Download as PDF, PPTX







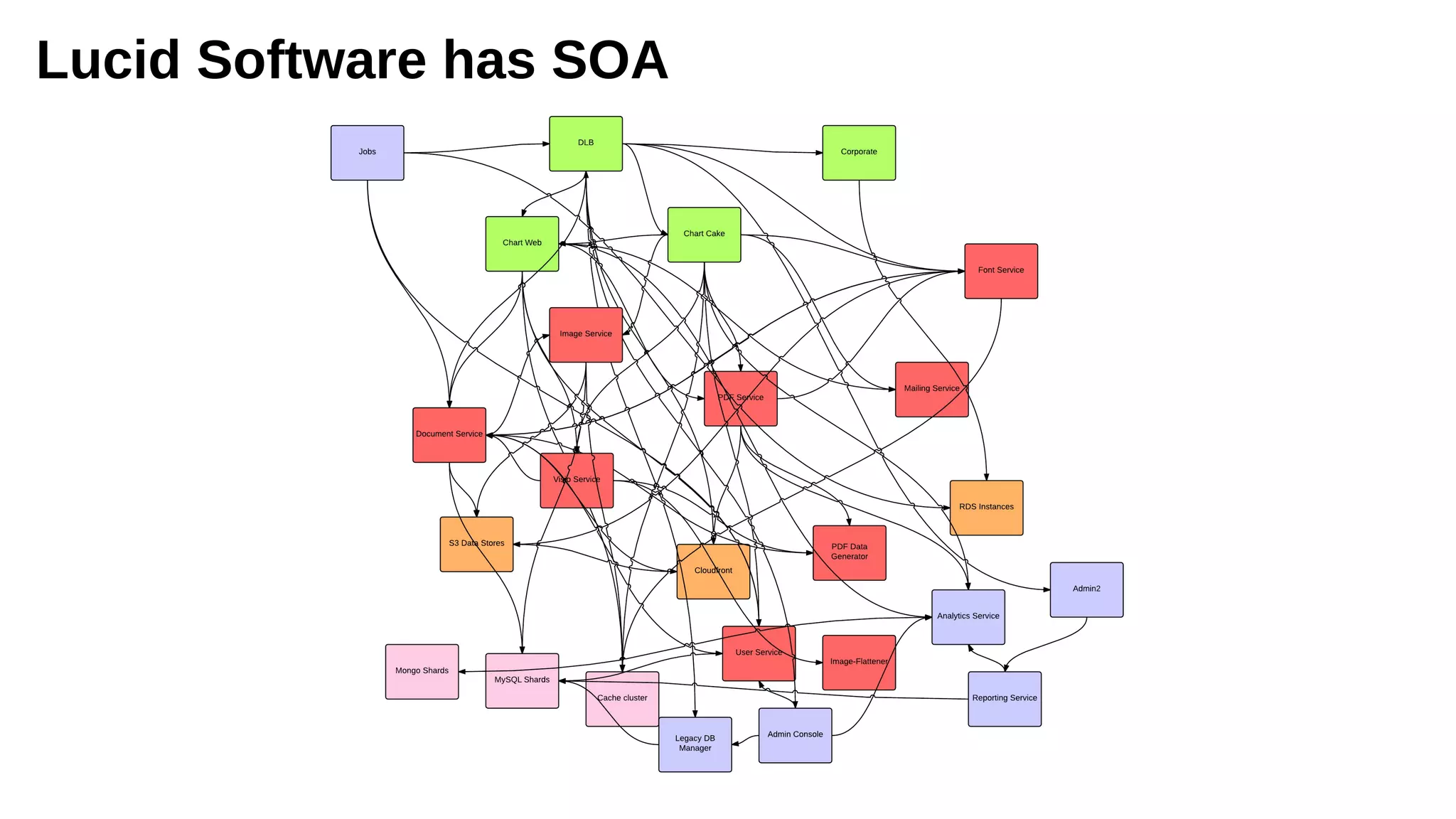



