Downloaded 380 times






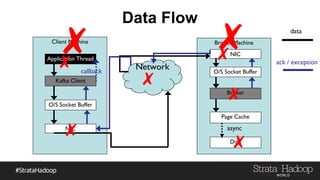
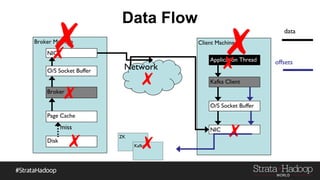

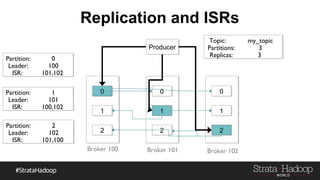


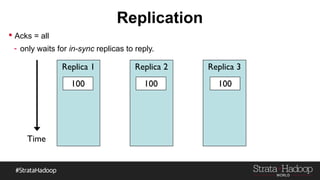


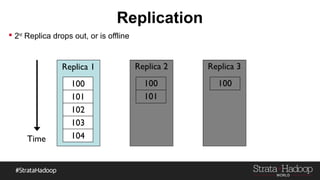




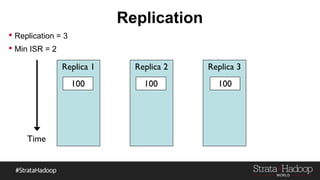

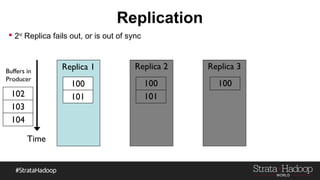
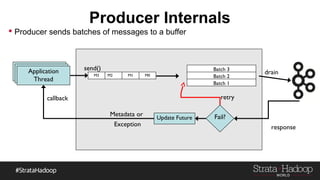




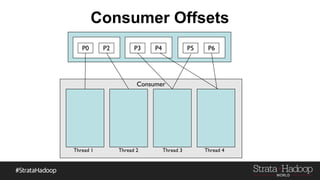
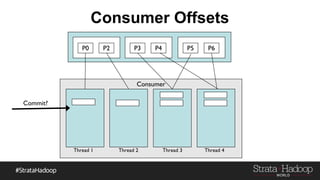
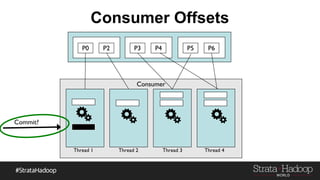
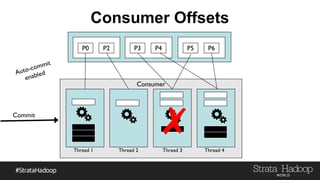
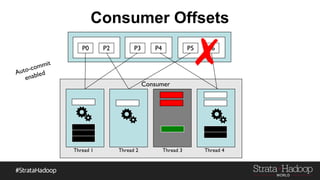


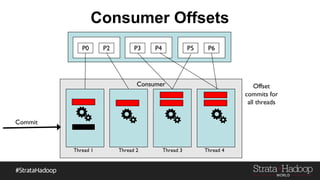
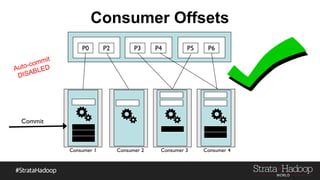






Kafka provides reliability guarantees through replication and configuration settings. It replicates data across multiple brokers to protect against failures. Producers can ensure data is committed to all in-sync replicas through configuration settings like request.required.acks. Consumers maintain offsets and can commit after processing to prevent data loss. Monitoring is also important to detect any potential issues or data loss in the Kafka system.











































































































