
求める
• 処理の種類によりアクセスパスの種類がある
• アクセスパスが単位となり、データ取得までのコストが計算さ
れる
• 実行計画はコストが最小のものが選ばれる(問い合わせの最
適化)
• ここでの実行計画のコストはあくまで推定値
クエリツリー
パス単位でコスト計算
最小コストのものを実行計画に
アクセスパスの種類
・テーブル全件スキャン
・テーブルをインデックスを使って
スキャン
・テーブル結合
・関数を実行する
などなど、、、
12
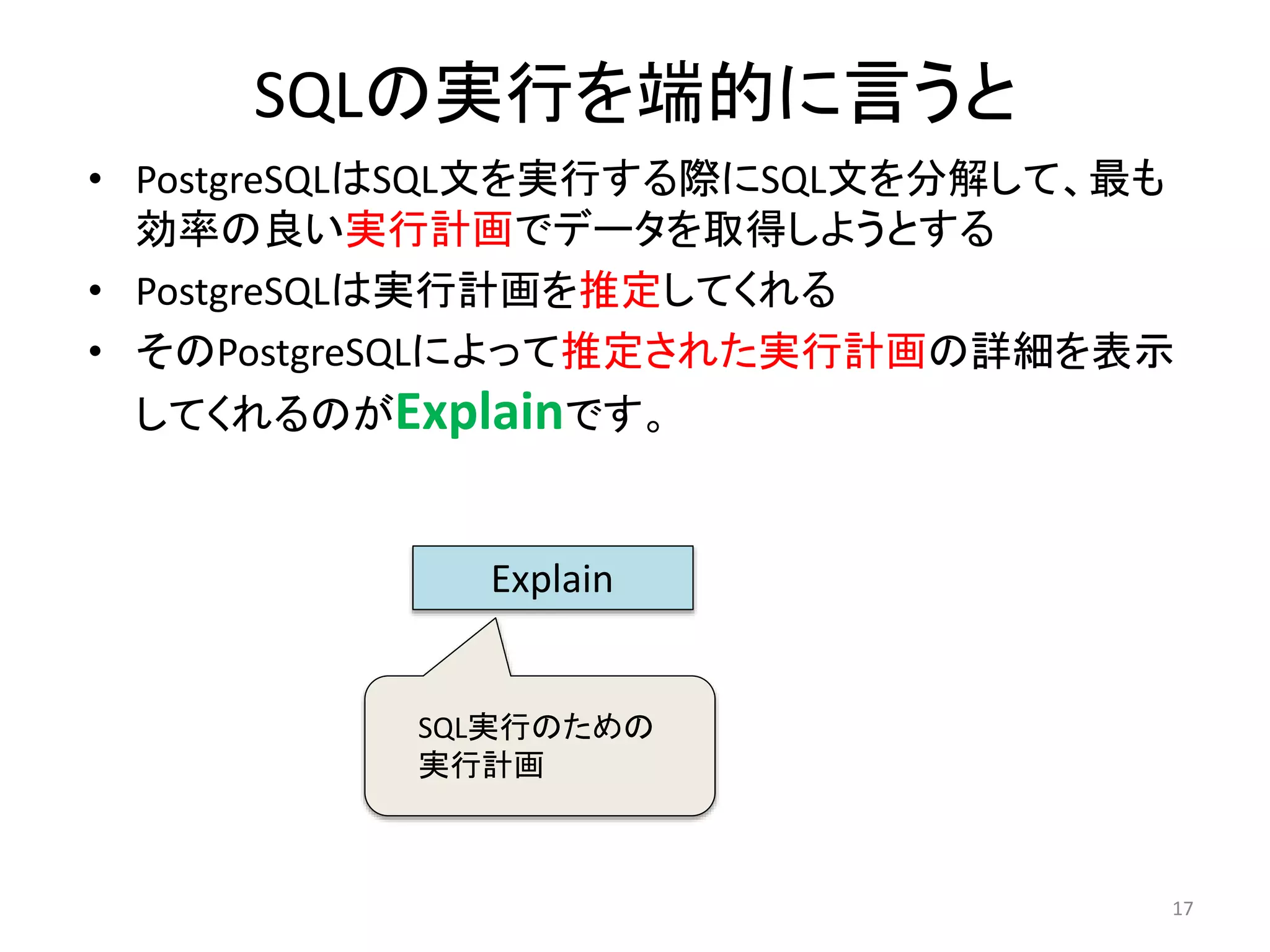
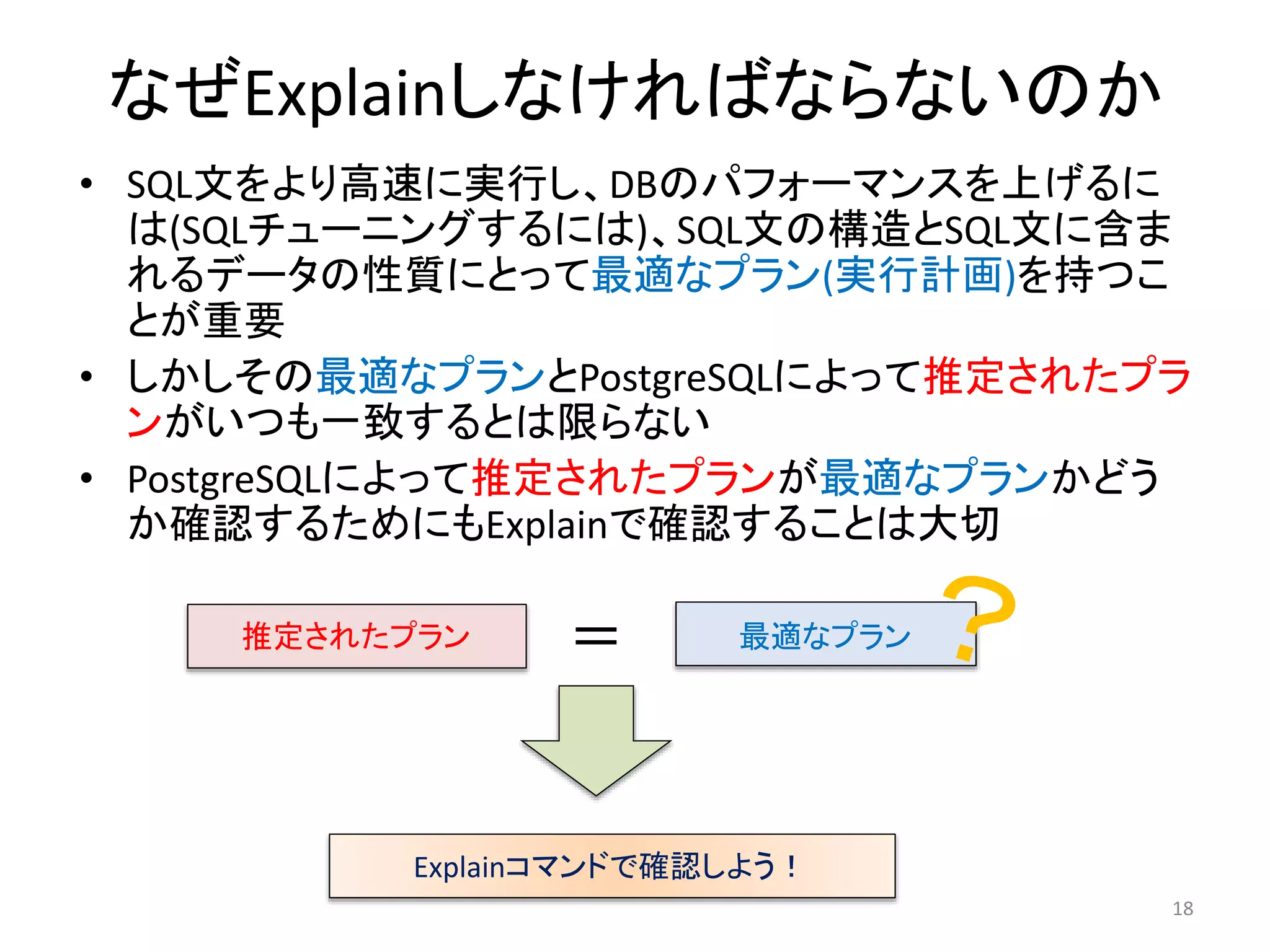
13. 14. 15. 16. 17. 18. なぜExplainしなければならないのか
• SQL文をより高速に実行し、DBのパフォーマンスを上げるに
は(SQLチューニングするには)、SQL文の構造とSQL文に含ま
れるデータの性質にとって最適なプラン(実行計画)を持つこ
とが重要
• しかしその最適なプランとPostgreSQLによって推定されたプラ
ンがいつも一致するとは限らない
• PostgreSQLによって推定されたプランが最適なプランかどう
か確認するためにもExplainで確認することは大切
18
推定されたプラン= 最適なプラン
Explainコマンドで確認しよう!
19. 20. Explain Planの例
=# EXPLAIN SELECT * FROM pg_proc
ORDER BY proname;
QUERY PLAN
----------------------------------------------------
Sort (cost=181.55..185.92 rows=1747 width=322)
Sort Key: proname
-> Seq Scan on pg_proc
(cost=0.00..87.47 rows=1747 width=322)
20
21. 21
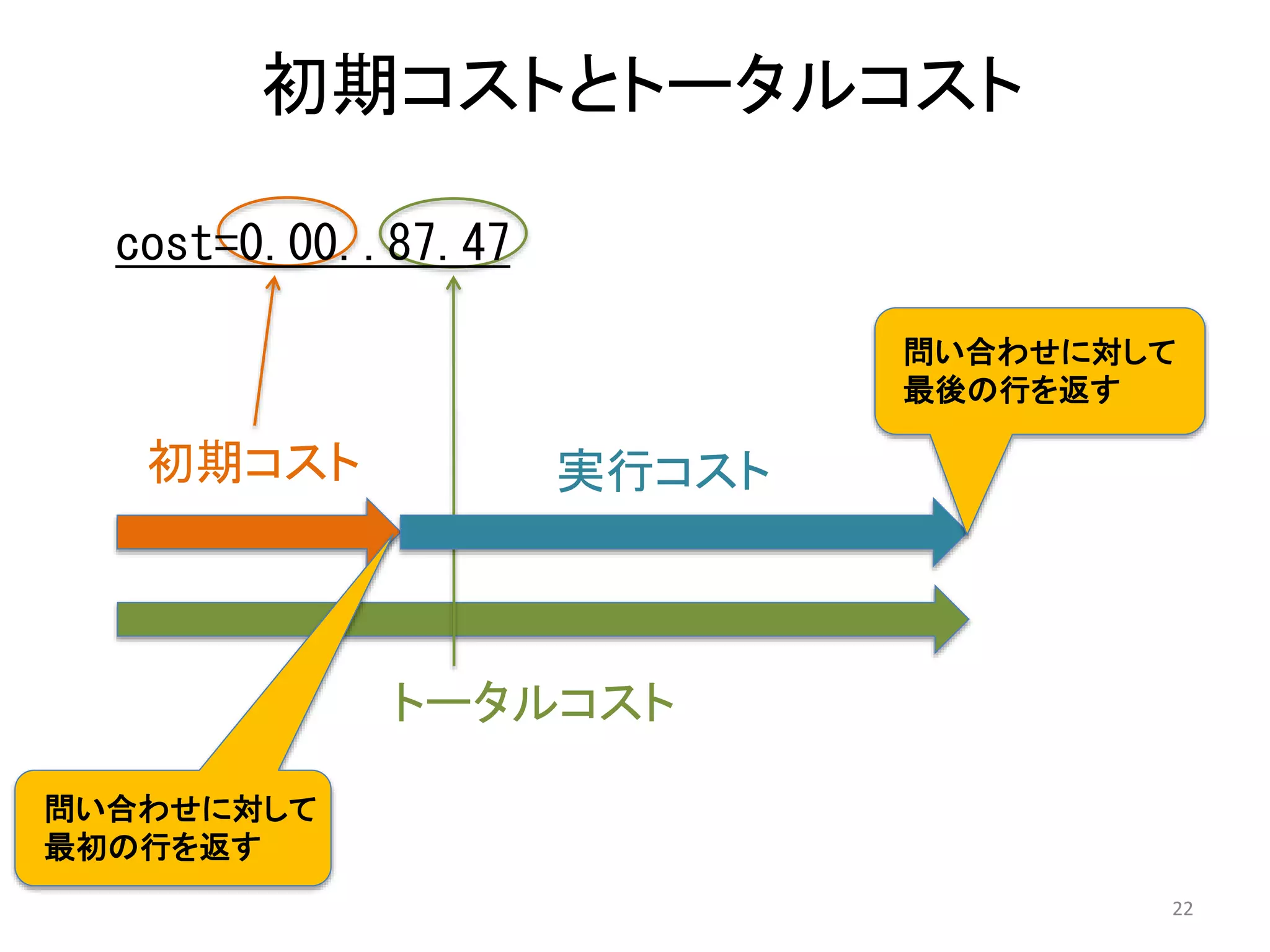
Explaining → Cost
=# EXPLAIN SELECT oid FROM pg_proc;
• コストは、プランナがさまざまなプランの中からある特定のプランを選
ぶための指標である
• 2つのコスト: 初期コスト(左) とトータルコスト(右)
– 実行計画の比較で重要なのはトータルコスト。
– いくつかの演算子には初期コストがある。無いものもある。
– コストは推定値に過ぎない。その算出は結構複雑。
• 値はシーケンシャルI/Oで1ページを読み込むコストを1.0 とした際の
相対値で示される。
QUERY PLAN
------------------------------------------
Seq Scan on pg_proc
(cost=0.00..87.47 rows=1747 width=4)
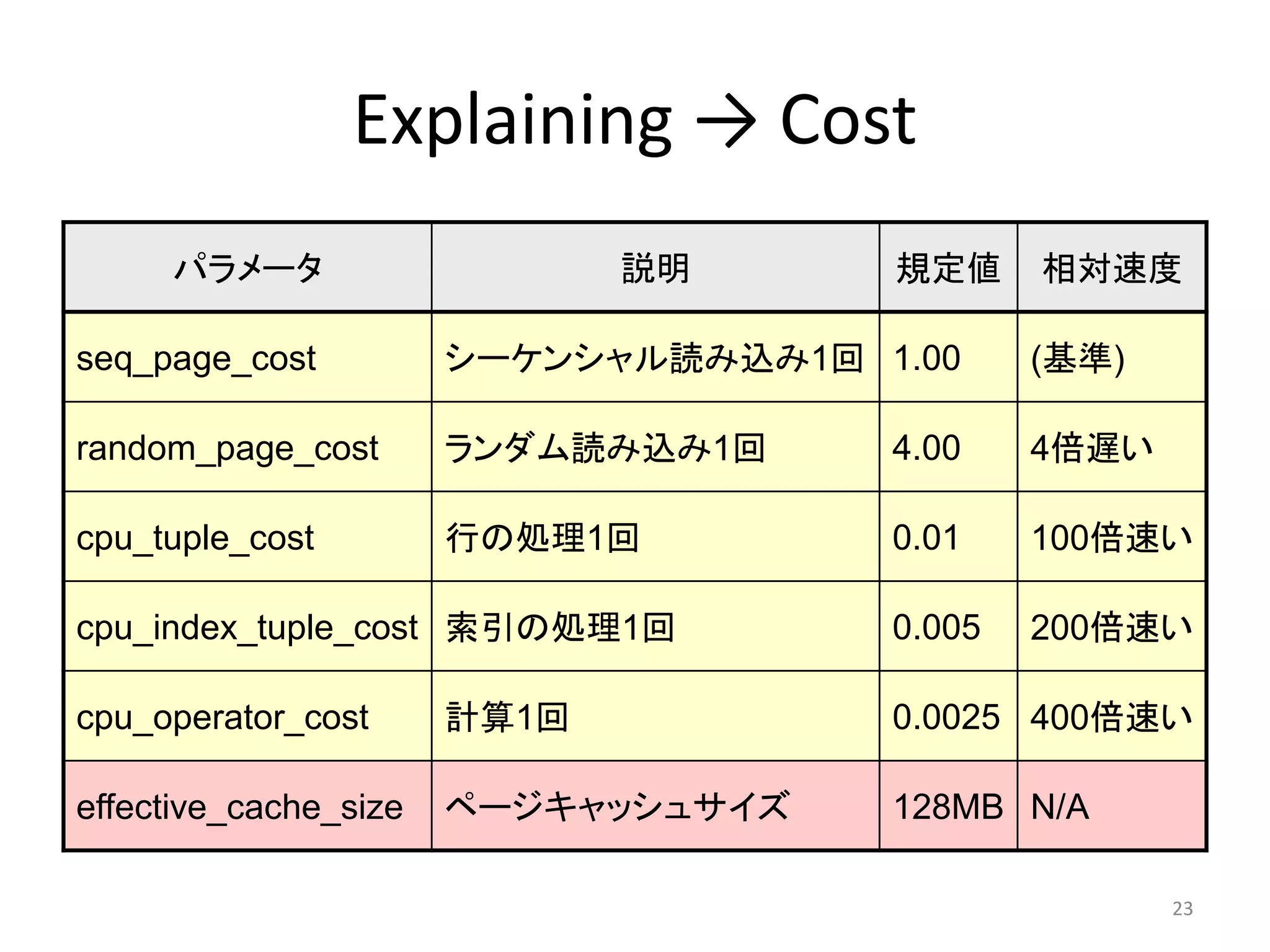
22. 23. Explaining → Cost
パラメータ説明規定値相対速度
seq_page_cost シーケンシャル読み込み1回1.00 (基準)
random_page_cost ランダム読み込み1回4.00 4倍遅い
cpu_tuple_cost 行の処理1回0.01 100倍速い
cpu_index_tuple_cost 索引の処理1回0.005 200倍速い
cpu_operator_cost 計算1回0.0025 400倍速い