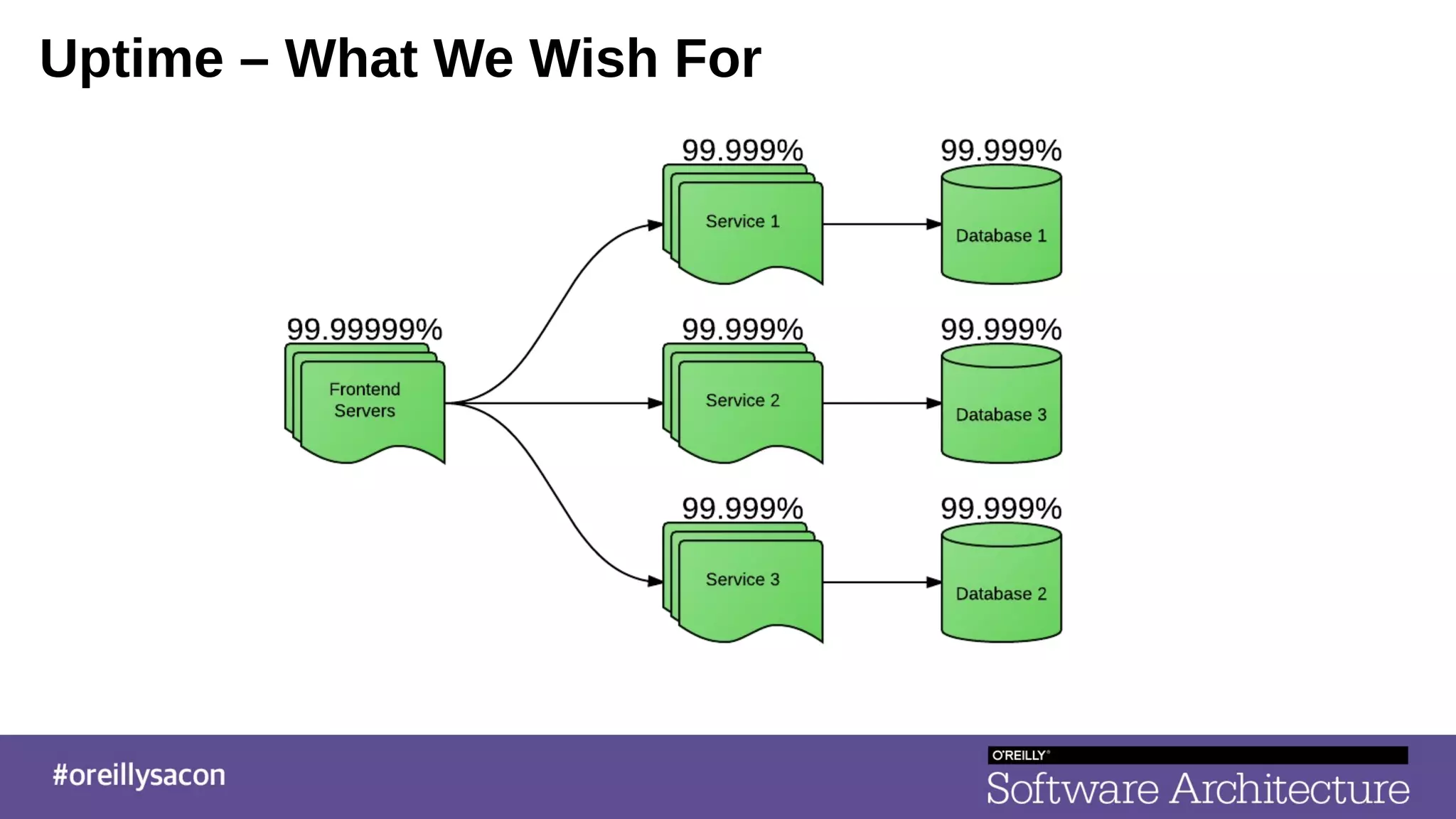
