Downloaded 392 times
































![c|c
(TM)
(TM)
37
calculation | consulting capsule networks
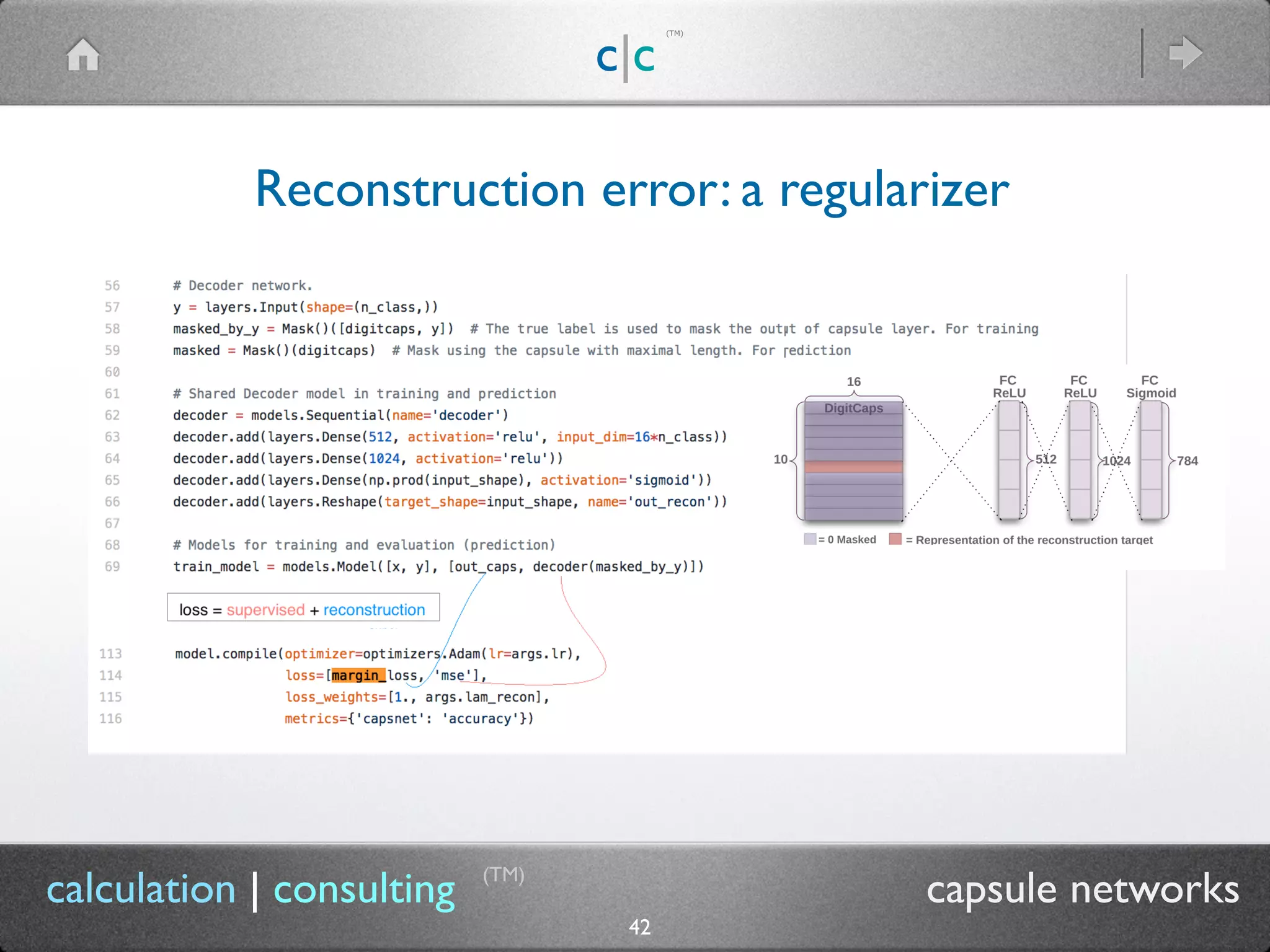
Routing algo: matrix capsules
cluster score = [ log p(x | mixture) - log p(x | uniform)]ii
cosine distance —> Free Energy cost:
EM to find mean, variance, and mixing proportion of Gaussians
“data-points that form a tight cluster from the perspective of one capsule
may be widely scattered from the perspective of another capsule”
p(x | mixture)
ih](https://image.slidesharecdn.com/capsulenetworks-171223023023/75/Capsule-Networks-37-2048.jpg)








This document provides an overview of capsule networks as proposed by Geoff Hinton. It summarizes Hinton's criticisms of convolutional neural networks, including their lack of spatial equivariance and inability to distinguish pose. Hinton proposes capsule networks as an alternative, where capsules encode visual features through vector outputs and can represent the same entity at different poses through affine transformations. Capsule networks use a routing-by-agreement algorithm to determine relationships between capsules, implementing explaining away to aid in segmentation. They have shown improved performance over convolutional networks on tasks requiring pose discrimination and segmentation.













![[PR12] Capsule Networks - Jaejun Yoo](https://cdn.slidesharecdn.com/ss_thumbnails/pr12capsulenetworks-jaejunyoo-171217144319-thumbnail.jpg?width=640&height=640&fit=bounds)






























































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)