effective_cache_size ページキャッシュサイズ128MB N/A
23
24. 24
Explaining → Rows
=# EXPLAIN SELECT oid FROM pg_proc;
QUERY PLAN
------------------------------------------
Seq Scan on pg_proc
(cost=0.00..87.47 rows=1747 width=4)
• 推定された行数を表示する
• PostgreSQL 8.0以前では、一度もVACUUM/ANALYZEされて
いないテーブルについては1000行がデフォルト。
• 実際の値と大きくかけ離れている場合、vacuum あるいは
analyzeをすべきというサインである。
25. 一般的なデータ型のサイズについて
25
Explaining → Widths
=# EXPLAIN SELECT oid FROM pg_proc;
QUERY PLAN
------------------------------------------
Seq Scan on pg_proc
(cost=0.00..87.47 rows=1747 width=4)
• このレベルにおける推定さ
れた入力サイズを表示する。
• それほど重要ではない
smallint 2
integer 4
bigint 8
boolean 1
char(n) n+1
~
n+4
varchar(n)
text [ n文字]
26. 27. 27
Explaining → Explain Analyze
=# EXPLAIN ANALYZE SELECT oid FROM pg_proc;
QUERY PLAN
------------------------------------------
Seq Scan on pg_proc
(cost=0.00..87.47 rows=1747 width=4)
(actual time=0.077..17.082 rows=1747 loops=1)
Total runtime: 20.125 ms
• 実際にSQLを実行し、実際の情報を表示する。
• 時間はミリ秒で表示される。「コスト」とは無関係。
• 全体の実行時間も表示される。
• 「loops」は処理の繰り返し回数。実行時間(time)は繰り返し
全体の時間を表す。
28. 29. Explain演算子とは
• SQLを実行するための内部的な処理の計算タイプ
• 処理の内容に応じていくつかの種類がある
• PostgreSQLのプランナは、統計情報や作業領域
(work_mem)の大きさなどをもとに、複数の演算子を
組み合わせ、最も最適と推定される実行計画を選
択する
• この演算子を変更して実行計画を変更するのがSQL
チューニング
→演算子の処理について知っておくことが大切
29
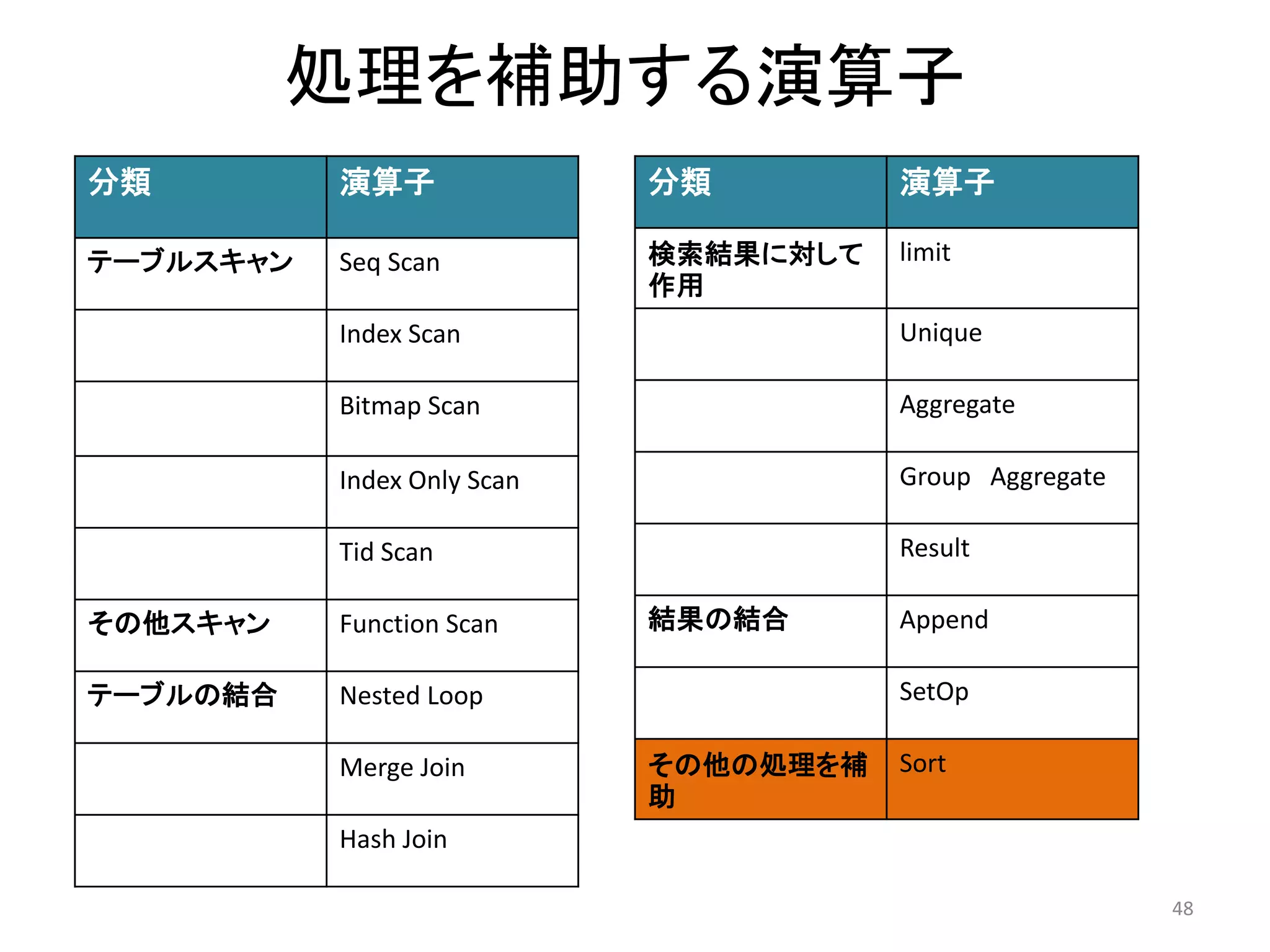
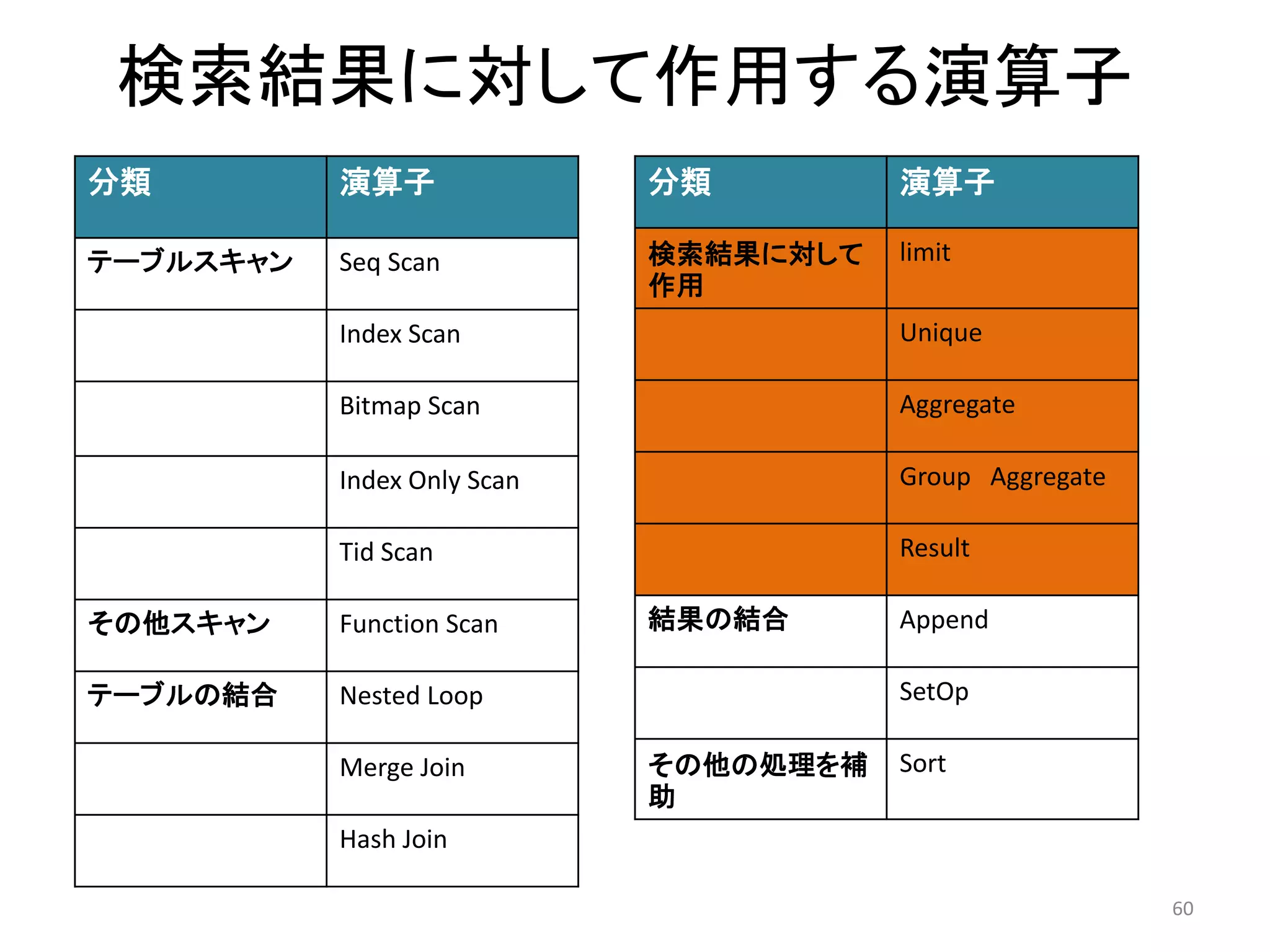
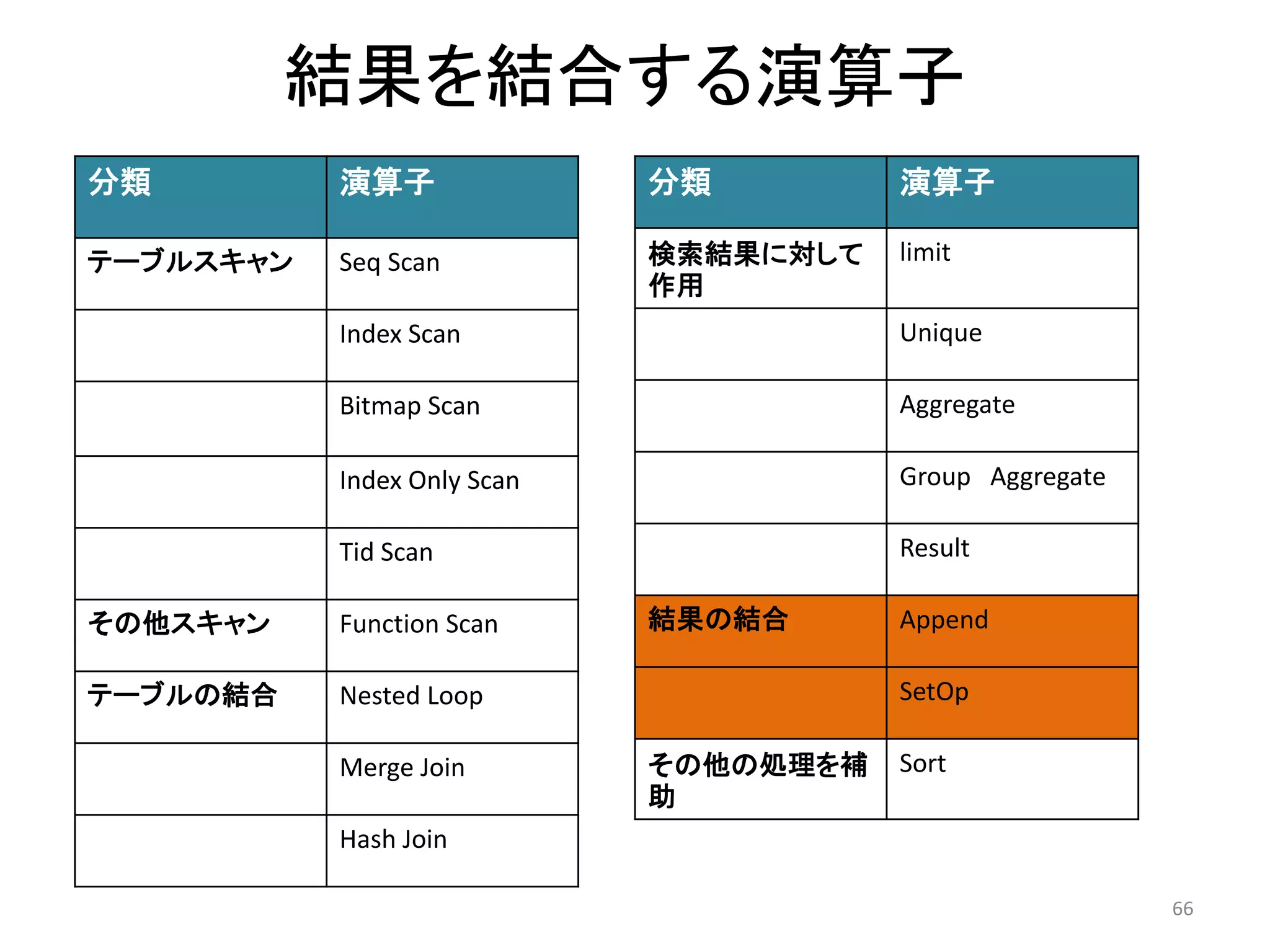
30. 主な演算子一覧
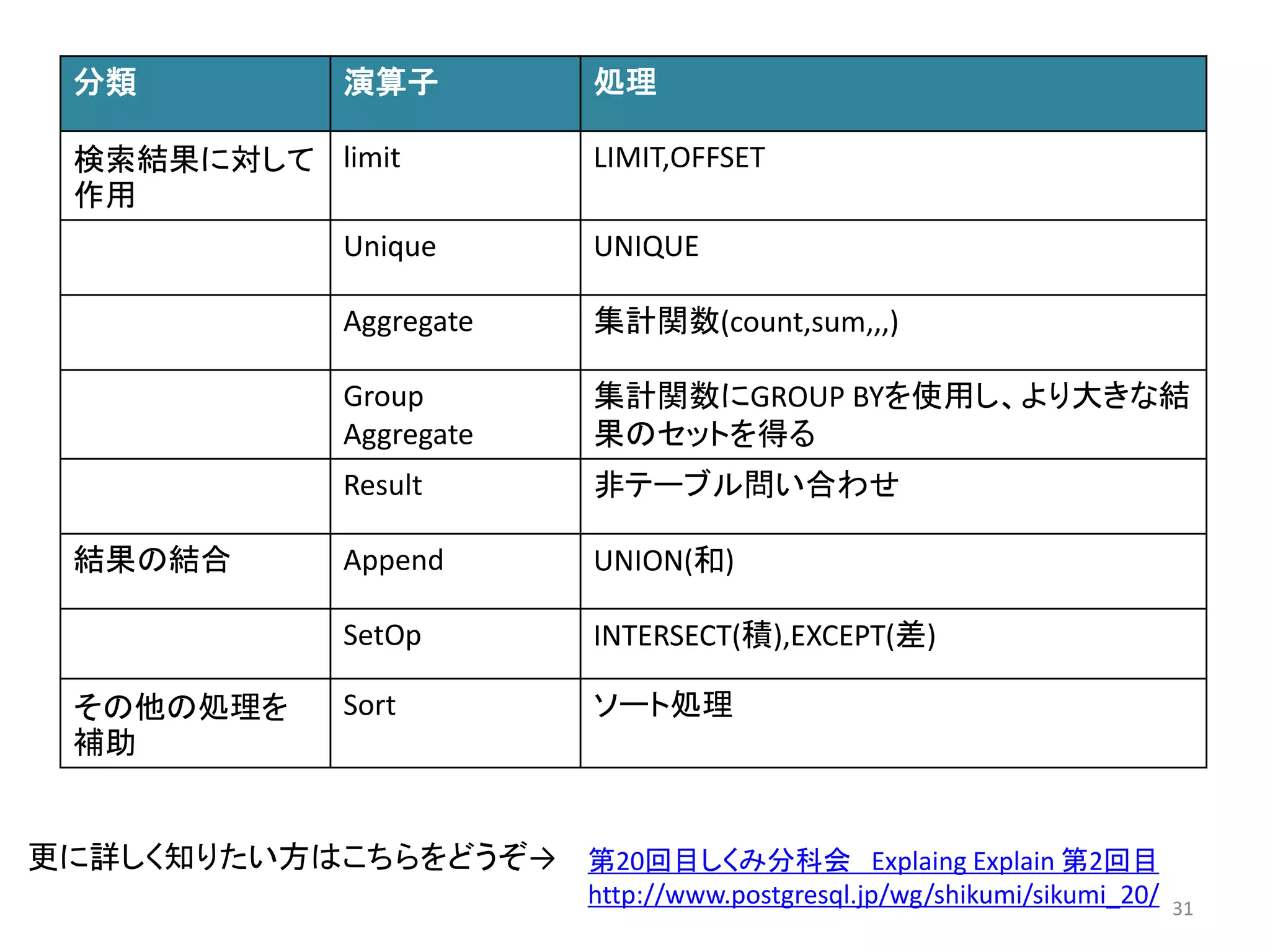
分類演算子処理
テーブルスキャンSeq scan インデックスを使用せず、全件を検索
Index scan インデックスを使用してスキャン
Bitmap scan ビットマップを使用してスキャン
Index only scan 問い合わせがインデックスに含まれるカラム
のみで完結する場合のスキャン