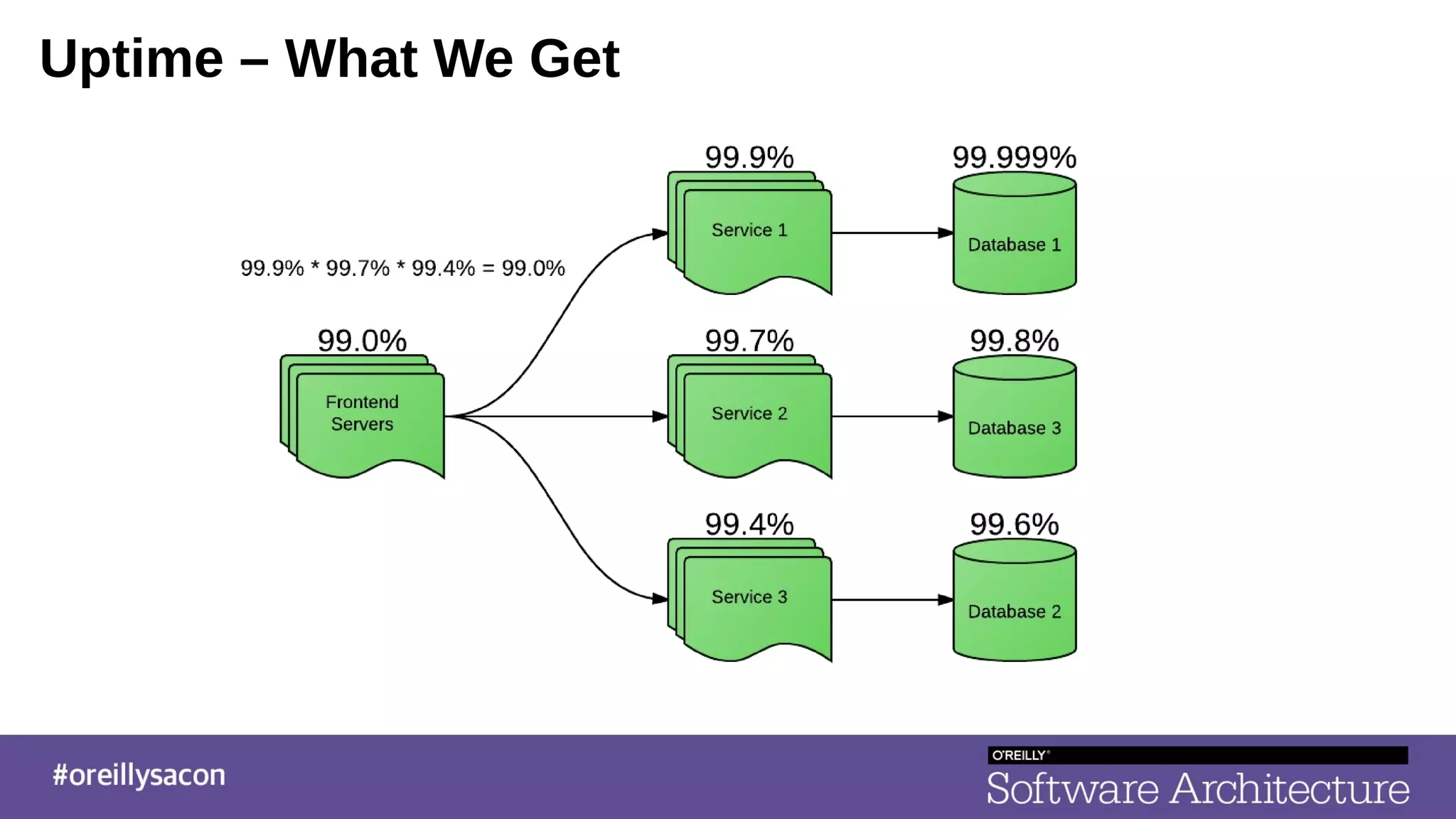


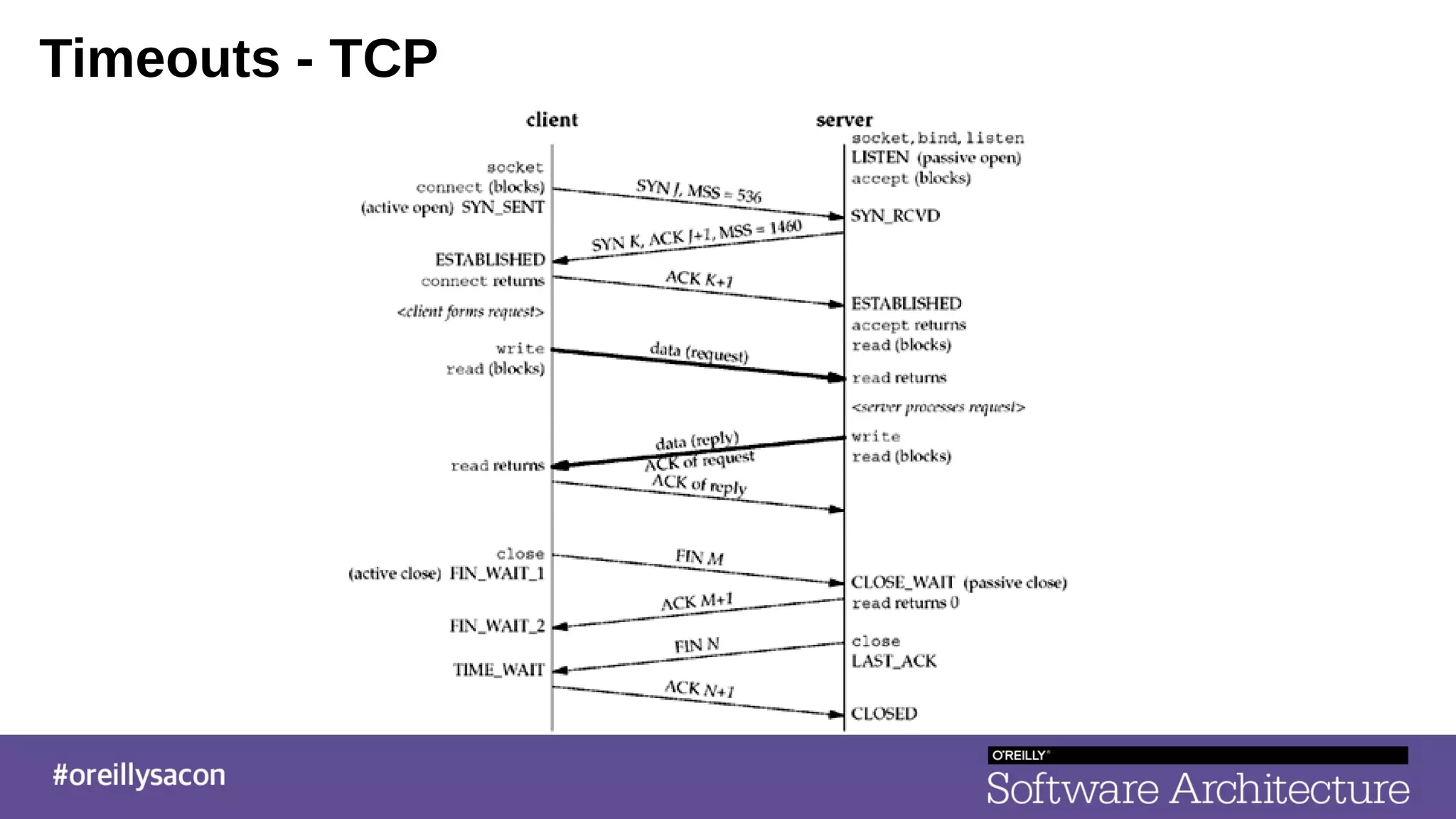
