Download as PDF, PPTX




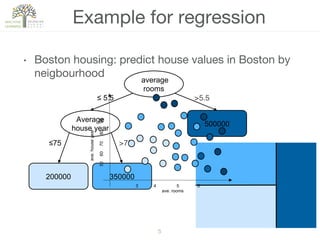






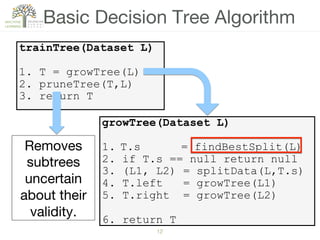
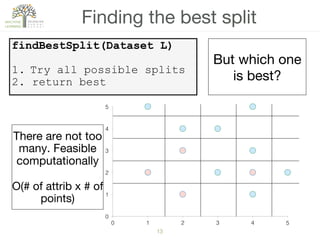




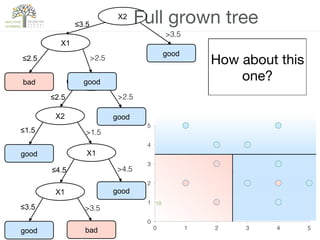



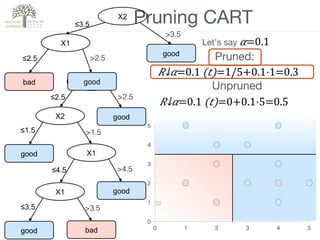




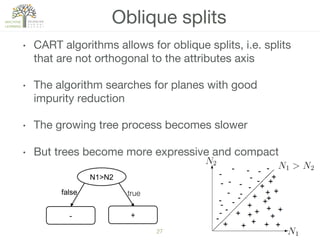

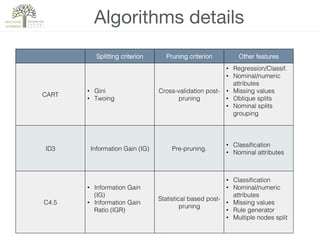





The document discusses decision trees, a hierarchical learning model used for classification and regression by recursively partitioning data based on decision rules. It covers their historical development, algorithms for growing and pruning trees, criteria for making splits, and advantages and disadvantages of decision trees in machine learning. Key algorithms mentioned include CART, C4.5, and ID3, which vary in terms of handling issues like overfitting and missing values.














































































![[DSC Europe 25] Dragan Jerosimovic - The Anatomy of a Narrative Simulation.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/vzputuprdqr6zwbrwdcw-1-dragan-jerosimovic-the-anatomy-of-a-narrative-simulation-260114111931-9d04fba2-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DSC Europe 25] Srba Markovic - From Pilot to Production: Overcoming AI Deplo...](https://cdn.slidesharecdn.com/ss_thumbnails/yjjmrtytmwbalxlba7px-4-srba-markovic-from-pilot-to-production-overcoming-ai-deployment-blockers-with-260114111931-4a892d44-thumbnail.jpg?width=640&height=640&fit=bounds)