Tid scan 検索条件がタプルID(ctid)のスキャン
その他のスキャンFunction scan 関数がデータをgatherした結果をスキャン
テーブルの結合Nested Loop ネステッド・ループ結合を行う
Merge Join ソート・マージ結合を行う
Hash Join ハッシュ結合を行う
30
31. 分類演算子処理
検索結果に対して
作用
limit LIMIT,OFFSET
Unique UNIQUE
Aggregate 集計関数(count,sum,,,)
Group
Aggregate
集計関数にGROUP BYを使用し、より大きな結
果のセットを得る
Result 非テーブル問い合わせ
結果の結合Append UNION(和)
SetOp INTERSECT(積),EXCEPT(差)
その他の処理を
補助
Sort ソート処理
31
更に詳しく知りたい方はこちらをどうぞ→ 第20回目しくみ分科会Explaing Explain 第2回目
http://www.postgresql.jp/wg/shikumi/sikumi_20/
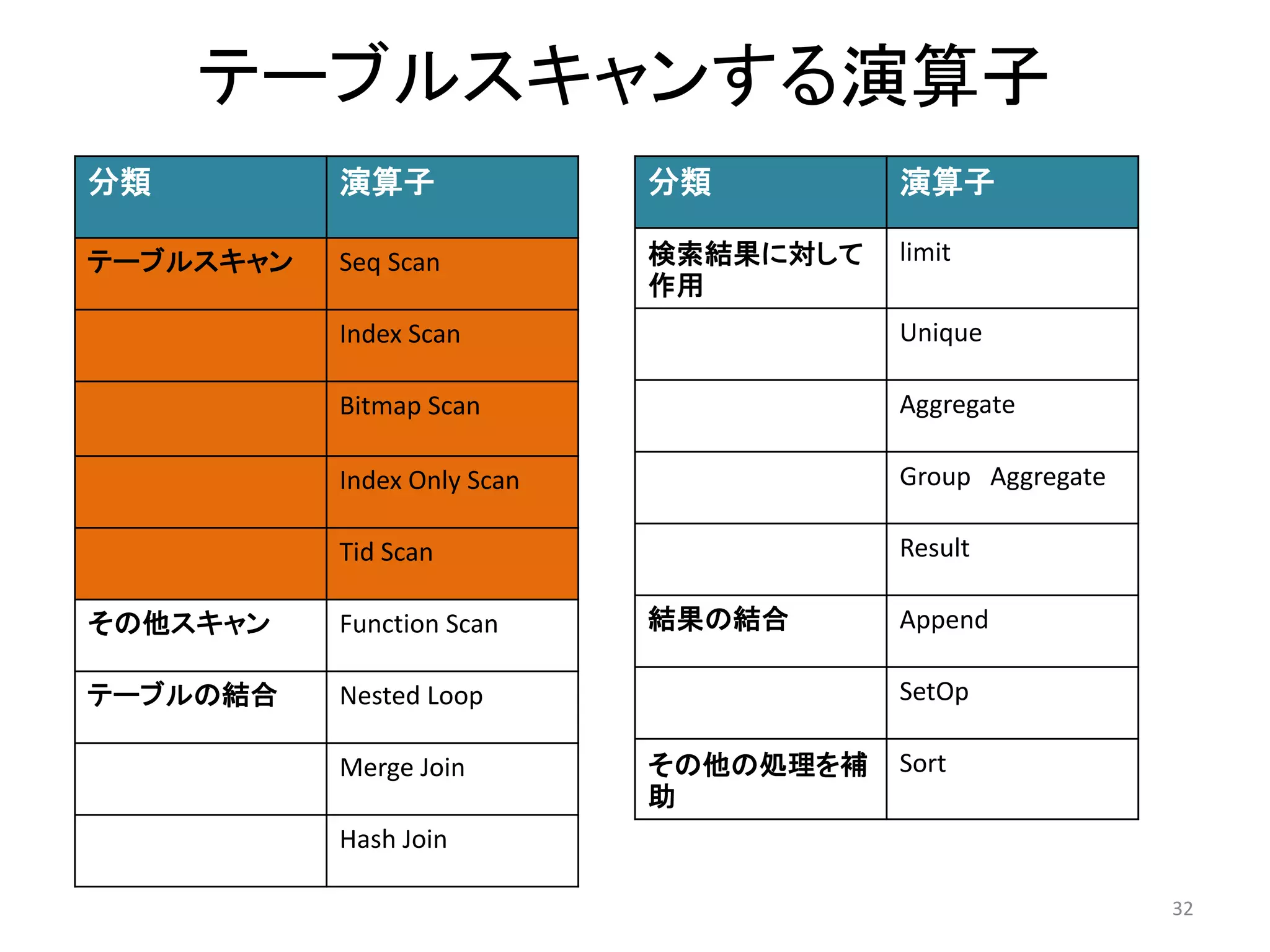
32. テーブルスキャンする演算子
32
分類演算子
テーブルスキャンSeq Scan
Index Scan
Bitmap Scan
Index Only Scan
Tid Scan
その他スキャンFunction Scan
テーブルの結合Nested Loop
Merge Join
Hash Join
分類演算子
検索結果に対して
作用
limit
Unique
Aggregate
Group Aggregate
Result
結果の結合Append
SetOp
その他の処理を補
助
Sort
33. 33
Seq Scan 演算子
=# EXPLAIN SELECT oid FROM pg_proc WHERE oid = 1;
QUERY PLAN
--------------------------------------------------
Seq Scan on pg_proc
(cost=0.00..92.12 rows=1 width=4)
Filter: (oid = 1::oid)
• 最も基本。単に表を最初から最後へとスキャンする
• 条件にかかわらず各行をチェックする
• 大きなテーブルはインデックススキャンの方が良い
• コスト(開始コスト無し), 行(タプル), 幅(oid)
• トータルコストは92.12
34. 34
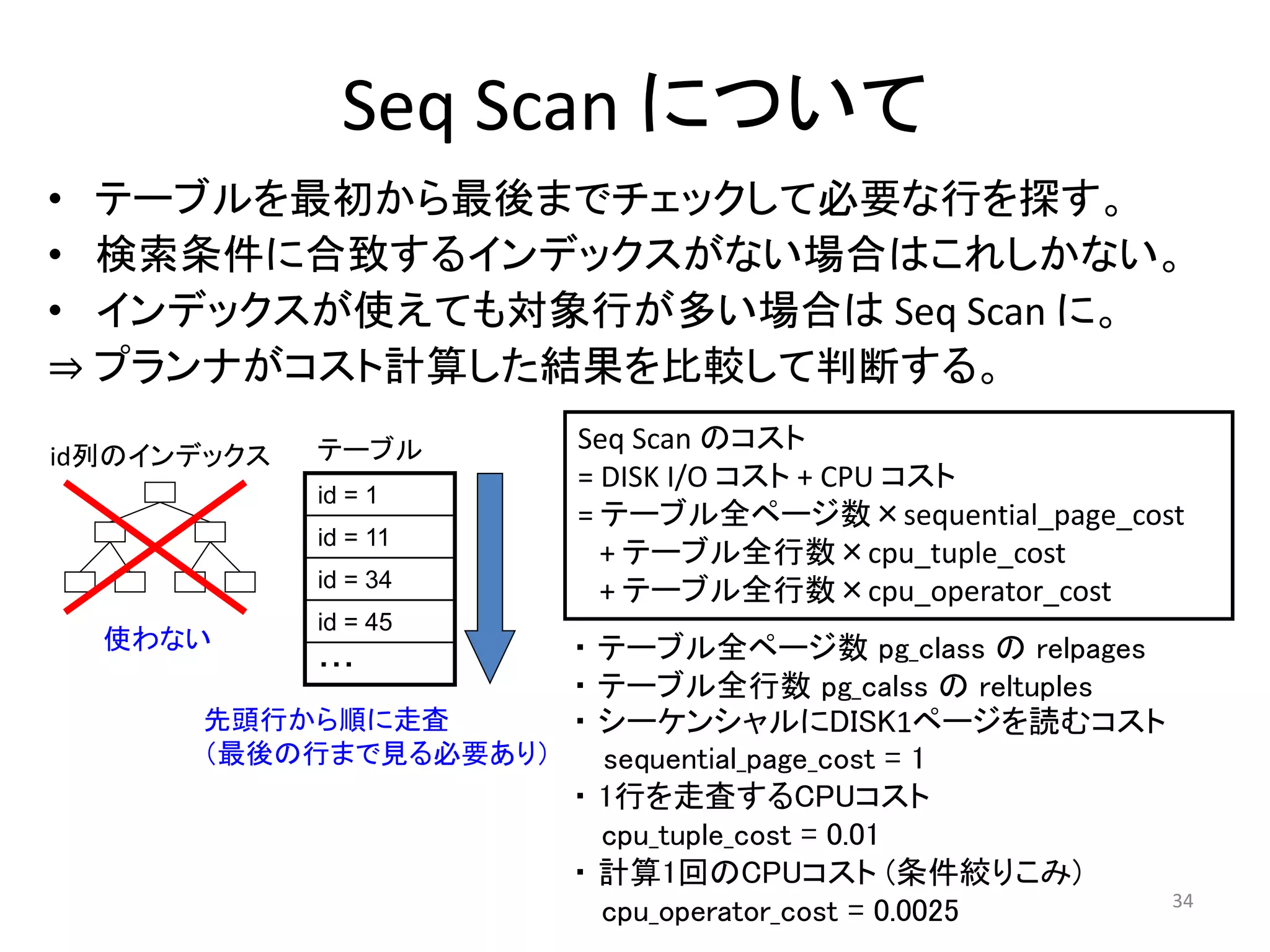
Seq Scan について
• テーブルを最初から最後までチェックして必要な行を探す。
• 検索条件に合致するインデックスがない場合はこれしかない。
• インデックスが使えても対象行が多い場合はSeq Scan に。
⇒ プランナがコスト計算した結果を比較して判断する。
id列のインデックステーブル
id = 1
id = 11
id = 34
id = 45
・・・
使わない
先頭行から順に走査
(最後の行まで見る必要あり)
Seq Scan のコスト
= DISK I/O コスト+ CPU コスト
= テーブル全ページ数×sequential_page_cost
+ テーブル全行数×cpu_tuple_cost
+ テーブル全行数×cpu_operator_cost
・テーブル全ページ数pg_class のrelpages
・テーブル全行数pg_calss のreltuples