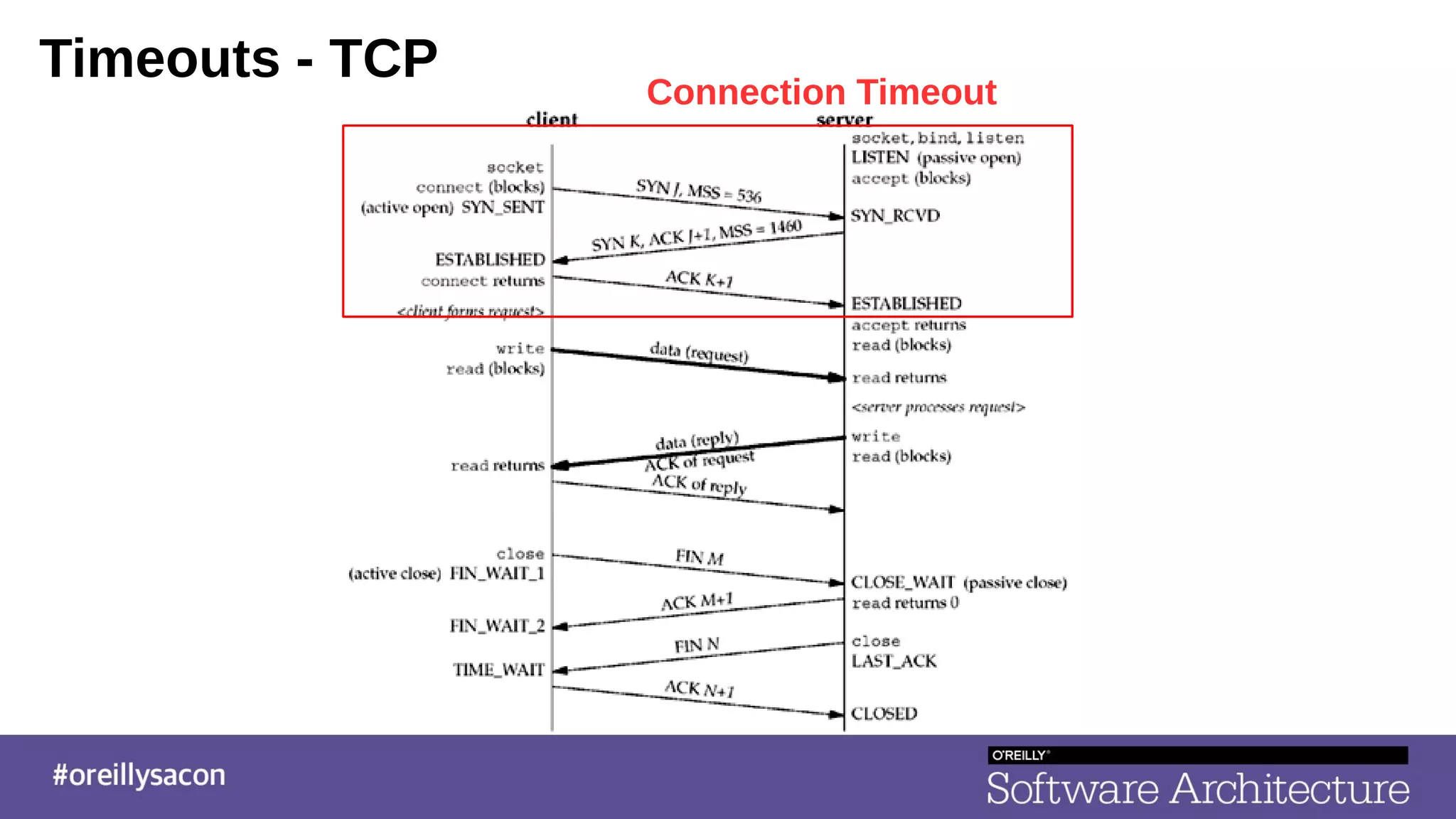
