Downloaded 120 times


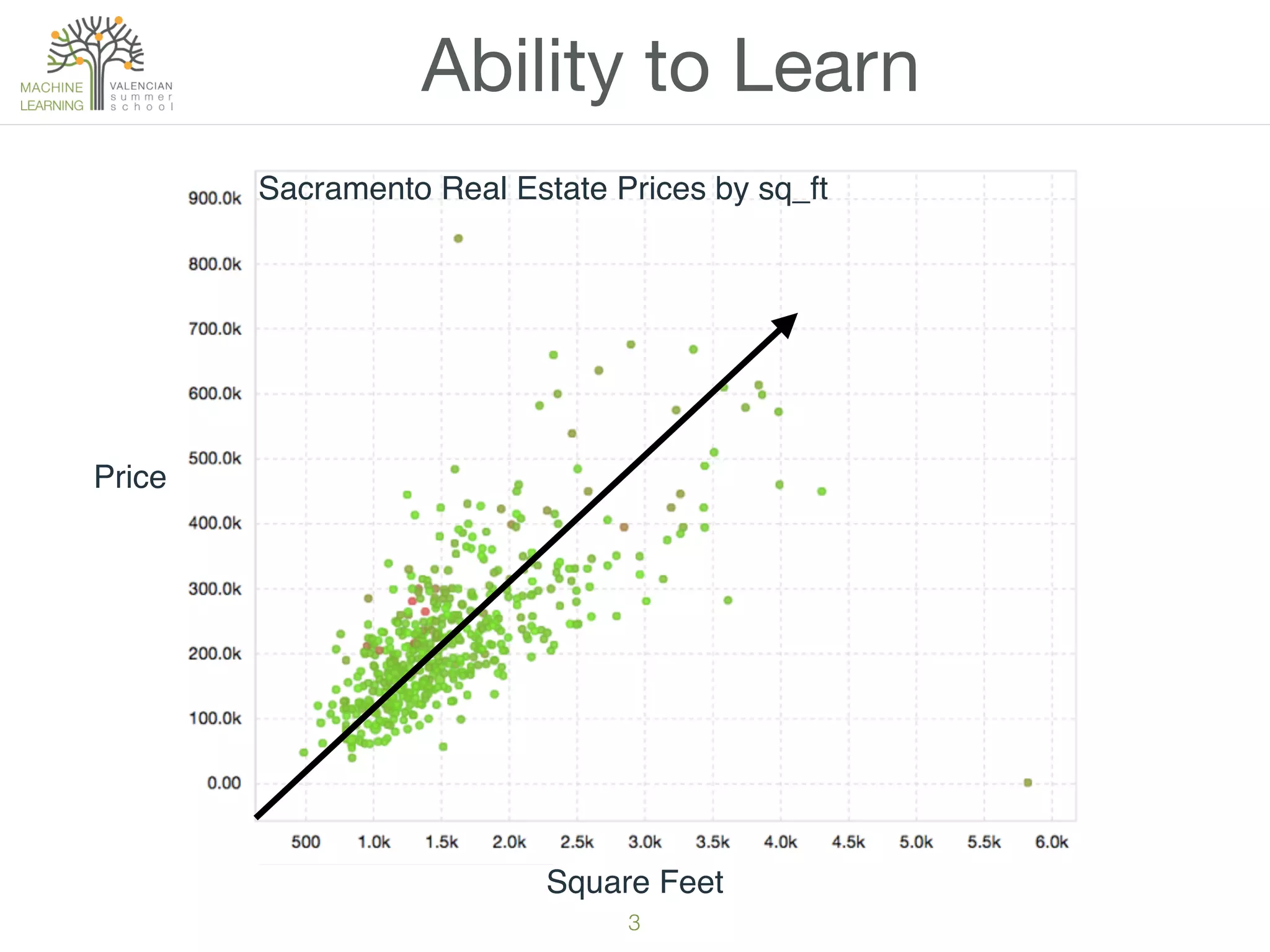

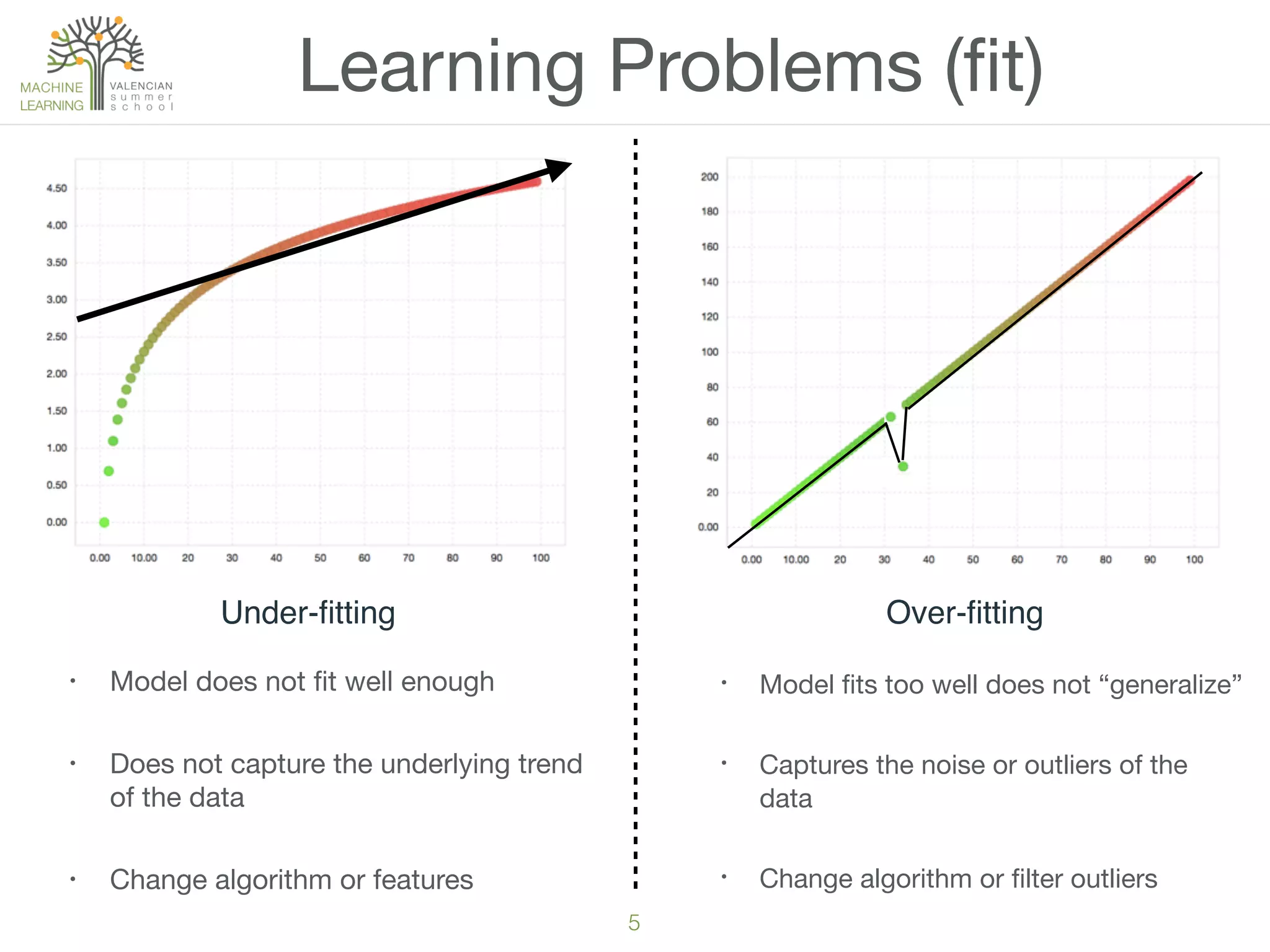




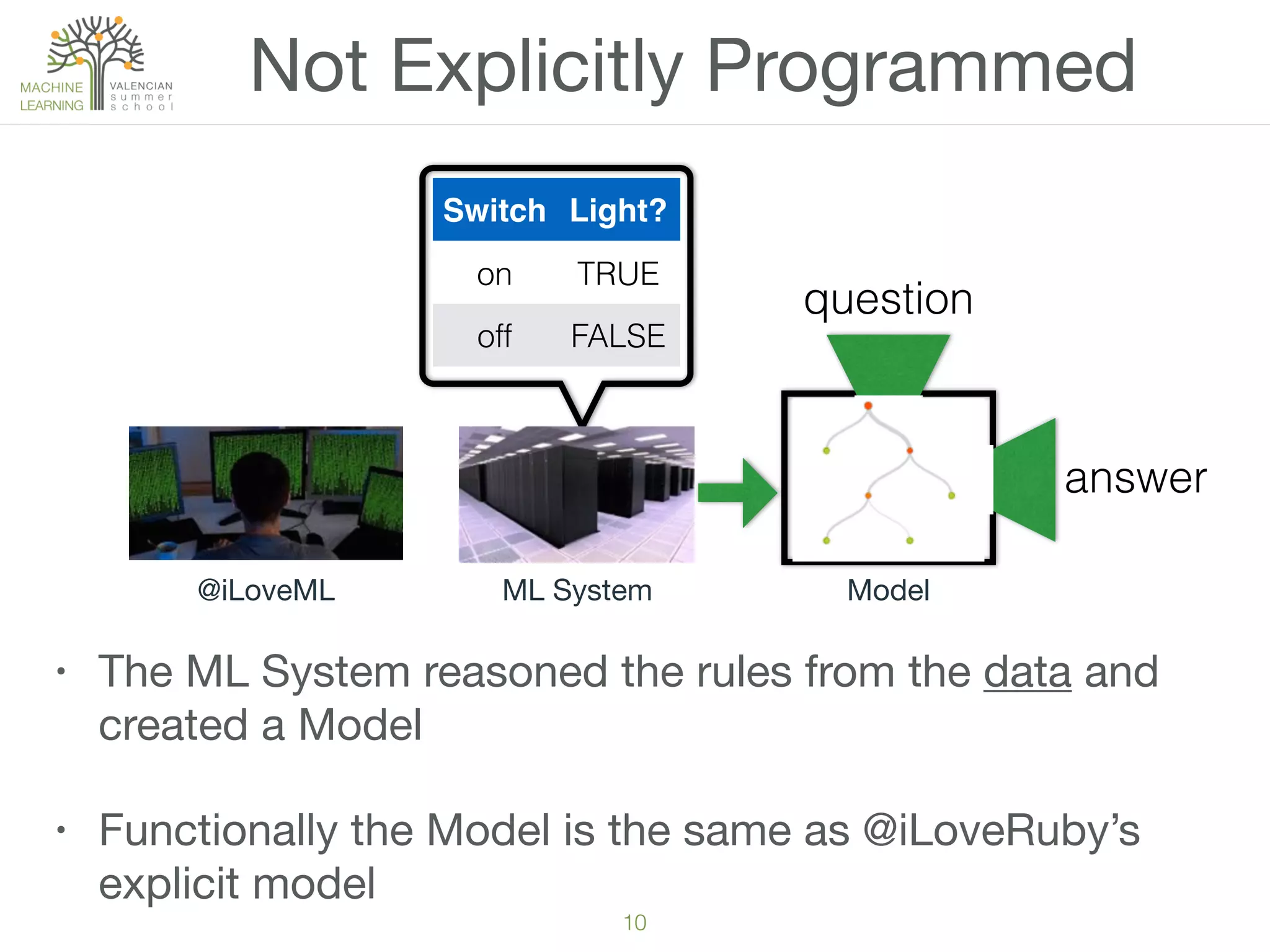

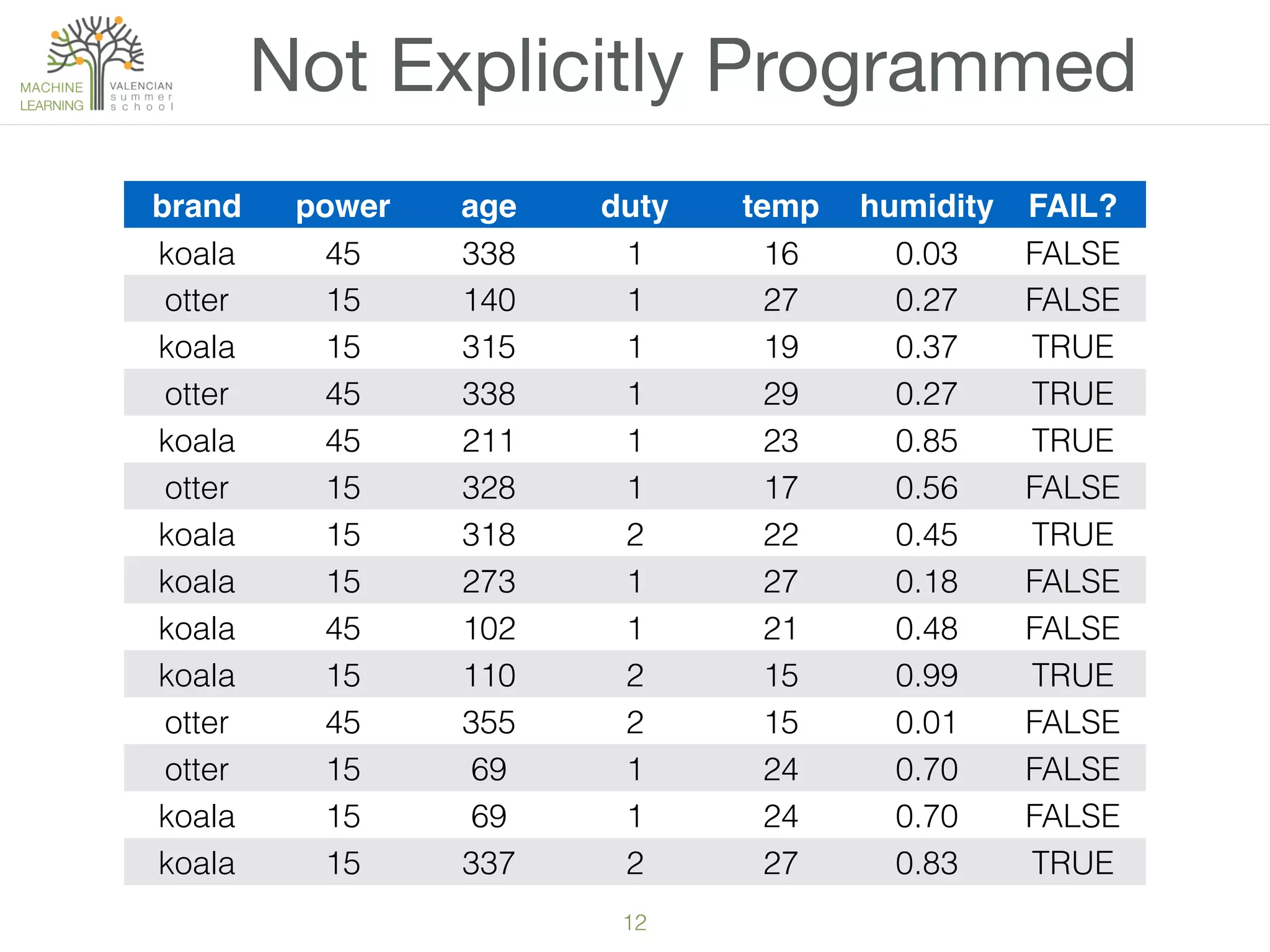

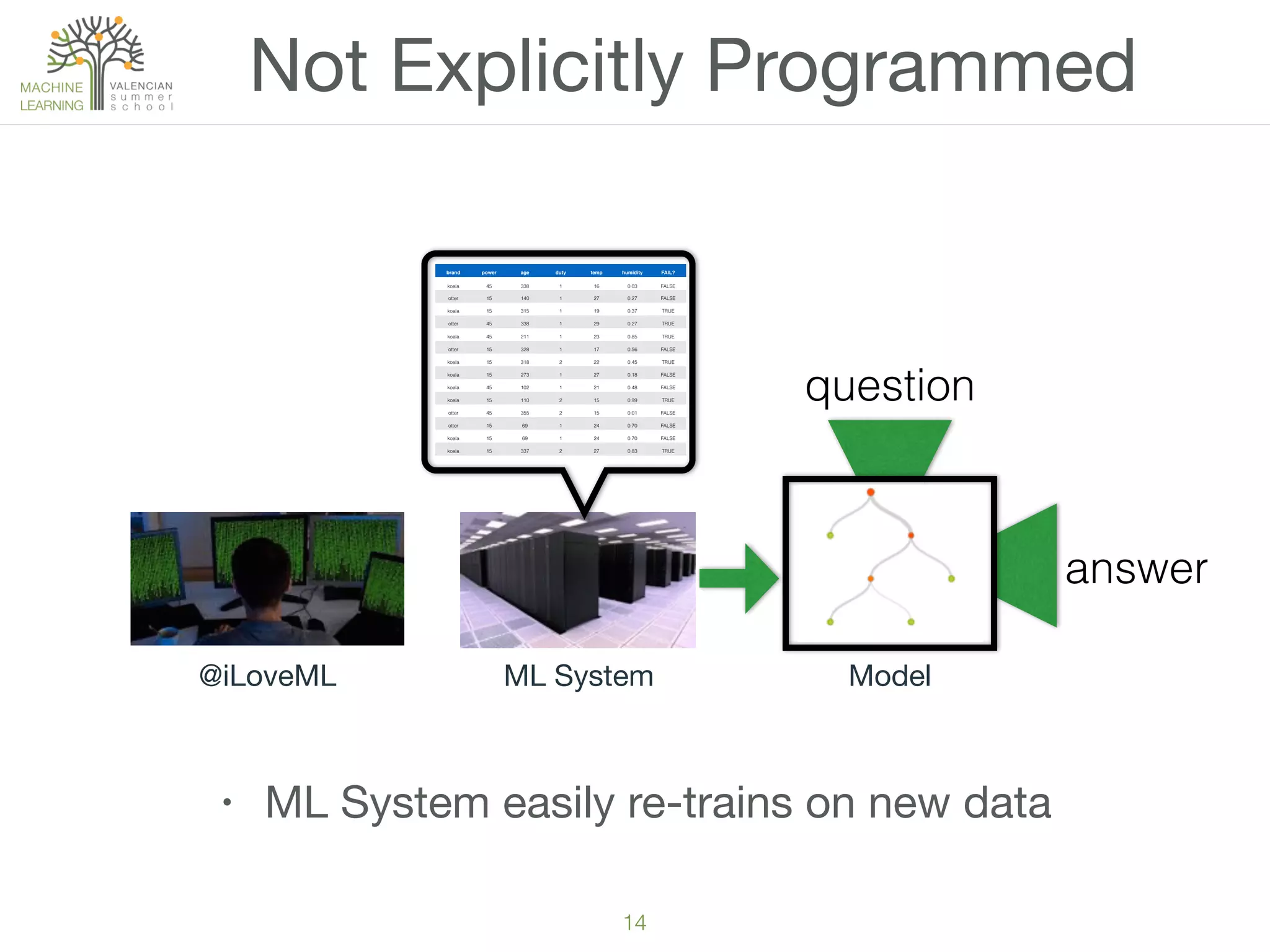
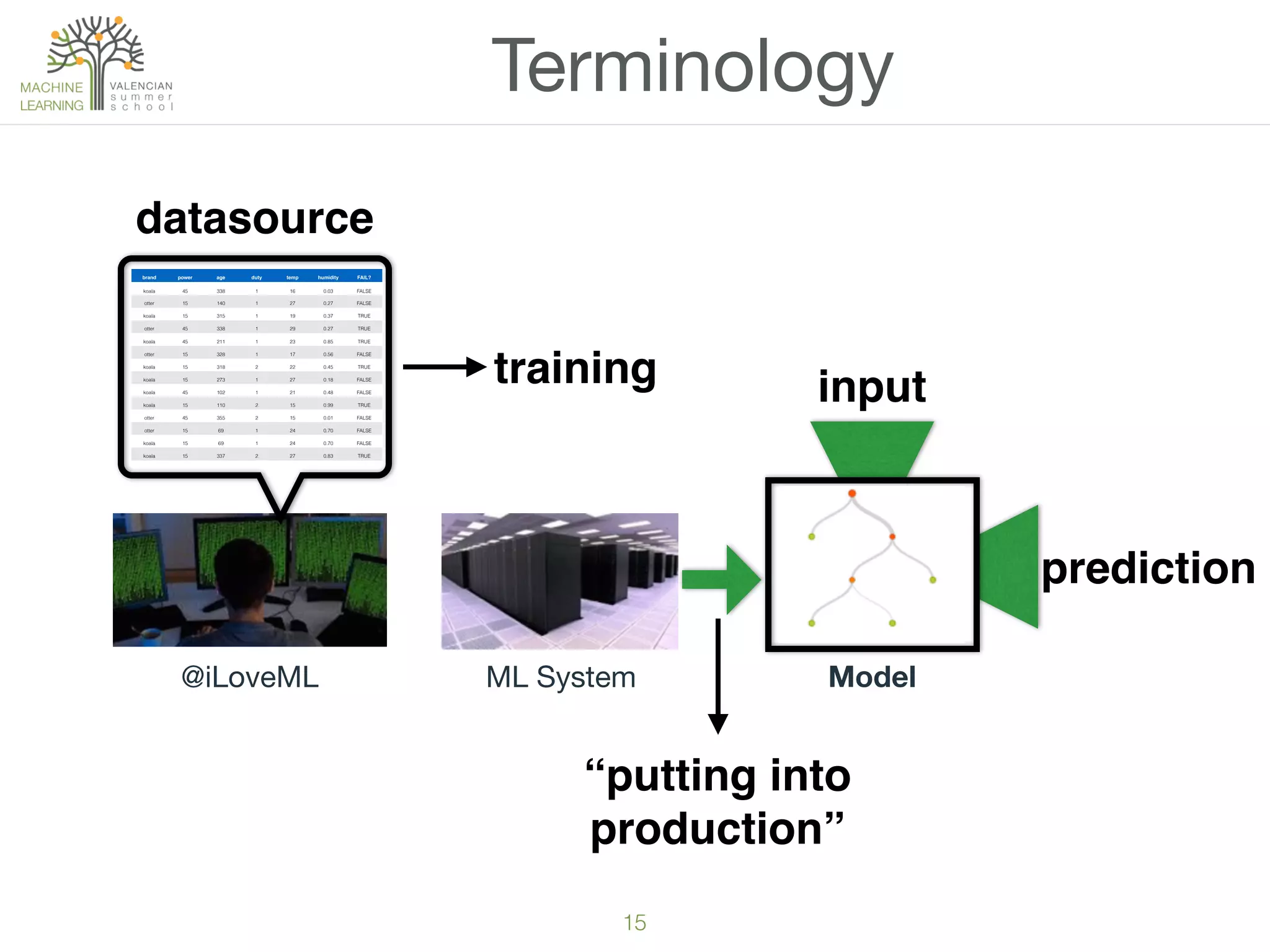
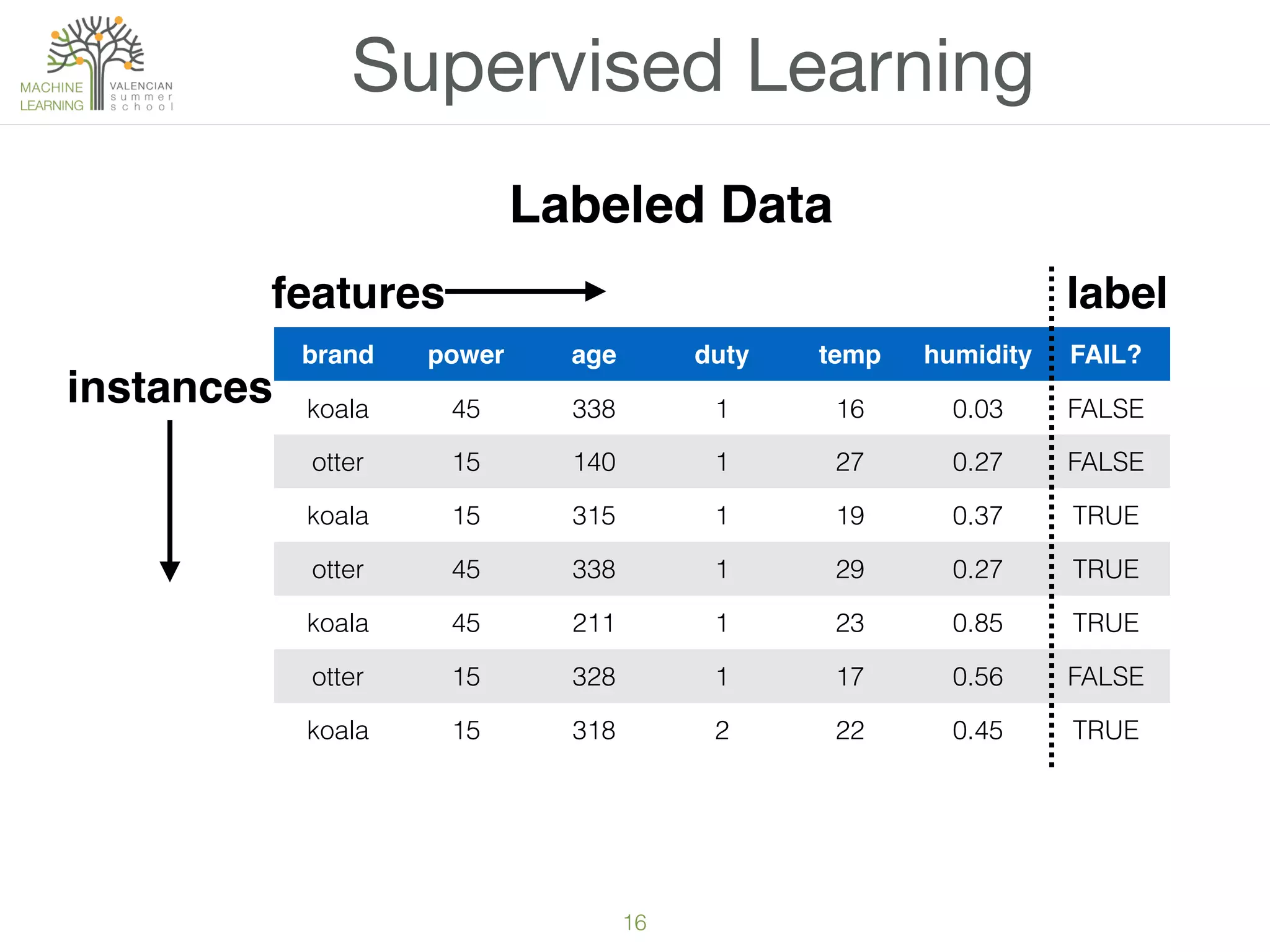
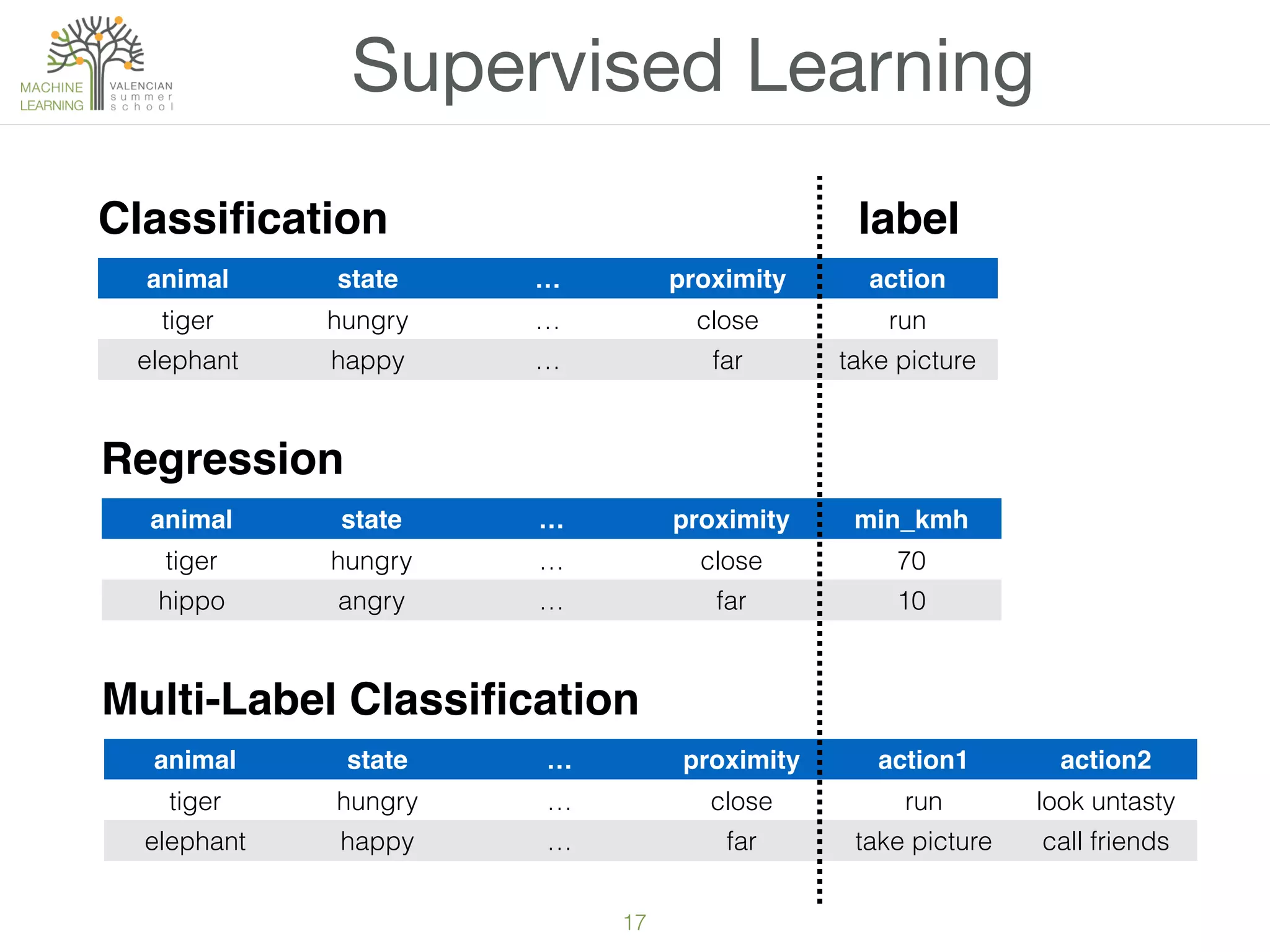
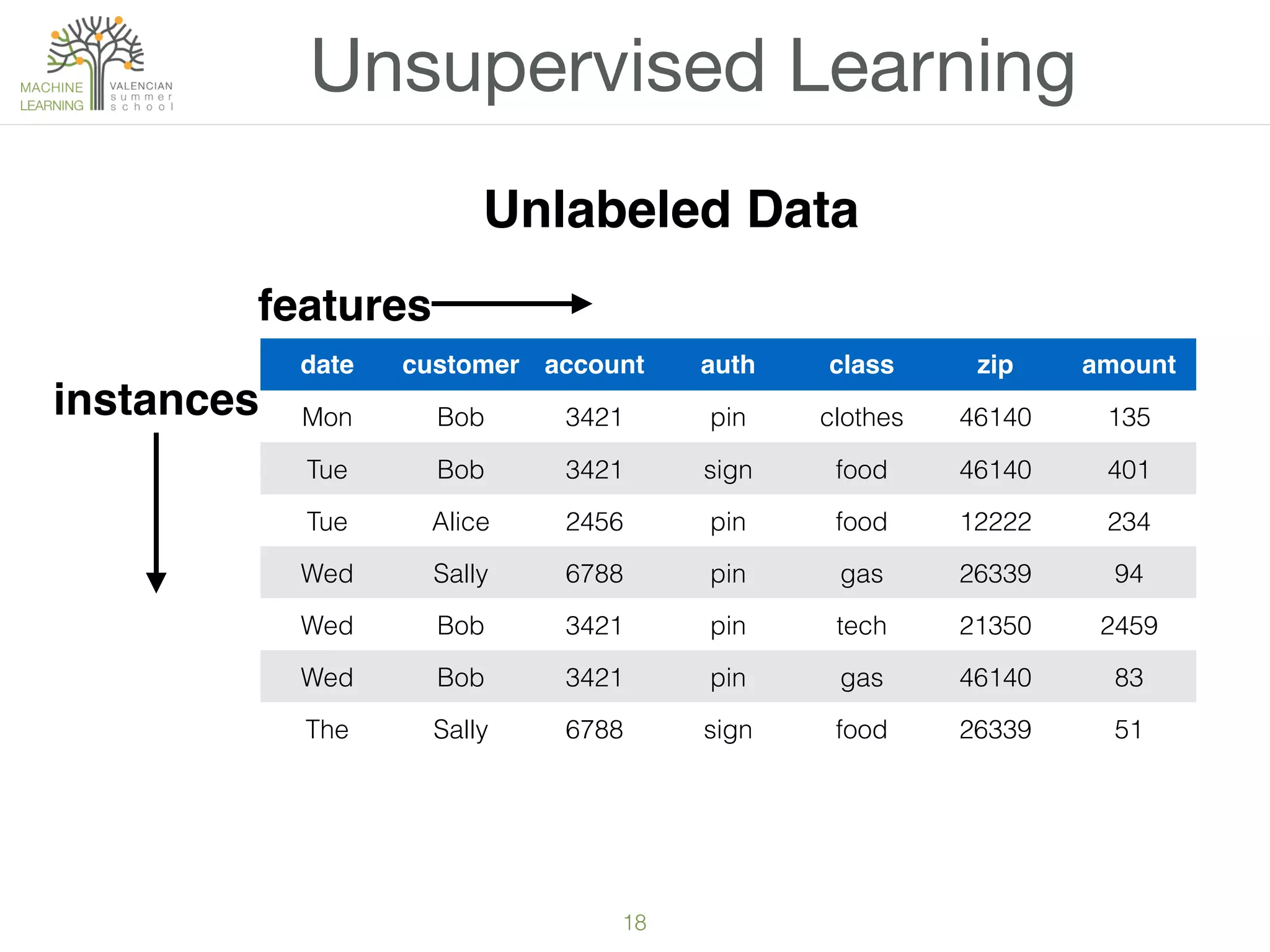