・シーケンシャルにDISK1ページを読むコスト
sequential_page_cost = 1
・1行を走査するCPUコスト
cpu_tuple_cost = 0.01
・計算1回のCPUコスト(条件絞りこみ)
cpu_operator_cost = 0.0025
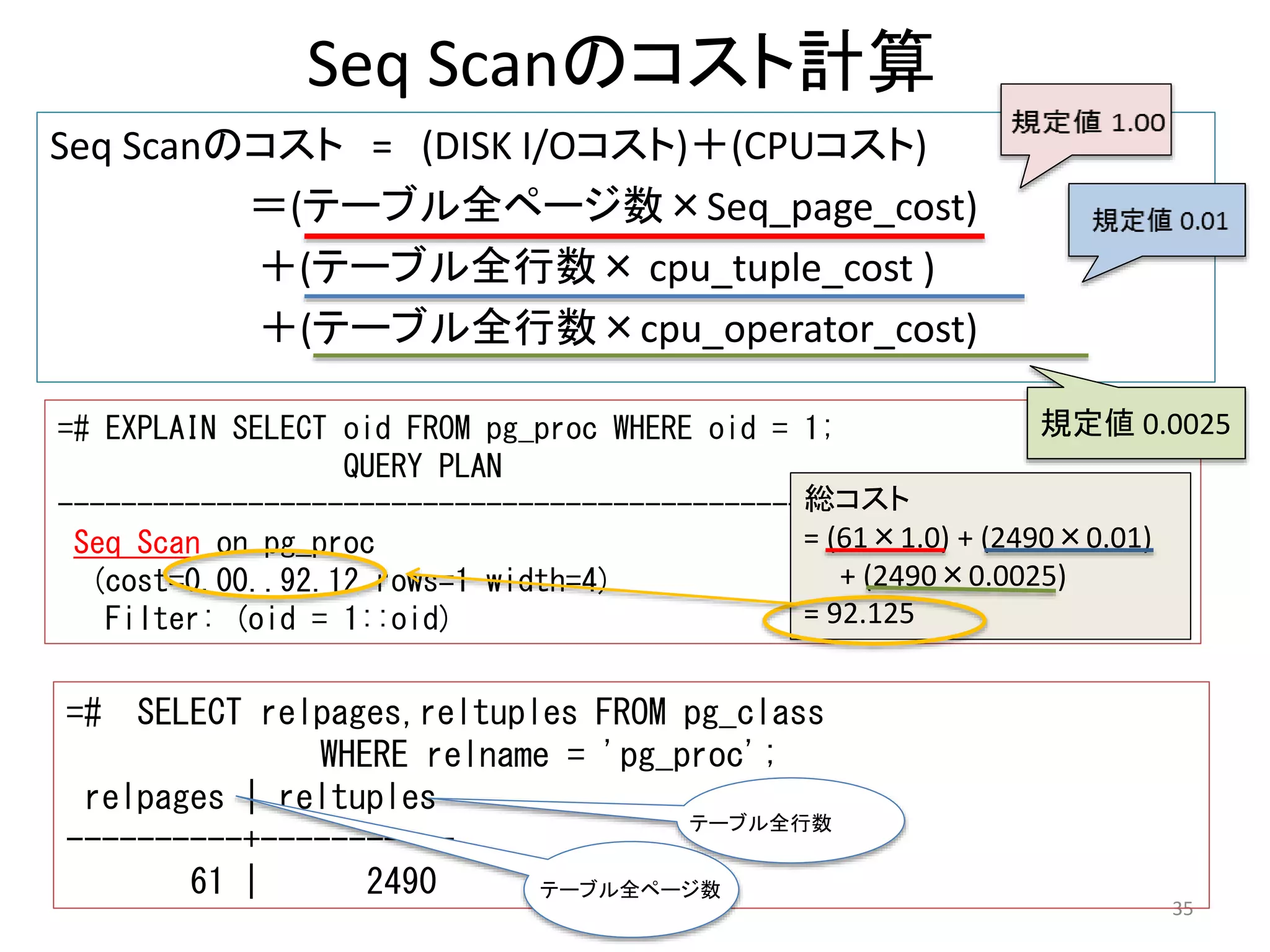
35. Seq Scanのコスト計算
Seq Scanのコスト= (DISK I/Oコスト)+(CPUコスト)
=(テーブル全ページ数×Seq_page_cost)
+(テーブル全行数×cpu_tuple_cost )
+(テーブル全行数×cpu_operator_cost)
35
=# EXPLAIN SELECT oid FROM pg_proc WHERE oid = 1;
QUERY PLAN
--------------------------------------------------
Seq Scan on pg_proc
(cost=0.00..92.12 rows=1 width=4)
Filter: (oid = 1::oid)
=# SELECT relpages,reltuples FROM pg_class
WHERE relname = 'pg_proc';
relpages | reltuples
----------+-----------
61 | 2490
総コスト
= (61×1.0) + (2490×0.01)
+ (2490×0.0025)
= 92.125
テーブル全行数
テーブル全ページ数
規定値0.0025
36. -----------------------------------------------------
Index Scan using pg_proc_oid_index on pg_proc
36
Index Scan 演算子
=# EXPLAIN SELECT oid FROM pg_proc WHERE oid=1;
QUERY PLAN
(cost=0.00..5.99 rows=1 width=4)
Index Cond: (oid = 1::oid)
• 特に大きなテーブルではコストが低くなるので選ば
れる可能性が高い
• Index Condが無い場合は、ソートの代わりとして使
われるインデックス順のフルスキャンを表す
37. 37
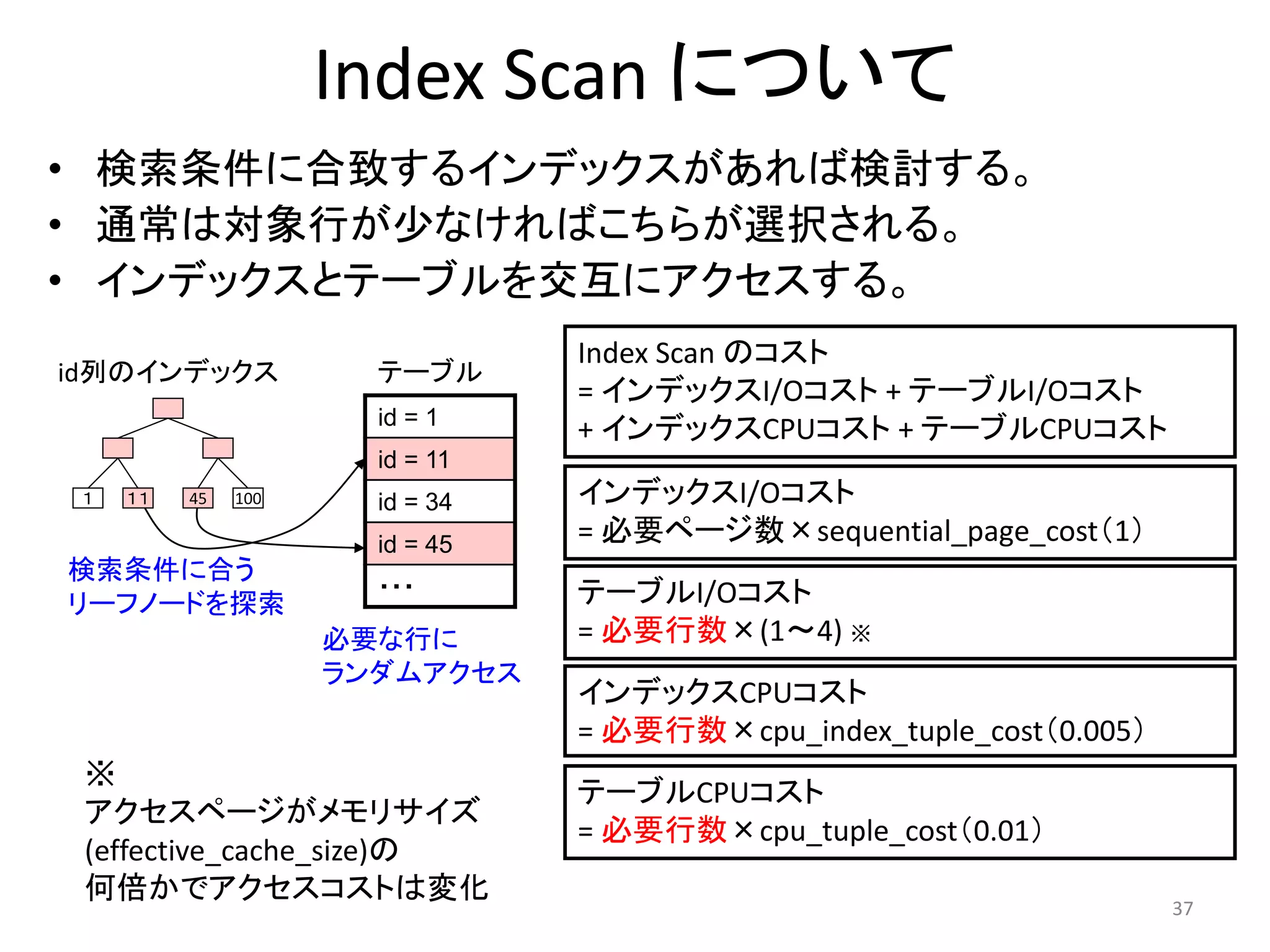
Index Scan について
• 検索条件に合致するインデックスがあれば検討する。
• 通常は対象行が少なければこちらが選択される。
• インデックスとテーブルを交互にアクセスする。
id列のインデックステーブル
id = 1
id = 11
id = 34
id = 45
・・・
1 11 45 100
検索条件に合う
リーフノードを探索
必要な行に
ランダムアクセス
Index Scan のコスト
= インデックスI/Oコスト+ テーブルI/Oコスト
+ インデックスCPUコスト+ テーブルCPUコスト
インデックスI/Oコスト
= 必要ページ数×sequential_page_cost(1)
テーブルI/Oコスト
= 必要行数×(1~4) ※
インデックスCPUコスト
= 必要行数×cpu_index_tuple_cost(0.005)
テーブルCPUコスト
= 必要行数×cpu_tuple_cost(0.01)
※
アクセスページがメモリサイズ
(effective_cache_size)の
何倍かでアクセスコストは変化
38. 38
必要行数って何?