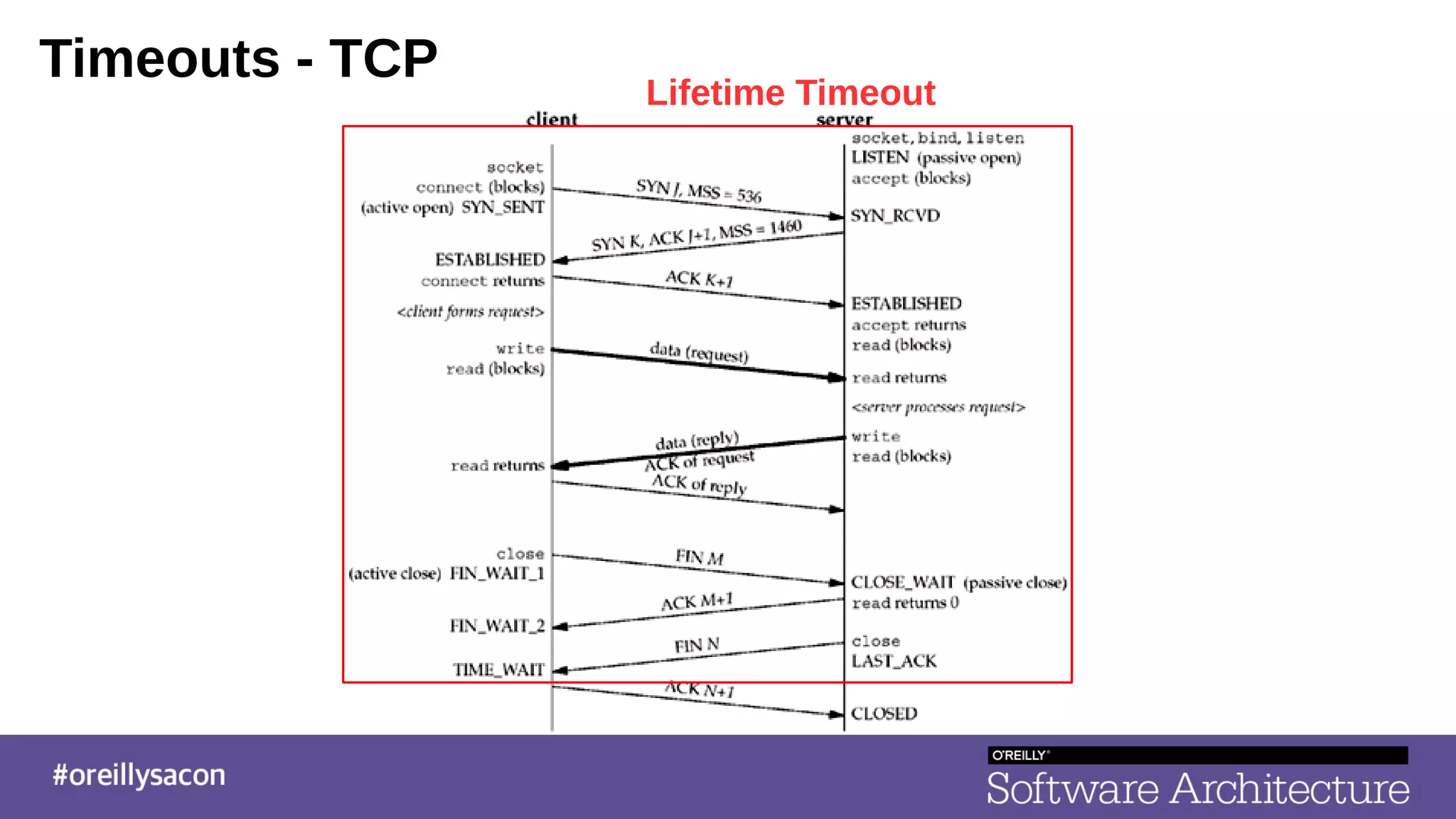
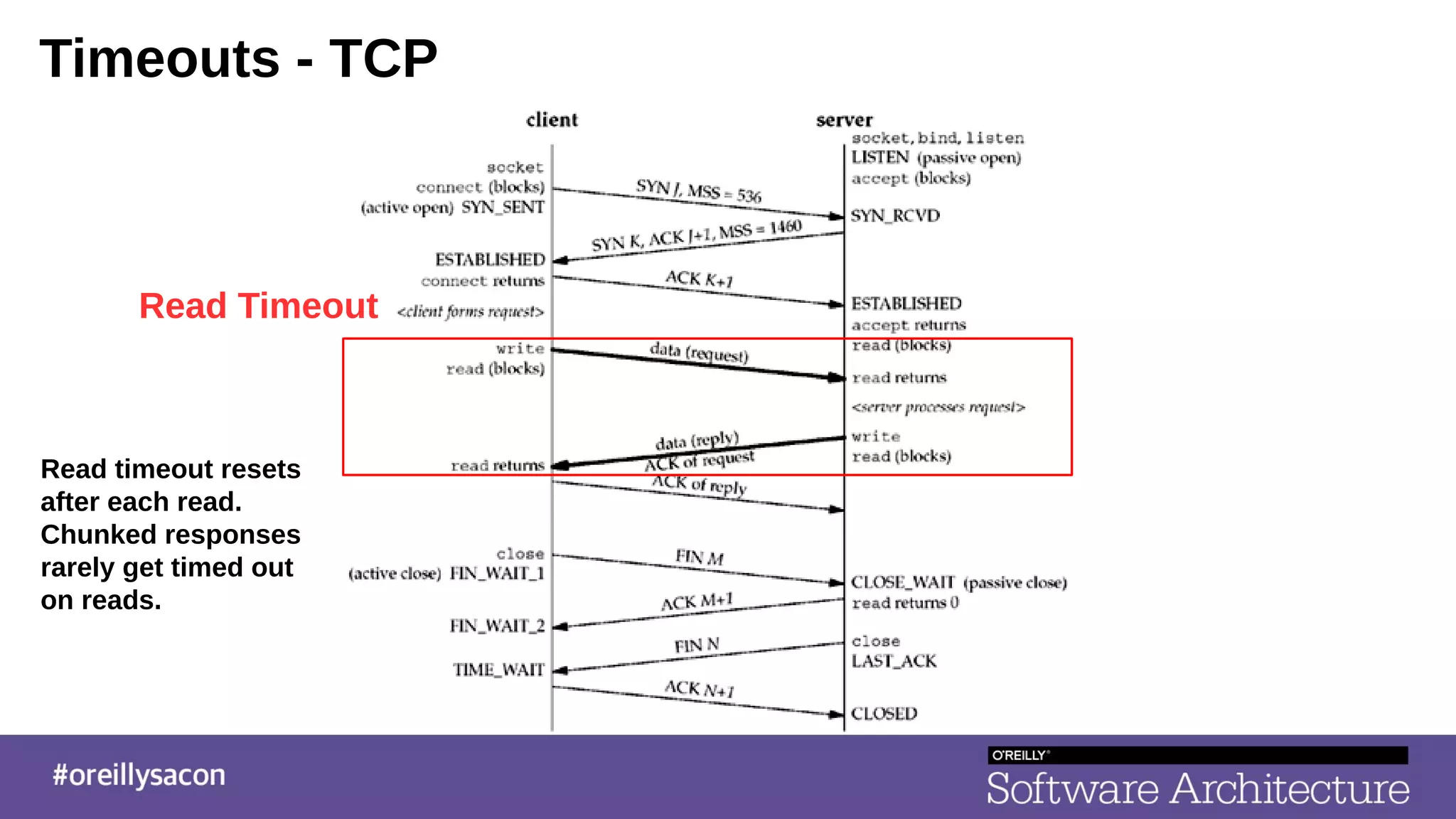