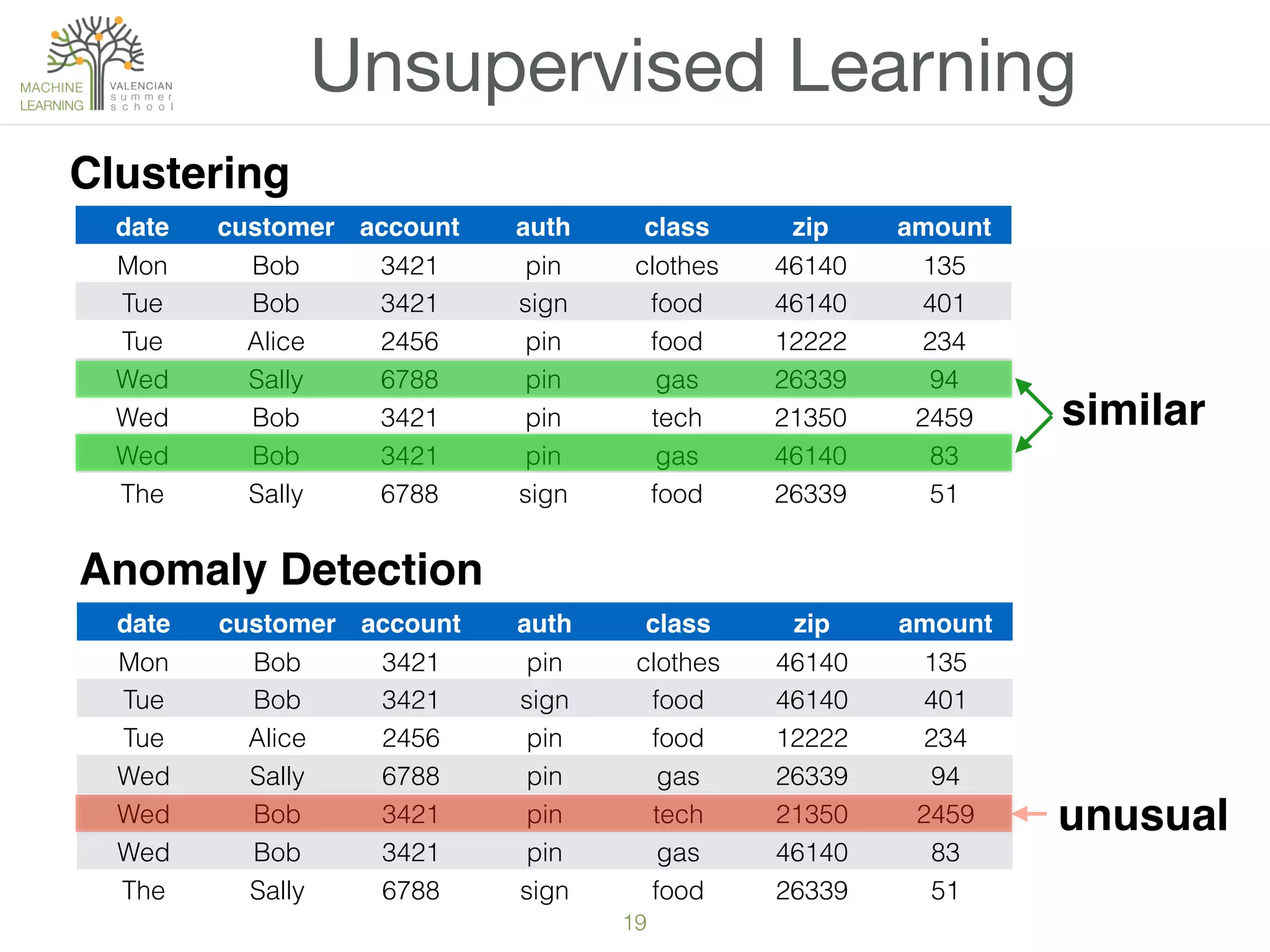
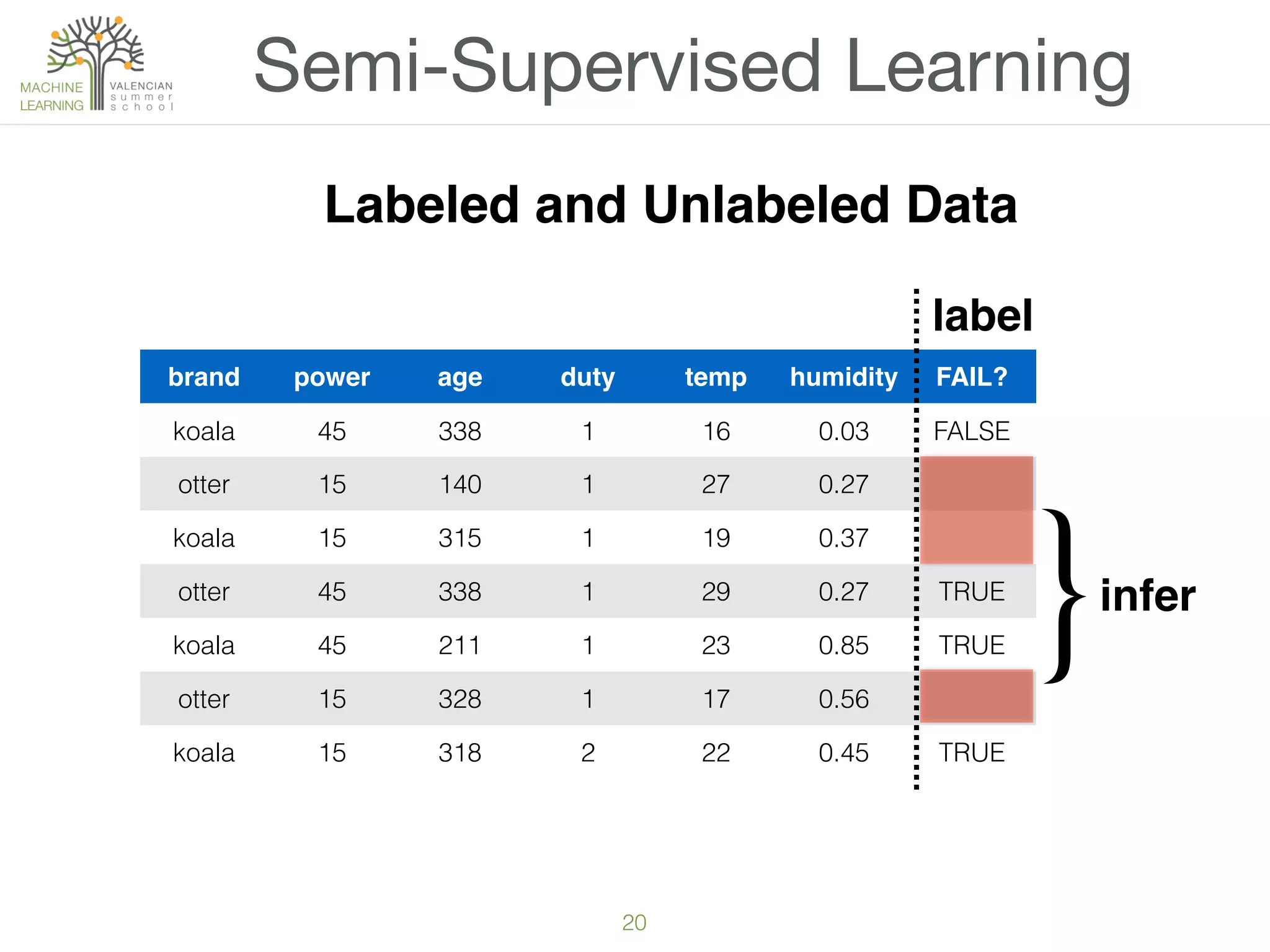
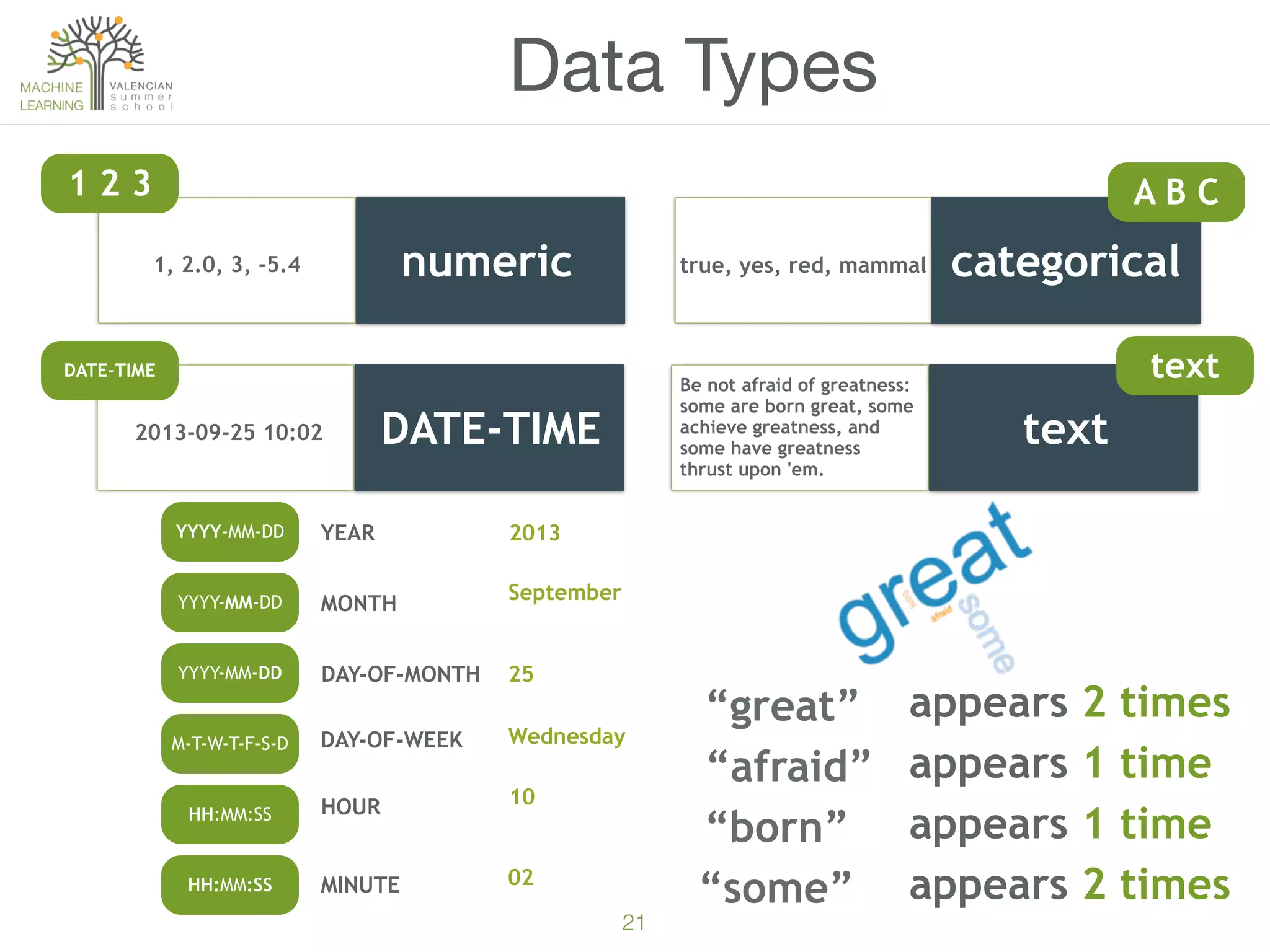


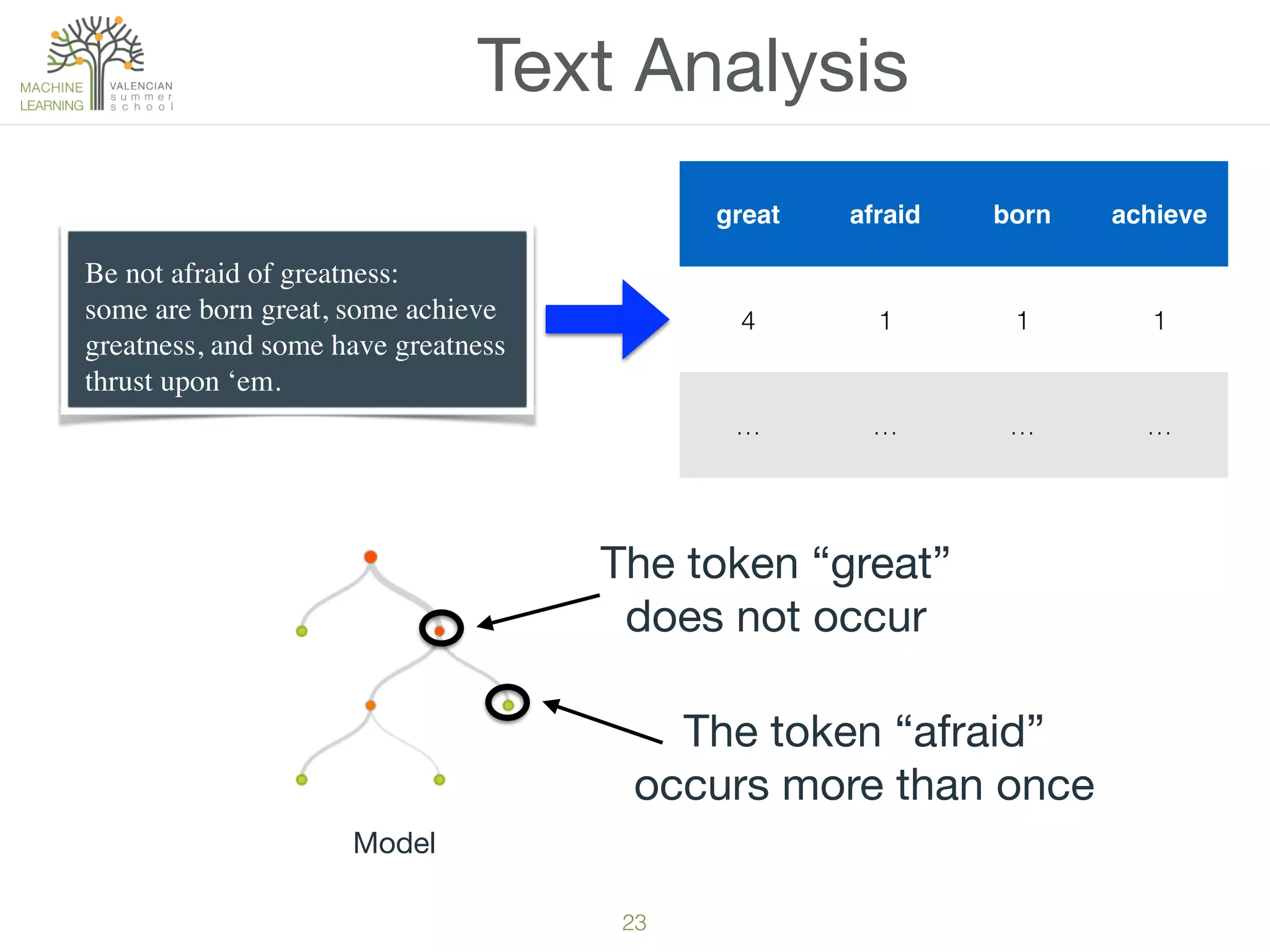

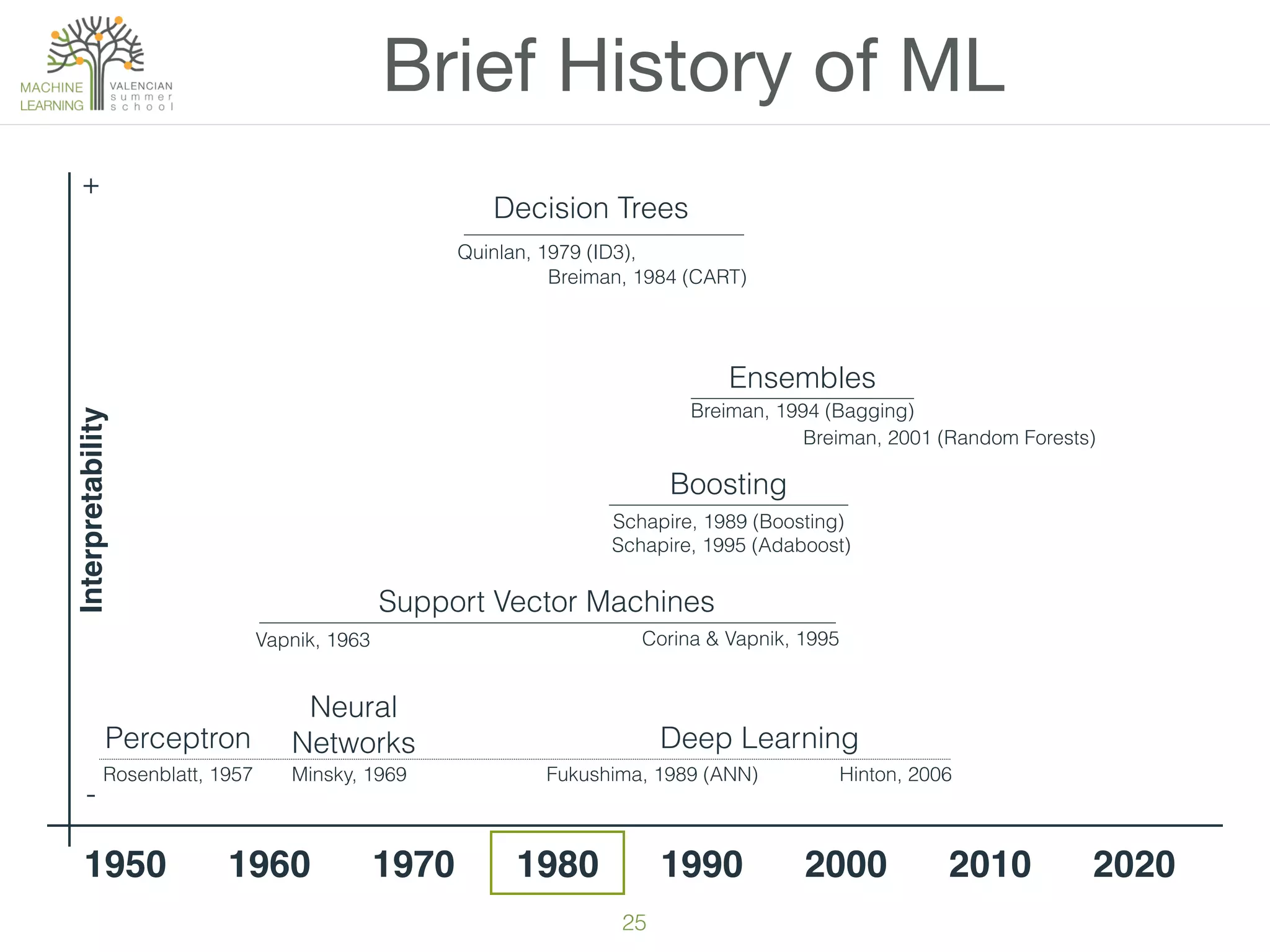

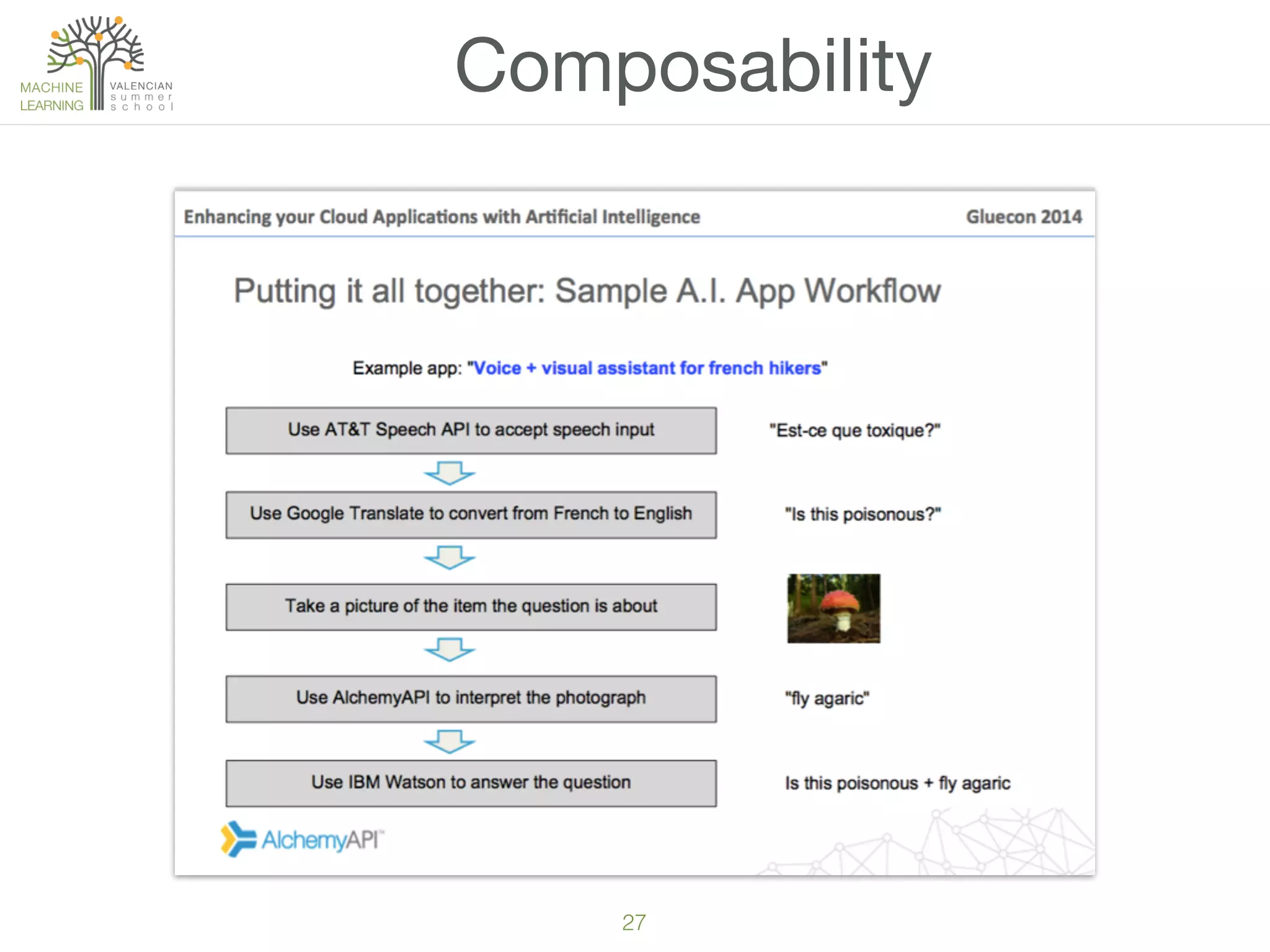
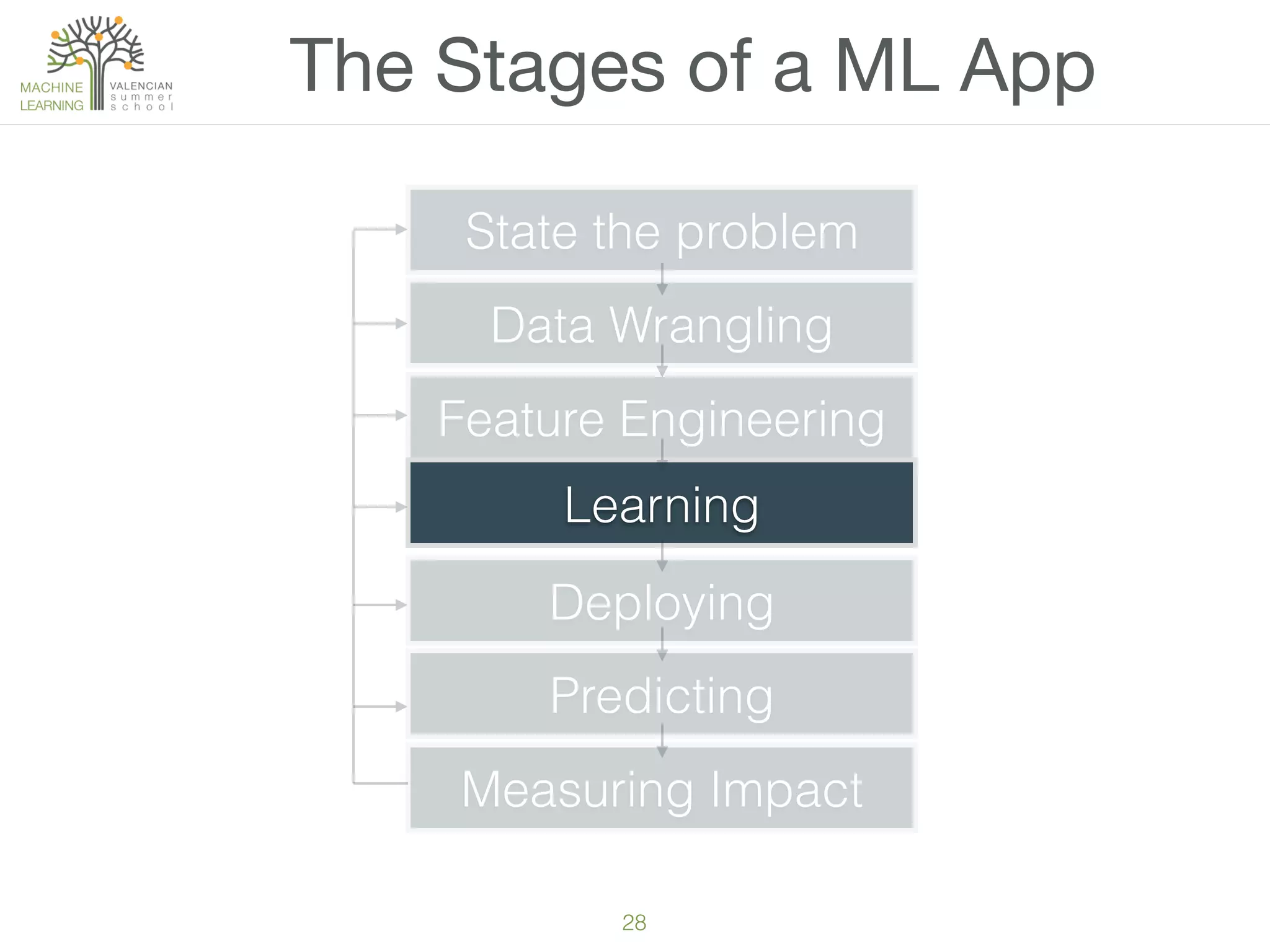

The document provides an overview of machine learning (ML), defining it as a field enabling computers to learn from