• 指定条件を満たす行数
• Explain の実行結果で「rows=100」とか表示される値。
• プランナがテーブルの統計情報から行数を予測。
⇒ 実際に検索した時の行数とは異なる。
• 必要行数= 選択度×テーブル行数
• 「選択度」は対象データがカラムに存在する割合
• 選択度は対象カラムの統計情報を使って計算
• 各カラム値の分布はpg_stats(pg_statistic)でわかる。
⇒ ANALYZE時に収集した情報が格納されている。
39. 39
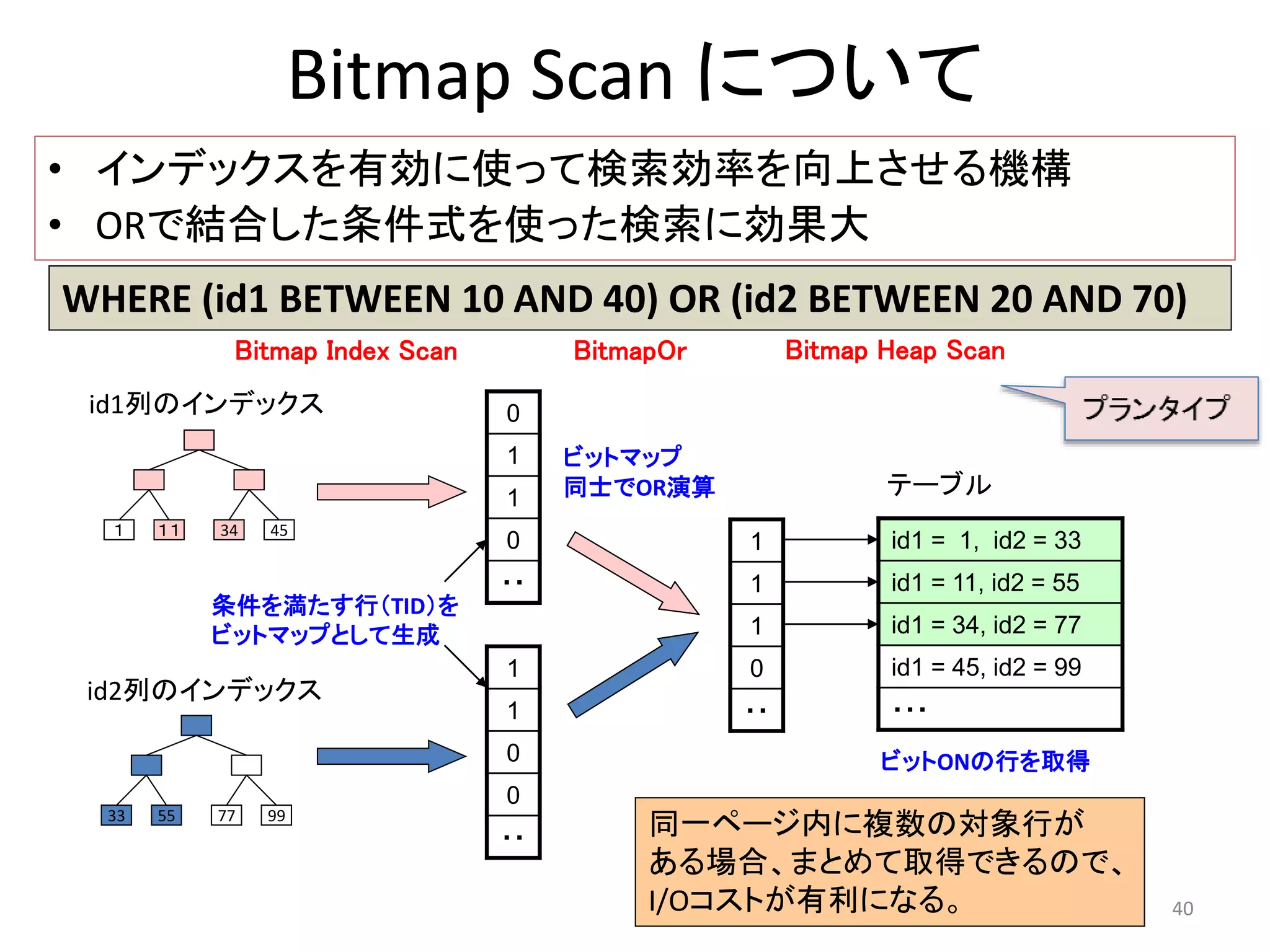
Bitmap Scan 演算子
• 8.1で追加された
• BitmapOr, BitmapAnd で複数のビットマップを合体
• リレーションの”ビットマップ“をメモリ内で作成する
40. WHERE (id1 BETWEEN 10 AND 40) OR (id2 BETWEEN 20 AND 70)
40
Bitmap Scan について
• インデックスを有効に使って検索効率を向上させる機構
• ORで結合した条件式を使った検索に効果大
id1 = 1, id2 = 33
id1 = 11, id2 = 55
id1 = 34, id2 = 77
id1 = 45, id2 = 99
・・・
1 11 34 45
テーブル
id1列のインデックス
ビットONの行を取得
id2列のインデックス
33 55 77 99
0
1
1
0
・・
1
1
0
0
・・
Bitmap Index Scan
1
1
1
0
・・
BitmapOr
条件を満たす行(TID)を
ビットマップとして生成
ビットマップ
同士でOR演算
Bitmap Heap Scan
同一ページ内に複数の対象行が
ある場合、まとめて取得できるので、
I/Oコストが有利になる。
41. Index Only Scan
• 9.2で追加された
• 取得したい値にインデックスが含まれるとき、テーブ
ルのアクセスを省略して検索する
• 非常に高速(しかしindex only scanが選ばれるには
条件が…)
41
42. Index Only Scanのスキャン方法
• Index Only ScanはまずインデックスからVisibility
Mapを参照しに行く(早速テーブルには行かない)
• そして高速に値を返せるか返せないかは、実はこの
Visibility Mapにかかっている
→このVisibility Mapって一体何者なの?
42
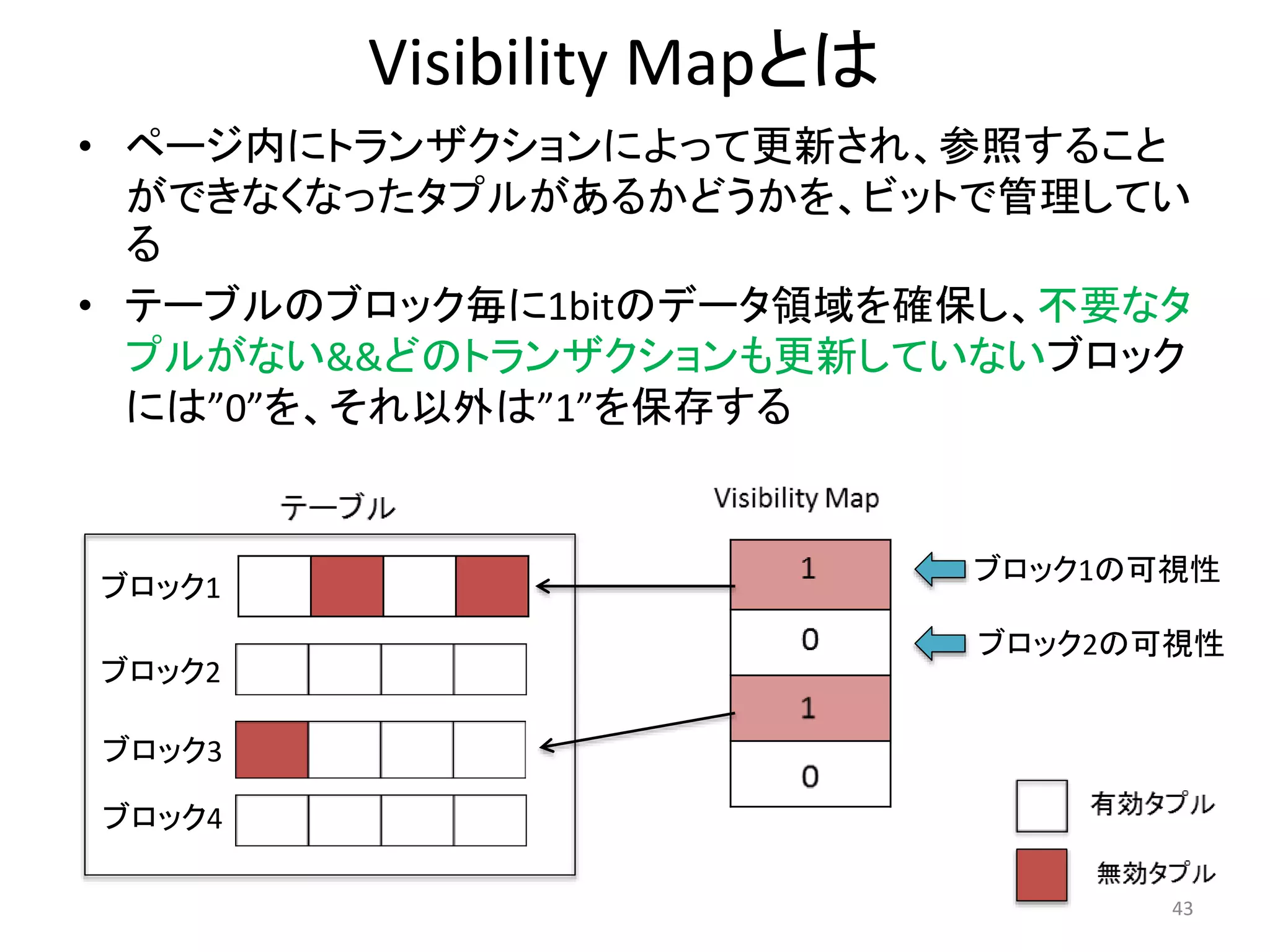
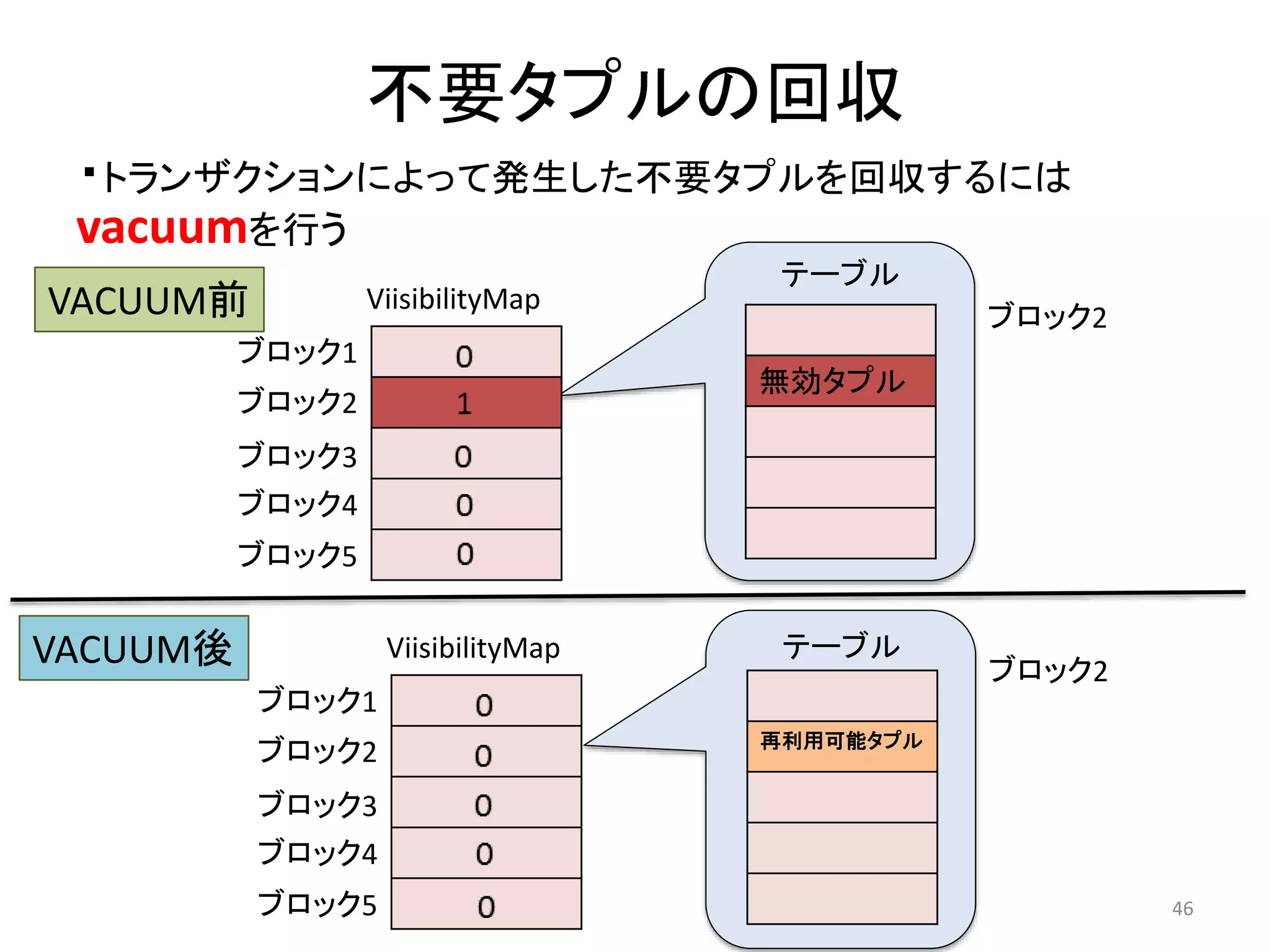
43. Visibility Mapとは
• ページ内にトランザクションによって更新され、参照すること
ができなくなったタプルがあるかどうかを、ビットで管理してい
る
• テーブルのブロック毎に1bitのデータ領域を確保し、不要なタ
プルがない&&どのトランザクションも更新していないブロック
には”0”を、それ以外は”1”を保存する
ブロック1の可視性
ブロック2の可視性
43
ブロック1
ブロック2
ブロック3
ブロック4
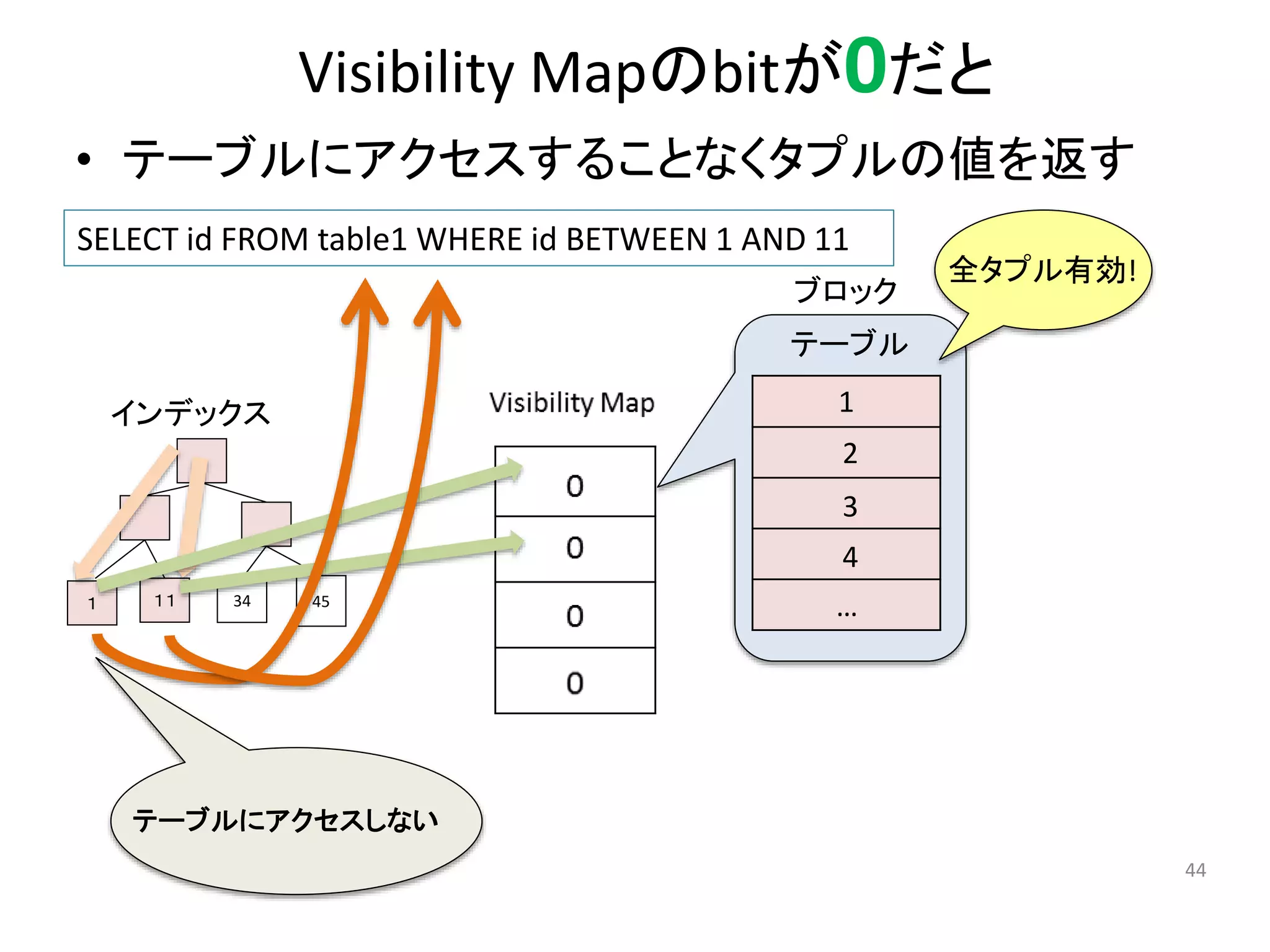
44. Visibility Mapのbitが0だと
• テーブルにアクセスすることなくタプルの値を返す
44
SELECT id FROM table1 WHERE id BETWEEN 1 AND 11
ブロック
1
2
3
4
…
全タプル有効!