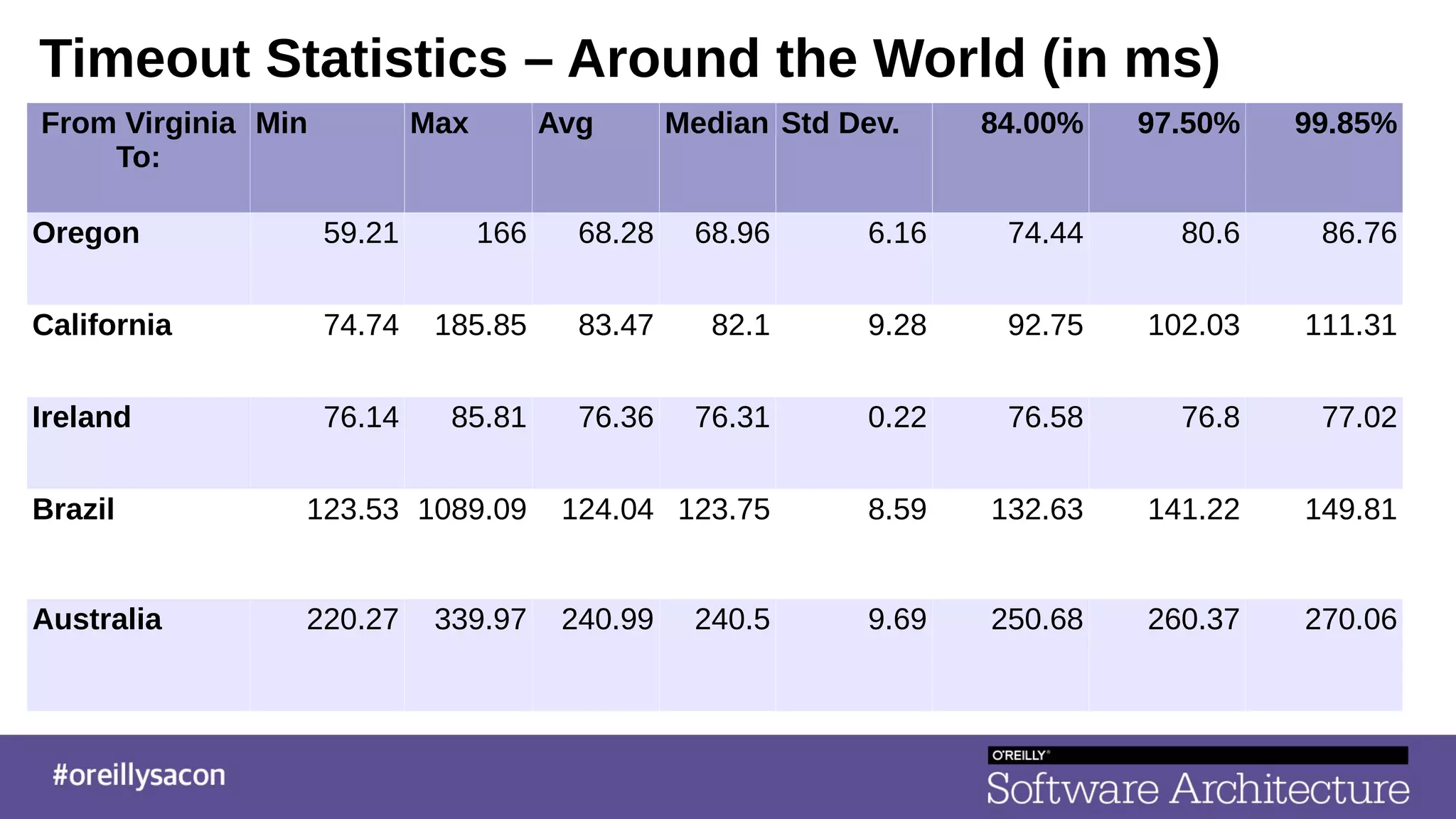