data without explicit programming. It discusses the types of learning problems such as underfitting and overfitting, various ML models, and the significance of data management, including handling missing values. Additionally, it traces the evolution of ML techniques from the 1950s to present, highlighting the reasons for its current prominence and outlining the stages involved in developing an ML application.





![[EN]DSS23_tspann_Integrating LLM with Streaming Data Pipelines](https://cdn.slidesharecdn.com/ss_thumbnails/endss23tspannintegratingllmwithstreamingdatapipelines-231115161007-49510320-thumbnail.jpg?width=640&height=640&fit=bounds)







![[BEDROCK] Claude Prompt Engineering Techniques.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/bedrockclaudepromptengineeringtechniques-231213183236-1d873607-thumbnail.jpg?width=640&height=640&fit=bounds)


![[系列活動] 手把手的深度學習實務](https://cdn.slidesharecdn.com/ss_thumbnails/slidesharestepbystepdl-161213072731-thumbnail.jpg?width=640&height=640&fit=bounds)



































































![[DSC Europe 25] Dobrica Cosic - Savings by the Second: How Dynamic Pricing an...](https://cdn.slidesharecdn.com/ss_thumbnails/znp09f3smtqz3w2sq6wn-1-dobrica-cosic-savings-by-the-second-how-dynamic-pricing-and-smart-data-are-bu-251208151905-26e6f41e-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jovan Bogicevic - Legacy to AI-Driven Defense: Transforming D...](https://cdn.slidesharecdn.com/ss_thumbnails/rsarluadt563hntyfc8q-3-251211083849-3e7bc4c0-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jon Dajci - Bridging TradFi and DeFi: Building the Future of ...](https://cdn.slidesharecdn.com/ss_thumbnails/fqmhfvlbqhkihjvqvhmu-7-251211083849-6af7e325-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Milan Sekuloski - Data, Defence, and Development: Cybersecuri...](https://cdn.slidesharecdn.com/ss_thumbnails/dfrkwwx4qly6atqpbl4z-4-251209104645-c3d4b0ca-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Bassam Maharmeh - Artificial Intelligence: Opportunities and ...](https://cdn.slidesharecdn.com/ss_thumbnails/thhfmr2fqpawzj7hsjpg-5-251211083048-2c23204f-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Branko Urosevic -Rethinking Financial Talent: Integrating Cod...](https://cdn.slidesharecdn.com/ss_thumbnails/8jjrus8ttko6qj64f58f-3-251212103250-642c6374-thumbnail.jpg?width=640&height=640&fit=bounds)