インデックス
1 11 34 45
テーブル
テーブルにアクセスしない
45. Visibility Mapのbitが1だと
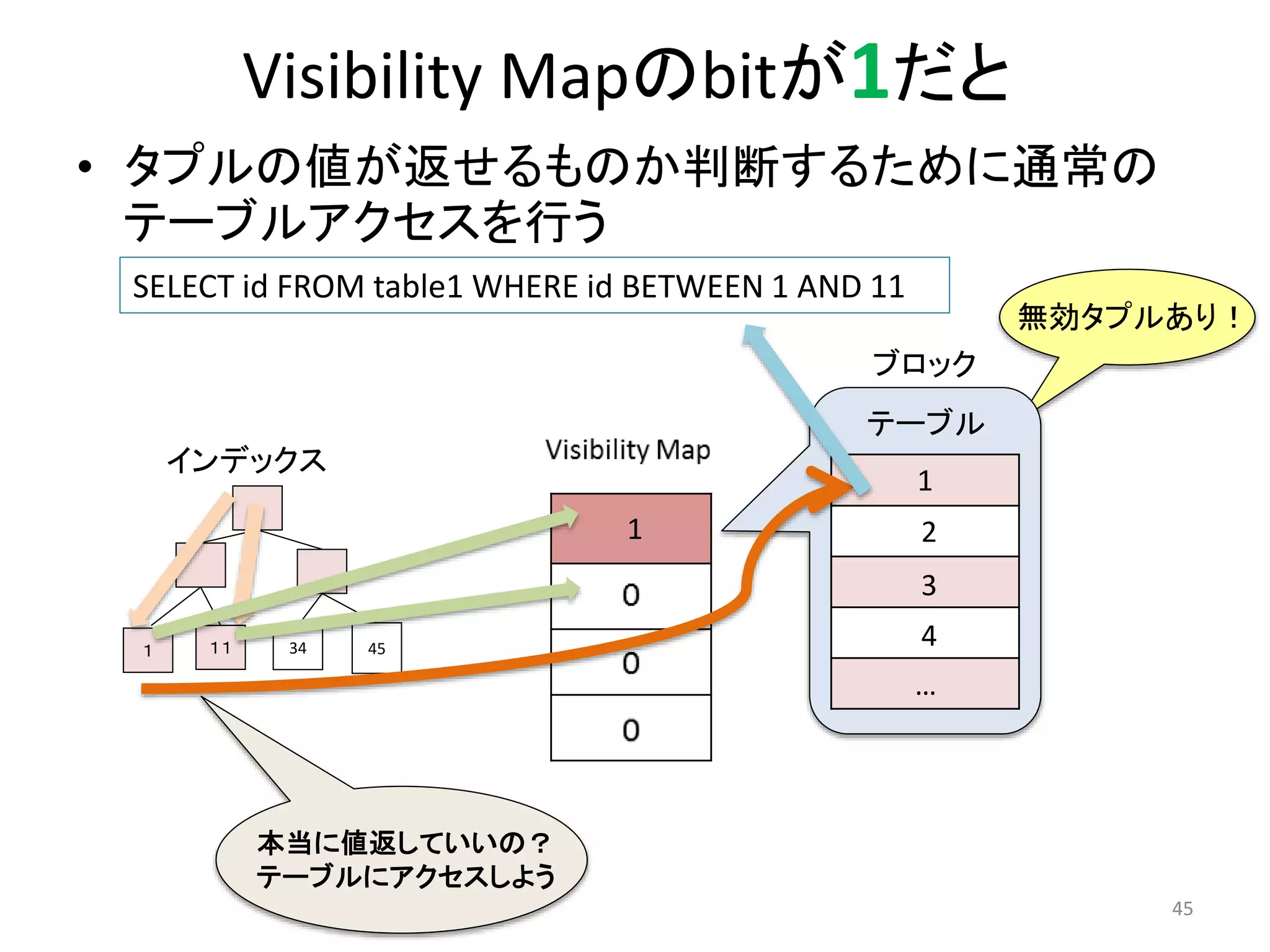
• タプルの値が返せるものか判断するために通常の
テーブルアクセスを行う
無効タプルあり!
45
SELECT id FROM table1 WHERE id BETWEEN 1 AND 11
ブロック
1
2
3
4 1 11 34 45
…
インデックス
テーブル
1
本当に値返していいの?
テーブルにアクセスしよう
46. 47. 48. 処理を補助する演算子
48
分類演算子
テーブルスキャンSeq Scan
Index Scan
Bitmap Scan
Index Only Scan
Tid Scan
その他スキャンFunction Scan
テーブルの結合Nested Loop
Merge Join
Hash Join
分類演算子
検索結果に対して
作用
limit
Unique
Aggregate
Group Aggregate
Result
結果の結合Append
SetOp
その他の処理を補
助
Sort
49. 49
Sort 演算子
=# EXPLAIN SELECT oid FROM pg_proc ORDER BY oid;
QUERY PLAN
---------------------------------------------
Sort (cost=181.55..185.92 rows=1747 width=4)
Sort Key: oid
-> Seq Scan on pg_proc
(cost=0.00..87.47 rows=1747 width=4)
• 明示的なソート: ORDER BY句
• 暗黙的なソート: Unique, Sort-Merge Join など
• 開始コストを持っている: 最初の値はすぐには返却
されない
50. 50
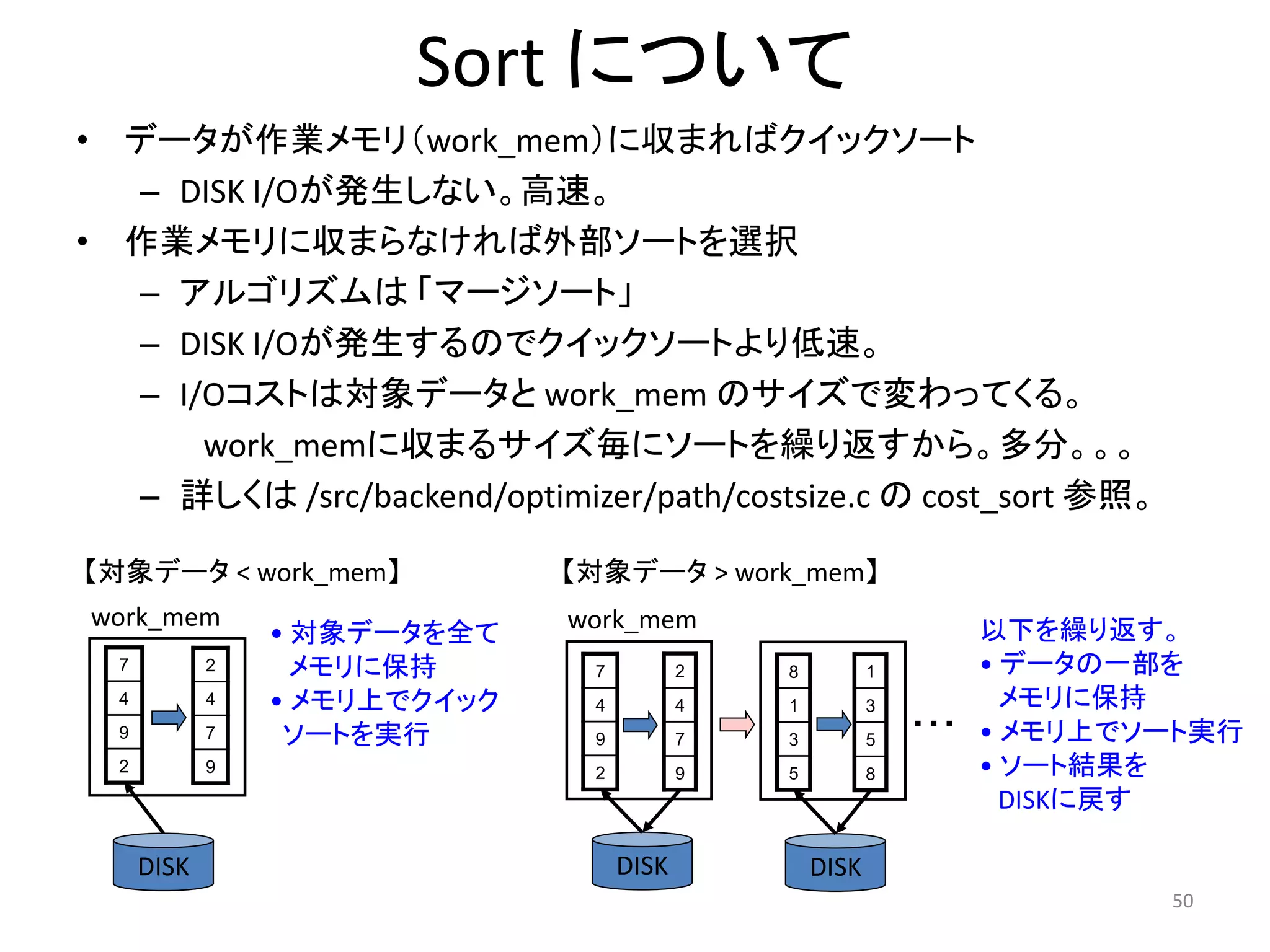
Sort について
• データが作業メモリ(work_mem)に収まればクイックソート
– DISK I/Oが発生しない。高速。
• 作業メモリに収まらなければ外部ソートを選択
– アルゴリズムは「マージソート」
– DISK I/Oが発生するのでクイックソートより低速。
– I/Oコストは対象データとwork_mem のサイズで変わってくる。
work_memに収まるサイズ毎にソートを繰り返すから。多分。。。
– 詳しくは/src/backend/optimizer/path/costsize.c のcost_sort 参照。
7
4
9
2
DISK
• 対象データを全て
メモリに保持
• メモリ上でクイック
ソートを実行
7
4
9
2
2
4
7
9
2
4
7
9
8
1
3
5
1
3
5
8
DISK DISK
・・・
【対象データ< work_mem】
work_mem
【対象データ> work_mem】
work_mem 以下を繰り返す。
• データの一部を
メモリに保持
• メモリ上でソート実行
• ソート結果を
DISKに戻す
51. 51
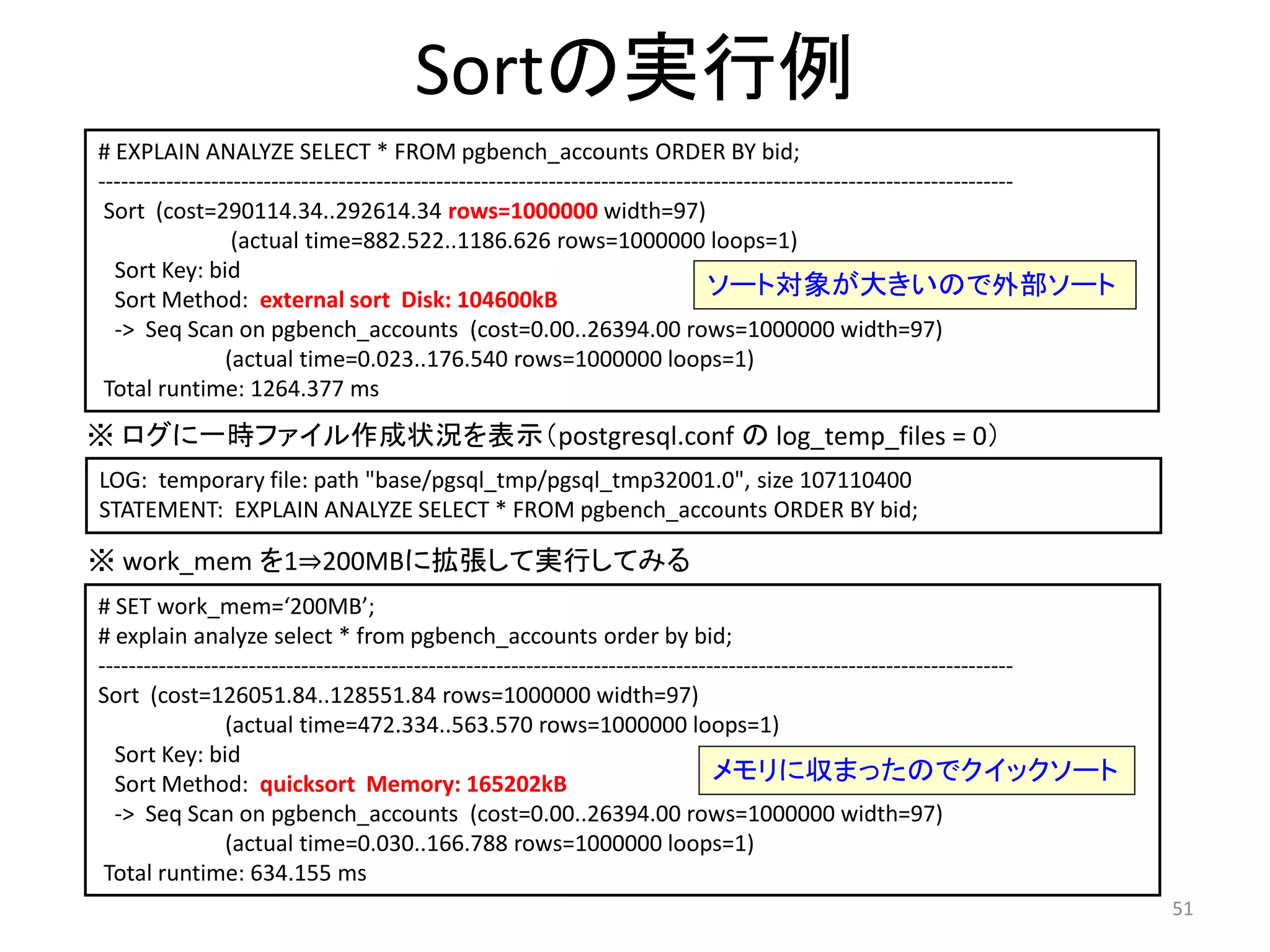
Sortの実行例
# EXPLAIN ANALYZE SELECT * FROM pgbench_accounts ORDER BY bid;
--------------------------------------------------------------------------------------------------------------------------
Sort (cost=290114.34..292614.34 rows=1000000 width=97)
(actual time=882.522..1186.626 rows=1000000 loops=1)
Sort Key: bid
Sort Method: external sort Disk: 104600kB
-> Seq Scan on pgbench_accounts (cost=0.00..26394.00 rows=1000000 width=97)
ソート対象が大きいので外部ソート
(actual time=0.023..176.540 rows=1000000 loops=1)
Total runtime: 1264.377 ms
※ ログに一時ファイル作成状況を表示(postgresql.conf のlog_temp_files = 0)
LOG: temporary file: path "base/pgsql_tmp/pgsql_tmp32001.0", size 107110400
STATEMENT: EXPLAIN ANALYZE SELECT * FROM pgbench_accounts ORDER BY bid;
※ work_mem を1⇒200MBに拡張して実行してみる
# SET work_mem=‘200MB’;
# explain analyze select * from pgbench_accounts order by bid;
--------------------------------------------------------------------------------------------------------------------------
Sort (cost=126051.84..128551.84 rows=1000000 width=97)
(actual time=472.334..563.570 rows=1000000 loops=1)
Sort Key: bid
Sort Method: quicksort Memory: 165202kB
-> Seq Scan on pgbench_accounts (cost=0.00..26394.00 rows=1000000 width=97)
メモリに収まったのでクイックソート
(actual time=0.030..166.788 rows=1000000 loops=1)
Total runtime: 634.155 ms
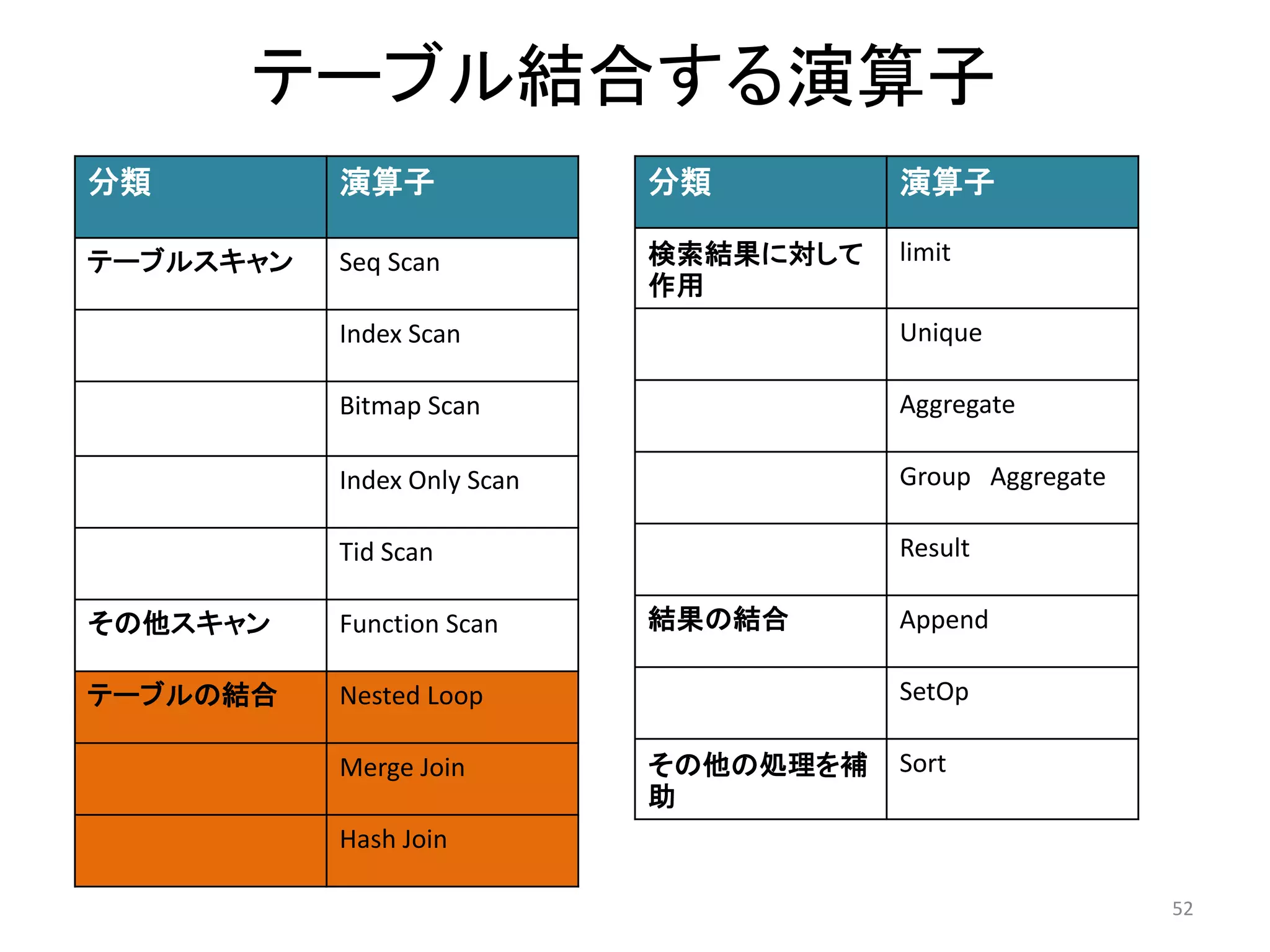
52. テーブル結合する演算子
52
分類演算子
テーブルスキャンSeq Scan
Index Scan
Bitmap Scan
Index Only Scan
Tid Scan
その他スキャンFunction Scan
テーブルの結合Nested Loop
Merge Join
Hash Join
分類演算子
検索結果に対して
作用
limit
Unique
Aggregate
Group Aggregate
Result
結果の結合Append
SetOp
その他の処理を補
助
Sort
53. 53
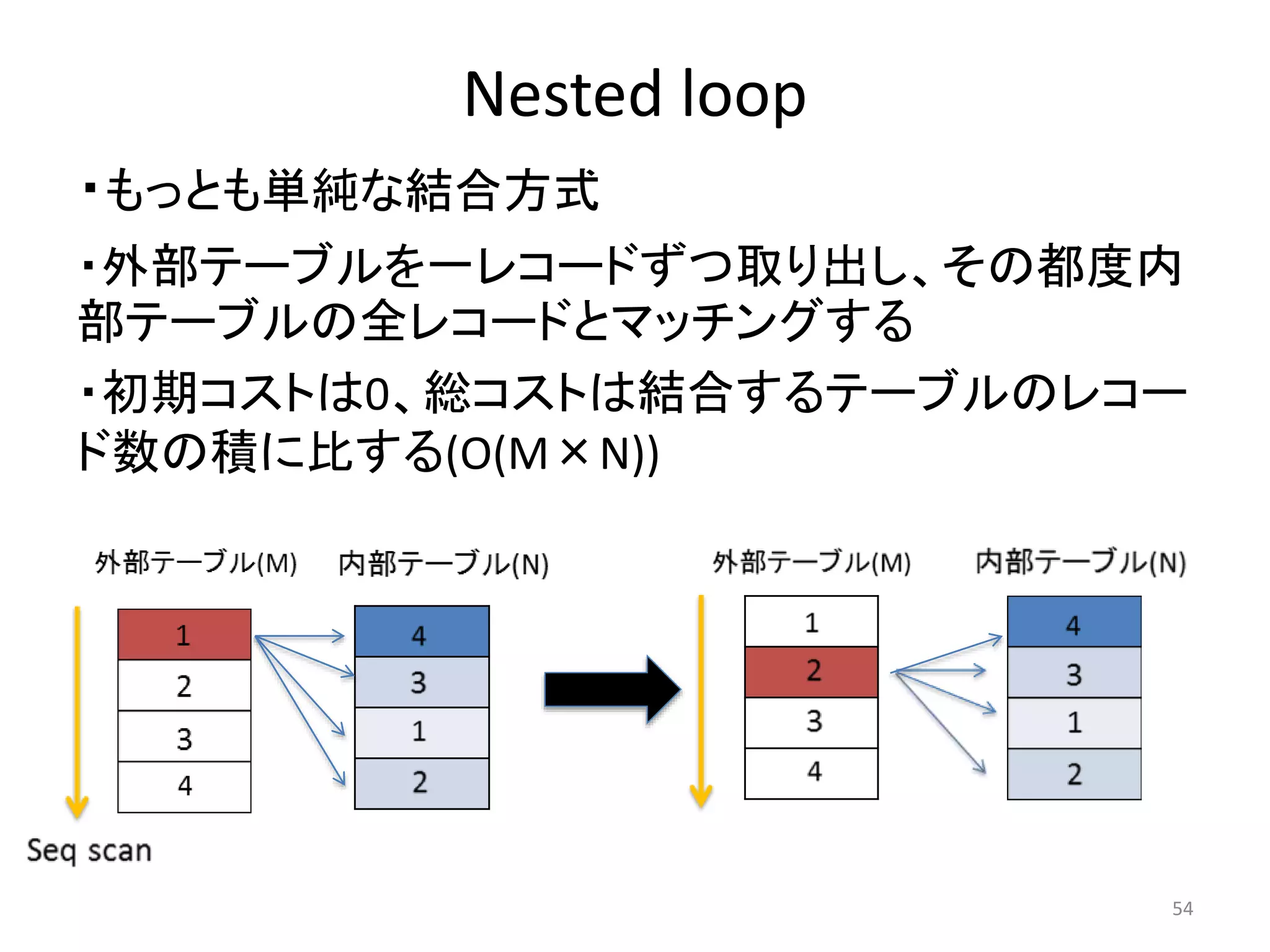
Nested Loop 演算子
=# EXPLAIN SELECT * FROM pgbench_accounts AS a,
pgbench_accounts AS b;
• 2つのテーブルの結合(2つの入力セット)
• INNER JOIN とLEFT OUTER JOIN の使用