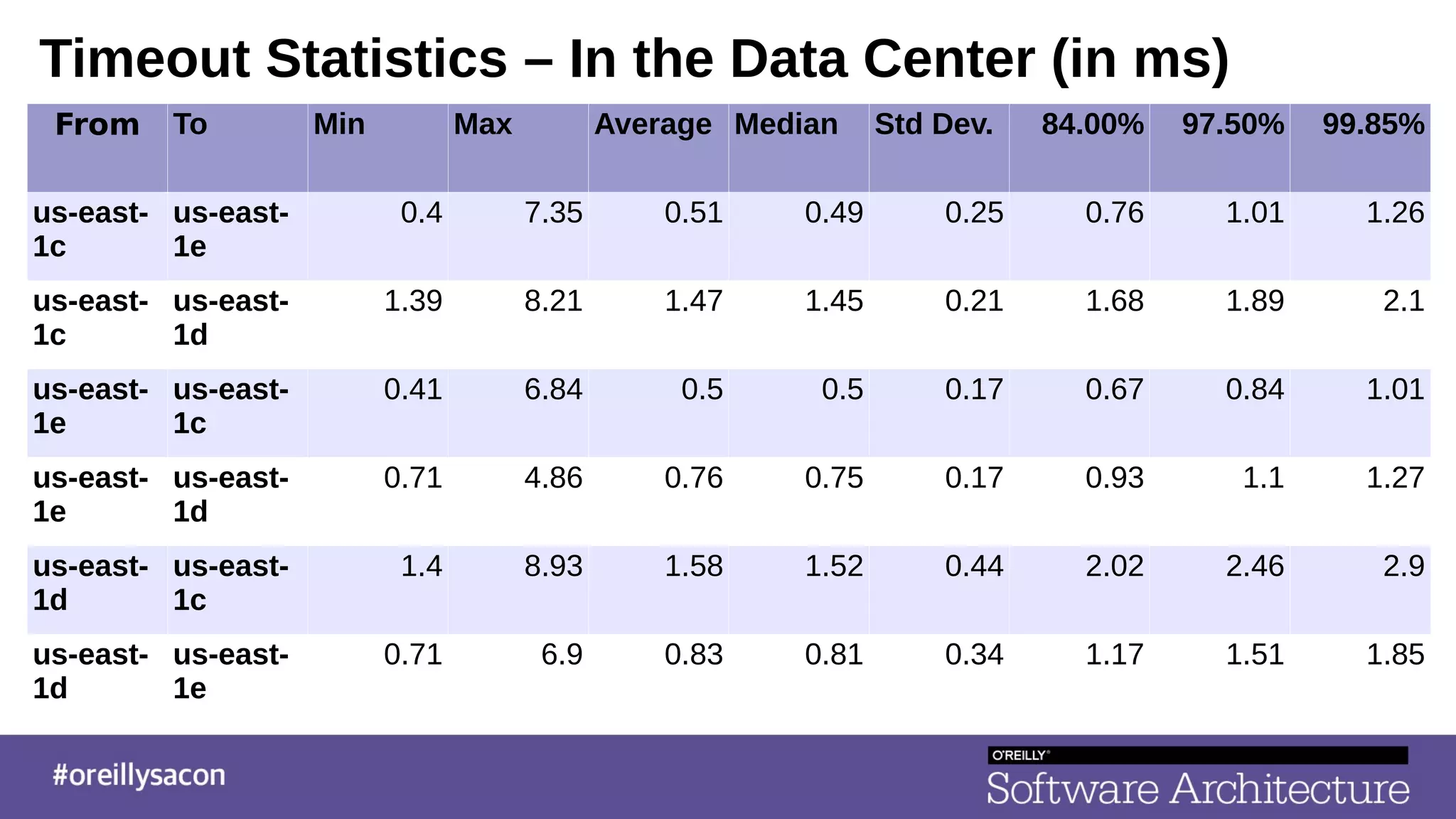












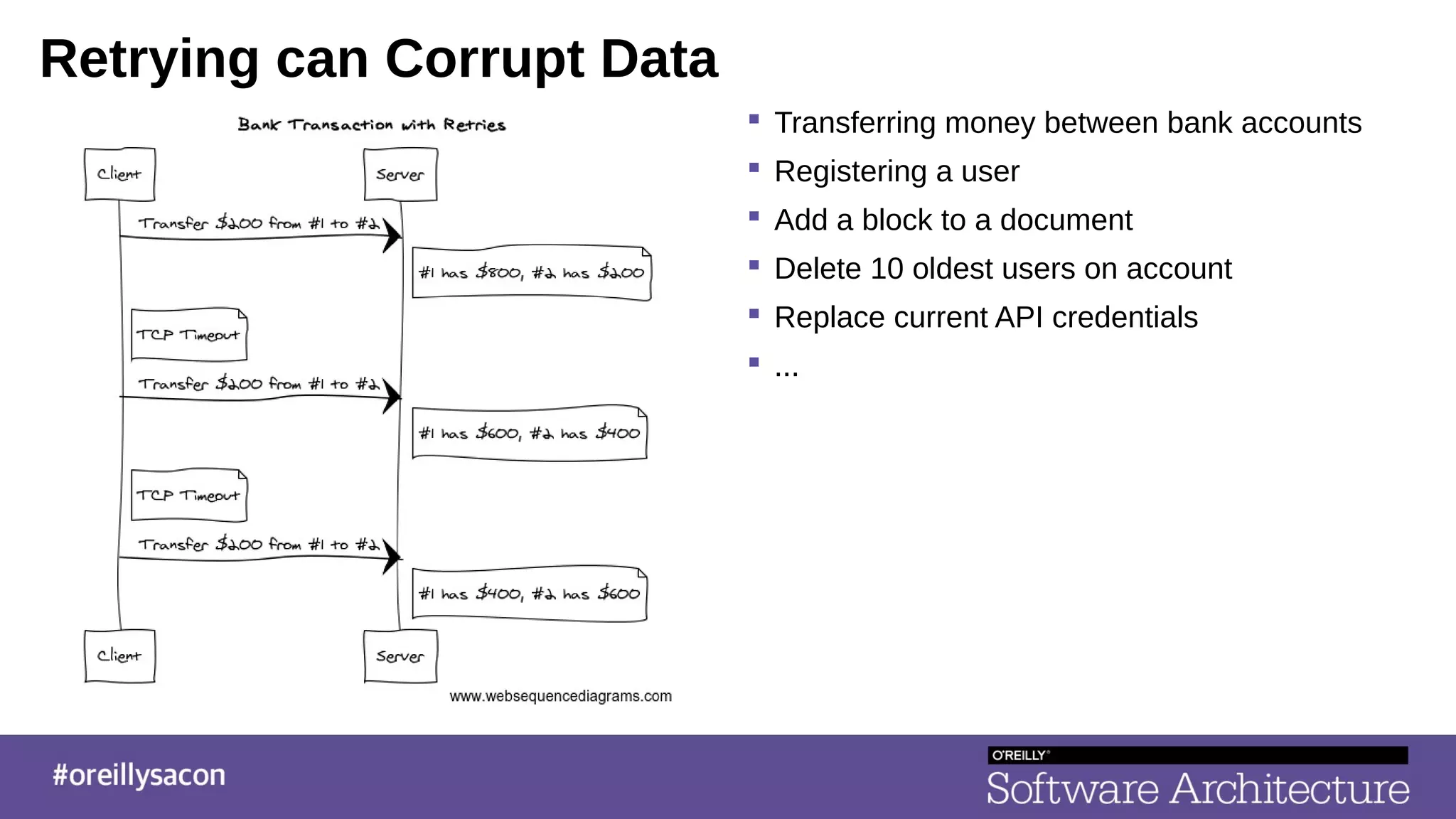


