Downloaded 62 times





![IMPORTING DATASET
dataset = pd.read_csv('Social_Network_Ads.csv')
X = dataset.iloc[:,2:4]
y= dataset.iloc[:,-1]](https://image.slidesharecdn.com/13-knnclassification-171230051750/75/knn-classification-7-2048.jpg)










![READ DATASET
library(readr)
dataset <- read_csv("D:/machine learning AZ/Machine Learning A-Z
Template Folder/Part 3 - Classification/Section 14 - Logistic
Regression/Logistic_Regression/Social_Network_Ads.csv")
dataset = dataset[3:5]](https://image.slidesharecdn.com/13-knnclassification-171230051750/75/knn-classification-18-2048.jpg)


![FEATURE SCALING
training_set[-3] = scale(training_set[-3])
test_set[-3] = scale(test_set[-3])](https://image.slidesharecdn.com/13-knnclassification-171230051750/75/knn-classification-21-2048.jpg)
![FITTING K-NN TO THE TRAINING SET &
PREDICTION
library(class)
y_pred = knn(train = training_set[, c(1,2)],
test = test_set[, c(1,2)],
cl = training_set$Purchased,
k = 5,
prob = TRUE)](https://image.slidesharecdn.com/13-knnclassification-171230051750/75/knn-classification-22-2048.jpg)
![CONFUSION MATRIX
cm = table(test_set[, 3], y_pred)](https://image.slidesharecdn.com/13-knnclassification-171230051750/75/knn-classification-23-2048.jpg)

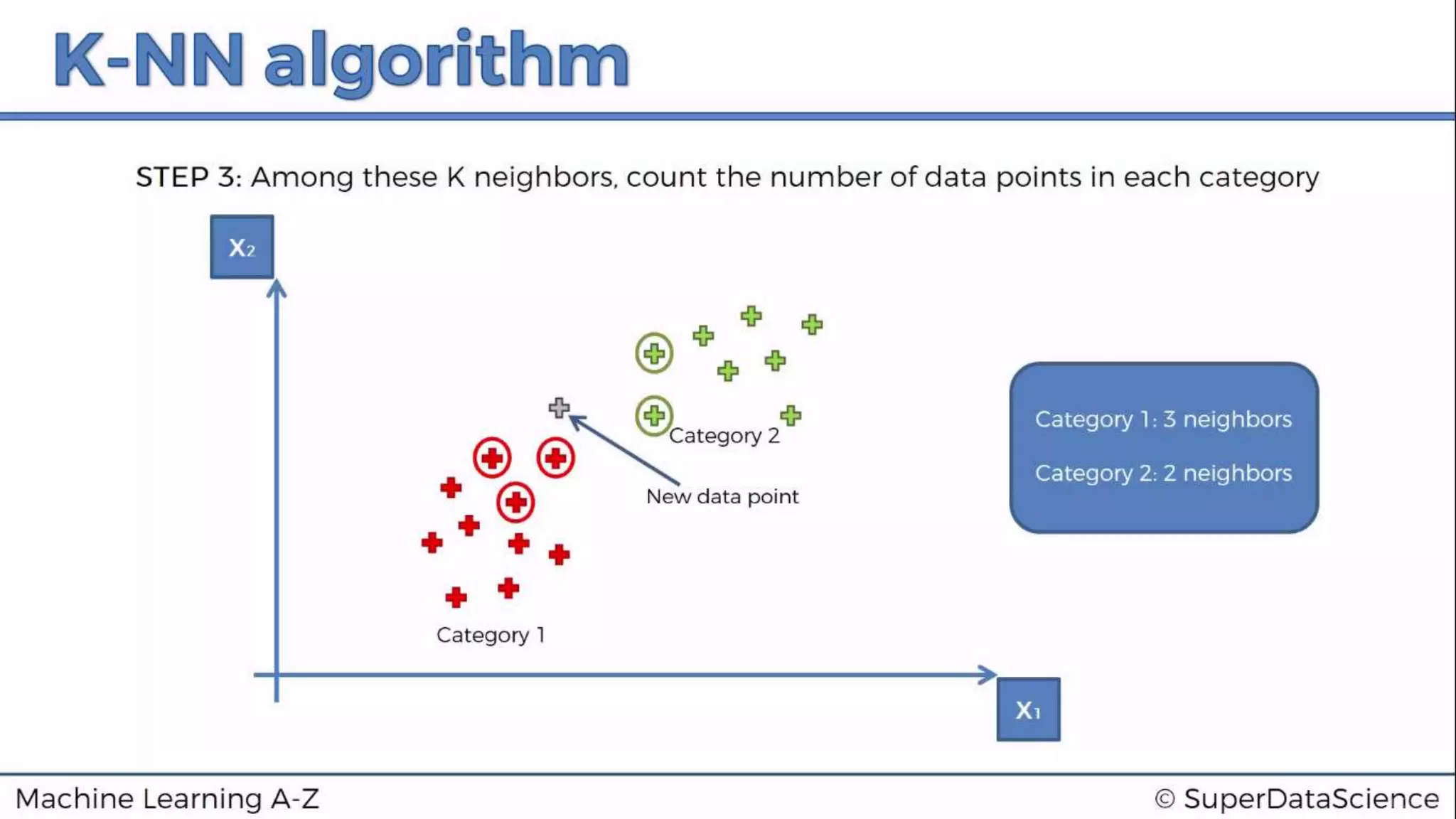
This document discusses K-nearest neighbors (K-NN) classification using Python and R. It covers reading and preprocessing a dataset, splitting it into training and test sets, feature scaling, fitting a K-NN classifier to the training set, making predictions on the test set, and evaluating performance using metrics like confusion matrix and classification report. The key steps are importing libraries, preprocessing the data, training a K-NN classifier, predicting on new data, and evaluating results.




































































![[DSC Europe 25] Miodrag Pesovic & Vladislav Radonjic - Federated Data Archite...](https://cdn.slidesharecdn.com/ss_thumbnails/gsbe3y5it5uhndi4e08e-1-251212103249-f1008e0c-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Marko Krstic - Understanding the AI Threat Landscape - Risks,...](https://cdn.slidesharecdn.com/ss_thumbnails/tiyim1ins5jvbrvzpzla-2-251209104645-c69d3553-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Nikolay Burlutskiy - Best Practices for Building Enterprise M...](https://cdn.slidesharecdn.com/ss_thumbnails/uirvaiuvq8y1w8hzd9tx-7-251212103249-2619edb4-thumbnail.jpg?width=640&height=640&fit=bounds)