• 「外部」テーブルをスキャンし、「内部」テーブルにマッチするものの発見
• 開始コスト無し
• インデックスが無い場合遅い問い合わせになる可能性、特にselect句に関
数がある場合
QUERY PLAN
---------------------------------------------------------------
Nested Loop
(cost=0.00..27637054248.00 rows=1000000000000 width=194)
-> Seq Scan on pgbench_accounts a
(cost=0.00..25874.00 rows=1000000 width=97)
-> Materialize (cost=0.00..46011.00 rows=1000000 width=97)
-> Seq Scan on pgbench_accounts b
(cost=0.00..25874.00 rows=1000000 width=97)
54. 55. Merge Join 演算子
# EXPLAIN SELECT * FROM pgbench_accounts AS a,
pgbench_tellers AS t where a.aid = t.tid;
QUERY PLAN
---------------------------------------------------------------
Merge Join (cost=5.94..11.25 rows=100 width=449)
Merge Cond: (a.aid = t.tid)
-> Index Scan using pgbench_accounts_pkey on pgbench_accounts a
(cost=0.42..39669.43 rows=1000000 width=97)
-> Sort (cost=5.32..5.57 rows=100 width=352)
Sort Key: t.tid
-> Seq Scan on pgbench_tellers t
(cost=0.00..2.00 rows=100 width=352)
• 二つのデータセットをJOINする:outerとinner
• Merge Right JoinとMerge In Joinがある
• データセットはあらかじめソートされていなければならず、また両方同
時に走査される。
55
56. 56
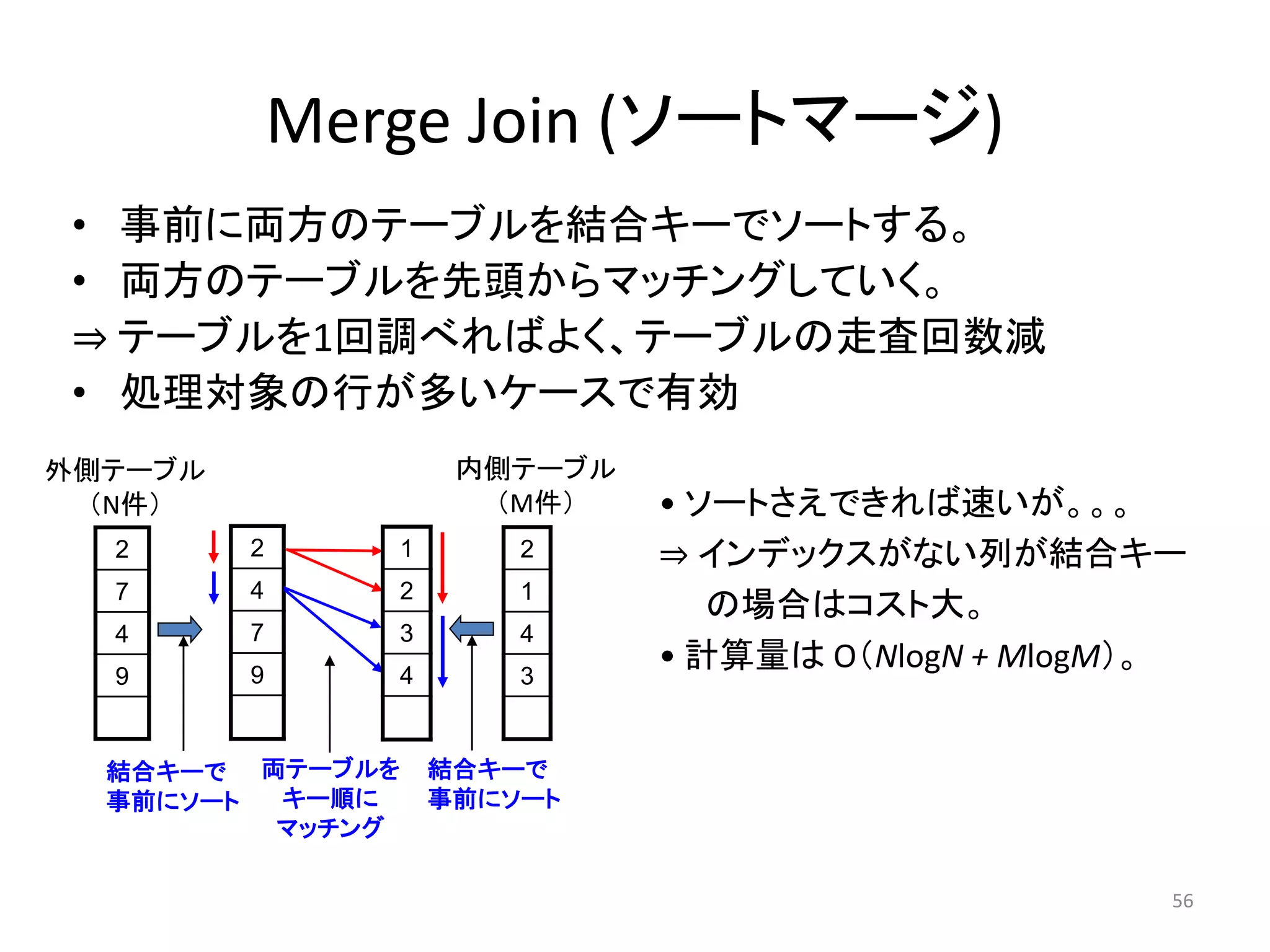
Merge Join (ソートマージ)
• 事前に両方のテーブルを結合キーでソートする。
• 両方のテーブルを先頭からマッチングしていく。
⇒ テーブルを1回調べればよく、テーブルの走査回数減
• 処理対象の行が多いケースで有効
2
4
7
9
2
7
4
9
2
1
4
3
外側テーブル
(N件)
内側テーブル
(M件)
結合キーで
事前にソート
1
2
3
4
両テーブルを
キー順に
マッチング
結合キーで
事前にソート
• ソートさえできれば速いが。。。
⇒ インデックスがない列が結合キー
の場合はコスト大。
• 計算量はO(NlogN + MlogM)。
57. 57
Hash & Hash Join 演算子
=# EXPLAIN SELECT * FROM pgbench_accounts AS a,
pgbench_tellers AS t where a.bid = t.bid;
QUERY PLAN
---------------------------------------------------------------
Hash Join (cost=3.25..140877.25 rows=10000000 width=449)
Hash Cond: (a.bid = t.bid)
-> Seq Scan on pgbench_accounts a
(cost=0.00..25874.00 rows=1000000 width=97)
-> Hash (cost=2.00..2.00 rows=100 width=352)
-> Seq Scan on pgbench_tellers t
(cost=0.00..2.00 rows=100 width=352)
• Hashは、異なるHash Join演算子で使用されるハッシュテーブルを作成
する
• 一方の入力からハッシュテーブルを作成し、二つの入力を比較する
• INNER JOIN、OUTER JOINと同時に使われる
• ハッシュの作成にはスタートアップコストが伴う
58. 58
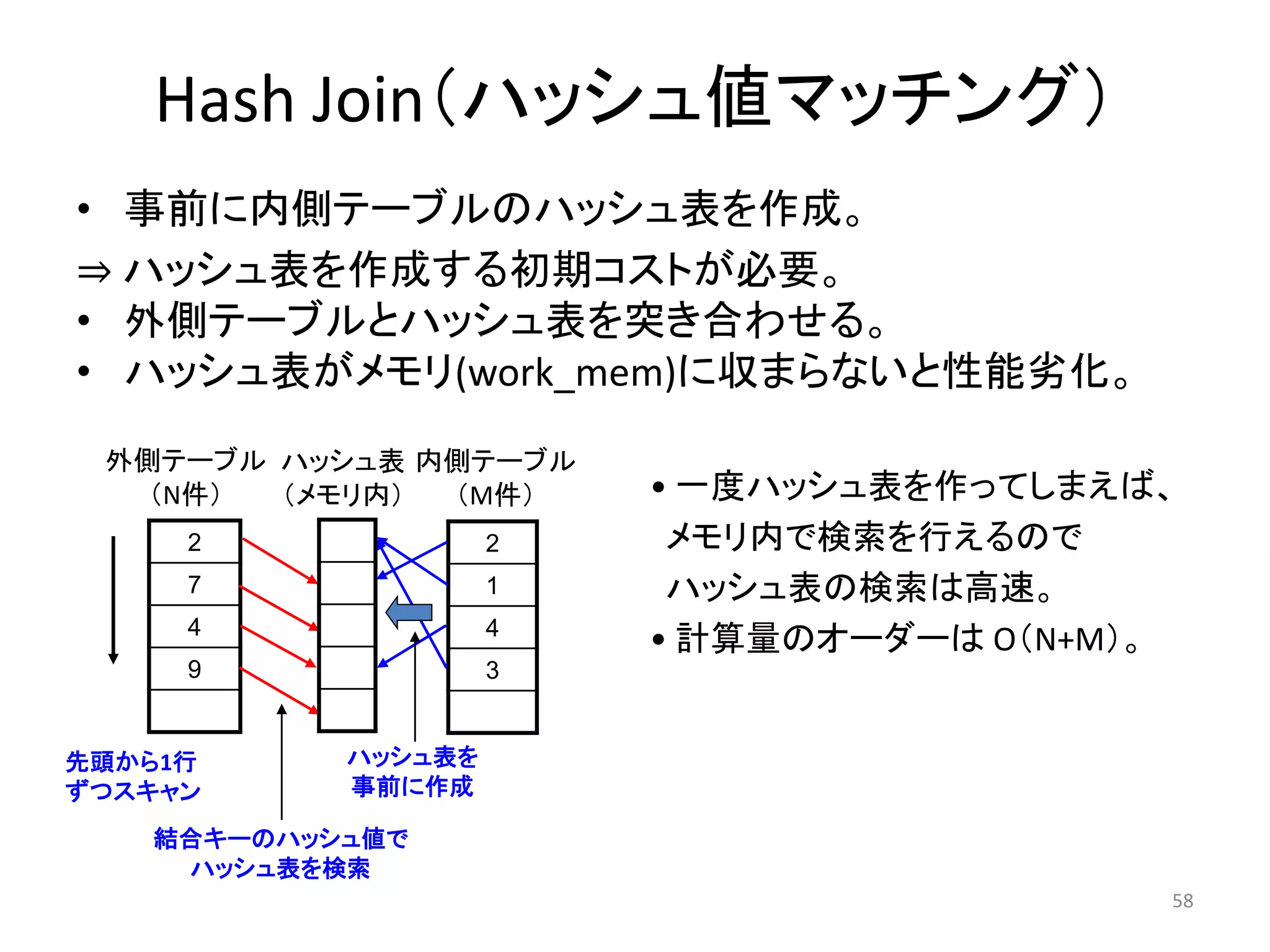
Hash Join(ハッシュ値マッチング)
• 事前に内側テーブルのハッシュ表を作成。
⇒ ハッシュ表を作成する初期コストが必要。
• 外側テーブルとハッシュ表を突き合わせる。
• ハッシュ表がメモリ(work_mem)に収まらないと性能劣化。
2
7
4
9
2
1
4
3
• 一度ハッシュ表を作ってしまえば、
メモリ内で検索を行えるので
ハッシュ表の検索は高速。
• 計算量のオーダーはO(N+M)。
外側テーブル
(N件)
内側テーブル
(M件)
ハッシュ表
(メモリ内)
ハッシュ表を
事前に作成
先頭から1行
ずつスキャン
結合キーのハッシュ値で
ハッシュ表を検索
59. JOINの比較
• Nested loop joinは、データが小さい場合に向
いている
• Merge joinは、データ量が多い場合に向いて
いる
• Hash joinは、ソートメモリーが十分にある場合
に向いている
59
60. 検索結果に対して作用する演算子
60
分類演算子
テーブルスキャンSeq Scan
Index Scan
Bitmap Scan
Index Only Scan
Tid Scan
その他スキャンFunction Scan
テーブルの結合Nested Loop
Merge Join
Hash Join
分類演算子
検索結果に対して
作用
limit
Unique
Aggregate
Group Aggregate
Result
結果の結合Append
SetOp
その他の処理を補
助
Sort
61. 61
Limit 演算子
=# EXPLAIN SELECT oid FROM pg_proc LIMIT 5;
QUERY PLAN
------------------------------------------
Limit (cost=0.00..0.25 rows=5 width=4)
-> Seq Scan on pg_proc
(cost=0.00..87.47 rows=1747 width=4)
• 行は指定された数に等しい
• 最初の行を即時に返す
• 少量の開始コスト追加でオフセットの扱いも可
=# EXPLAIN SELECT oid FROM pg_proc LIMIT 5 OFFSET 5;
QUERY PLAN
------------------------------------------
Limit (cost=0.25..0.50 rows=5 width=4)
-> Seq Scan on pg_proc
(cost=0.00..87.47 rows=1747 width=4)
62. 62
Unique 演算子
=# EXPLAIN SELECT distinct oid FROM pg_proc;
QUERY PLAN
--------------------------------------------------
Unique (cost=181.55..190.29 rows=1747 width=4)
-> Sort (cost=181.55..185.92 rows=1747 width=4)
Sort Key: oid
-> Seq Scan on pg_proc
(cost=0.00..87.47 rows=1747 width=4)
• 入力セットから重複する値を削除
• 行の並べ替えはせず、単に重複する行を取り除く
• 入力セットは予めソート済み(Sort演算子の後に行う)
• タプルコストごとに「CPU演算」×2
• DISTINCT とUNION で使用される
63. 64. =# EXPLAIN SELECT count(*) FROM pg_proc GROUP BY oid;
-----------------------------------------------------
GroupAggregate (cost=0.28..108.15 rows=2529 width=4)
64
GroupAggregate 演算子
QUERY PLAN
-> Index Only Scan using pg_proc_oid_index on
pg_proc (cost=0.28..70.22 rows=2529 width=4)
• GROUP BYを使用し、より大きな結果セット上に集
約を行う
65. 65
Result 演算子
=# EXPLAIN SELECT 1 + 1 ;
QUERY PLAN
------------------------------------------
Result (cost=0.00..0.01 rows=1 width=0)
• 非テーブル問い合わせ
• テーブルを参照せずに結果が得られる場合
66. 結果を結合する演算子
66
分類演算子
テーブルスキャンSeq Scan
Index Scan
Bitmap Scan
Index Only Scan
Tid Scan
その他スキャンFunction Scan
テーブルの結合Nested Loop
Merge Join
Hash Join
分類演算子
検索結果に対して
作用
limit
Unique
Aggregate
Group Aggregate
Result
結果の結合Append
SetOp
その他の処理を補
助
Sort
67. 67
Append 演算子
=# EXPLAIN SELECT oid FROM pg_proc
UNION ALL SELECT oid ORDER BY pg_proc;
QUERY PLAN
--------------------------------------------------------------
Append (cost=0.00..209.88 rows=3494 width=4)
-> Seq Scan on pg_proc (cost=0.00..87.47 rows=1747 width=4)
-> Seq Scan on pg_proc (cost=0.00..87.47 rows=1747 width=4)
• UNION (ALL) によるトリガー, 継承
• 開始コスト無し
• コストは単に全ての入力の合計
68. =# EXPLAIN SELECT oid FROM pg_proc INTERSECT SELECT oid FROM pg_proc;
-----------------------------------------------------------------------
SetOp Intersect (cost=415.51..432.98 rows=349 width=4)
-> Subquery Scan "*SELECT* 1" (cost=0.00..104.94 rows=1747)
-> Subquery Scan "*SELECT* 2" (cost=0.00..104.94 rows=1747)
68
SetOp 演算子
QUERY PLAN
-> Sort (cost=415.51..424.25 rows=3494 width=4)
Sort Key: oid
-> Append (cost=0.00..209.88 rows=3494 width=4)
-> Seq Scan on pg_proc (cost=0.00..87.47 rows=1747)
-> Seq Scan on pg_proc (cost=0.00..87.47 rows=1747)
• INTERSECT, INTERSECT ALL, EXCEPT, EXCEPT ALL句
のために使用される
– SetOp Intersect, Intersect All, Except, Except All
69. Explainの演算子はこれら以外にも、
• SubqueryScan
• Material
:
などなどがあります。
そしてこれら演算子は、作業領域やインデックスの
有無など様々な条件によって選択されます。
→実行計画内でなぜその演算子が選ばれたのか、
どのような実行計画なのか中身を読み解くために
も、DBやインスタンスの状態には気をつけましょう。
69
70. 71. 参考文献
• PostgreSQL全機能バイブル
鈴木啓修・著
• Explaining Explain ~ PostgreSQLの実行計画を読む~
by Robert Treat(翻訳:日本PostgreSQLユーザ会)
• Explaining EXPLAIN 第2回
第20回しくみ+アプリケーション勉強会中西さん
• Explaining Explain 第3回
第21回しくみ+アプリケーション勉強会田中さん
• Let’s PostgreSQL
http://lets.postgresql.jp/
• PostgreSQL wiki
http://wiki.postgresql.org/wiki/Main_Page
• 問合わせ最適化インサイド
NTT オープンソースソフトウェアセンタ板垣さん
71
72.













![一般的なデータ型のサイズについて
25
Explaining → Widths
=# EXPLAIN SELECT oid FROM pg_proc;
QUERY PLAN
------------------------------------------
Seq Scan on pg_proc
(cost=0.00..87.47 rows=1747 width=4)
• このレベルにおける推定さ
れた入力サイズを表示する。
• それほど重要ではない
smallint 2
integer 4
bigint 8
boolean 1
char(n) n+1
~
n+4
varchar(n)
text [ n文字]](https://image.slidesharecdn.com/drkiwmutqwkhyzgsln8k-signature-8f6560a76e23c30602613eb6643805fa05ffeddba8ca5b06a833f45a0af46e33-poli-141207201956-conversion-gate02/75/SQL-25-2048.jpg)