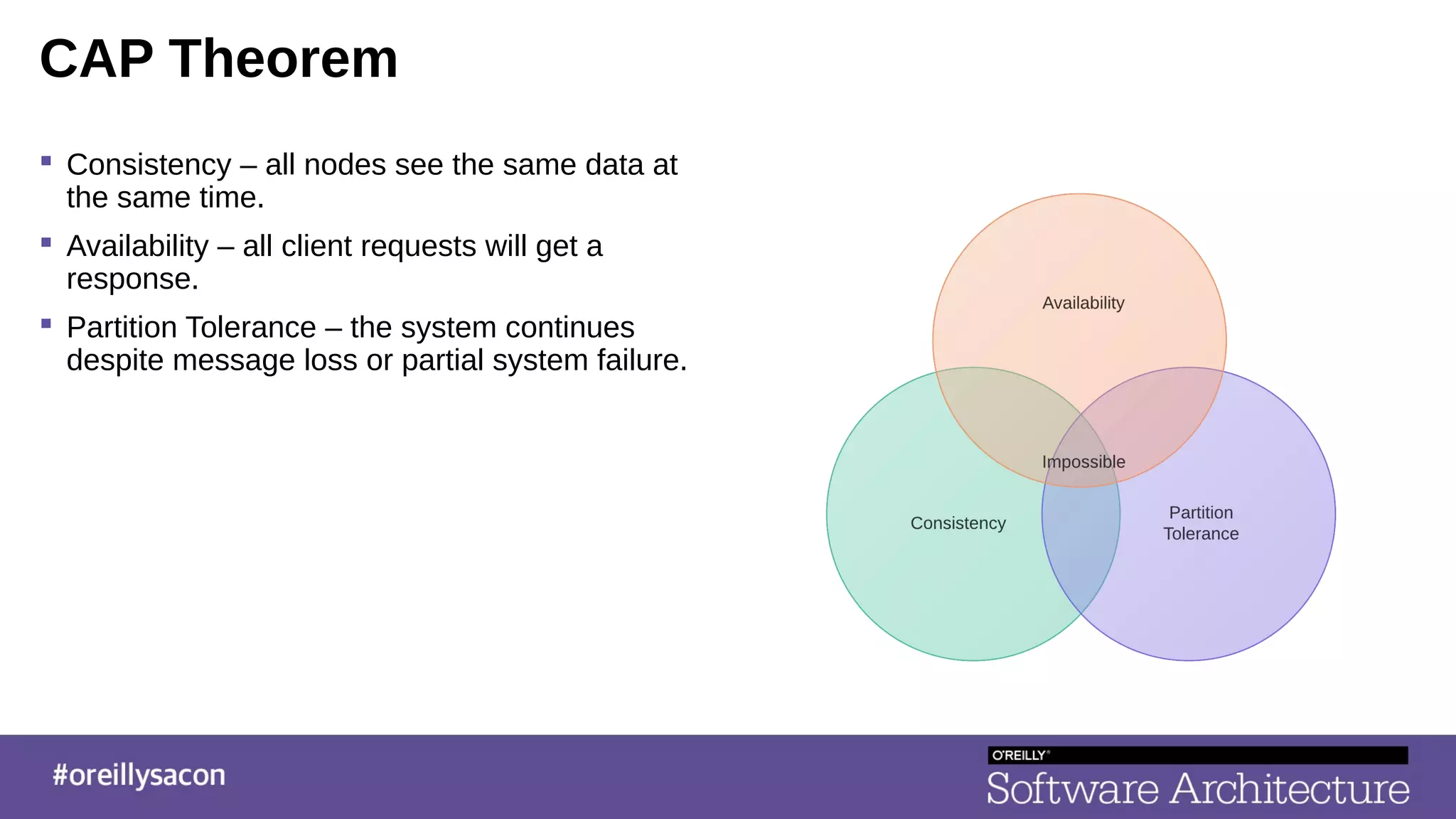






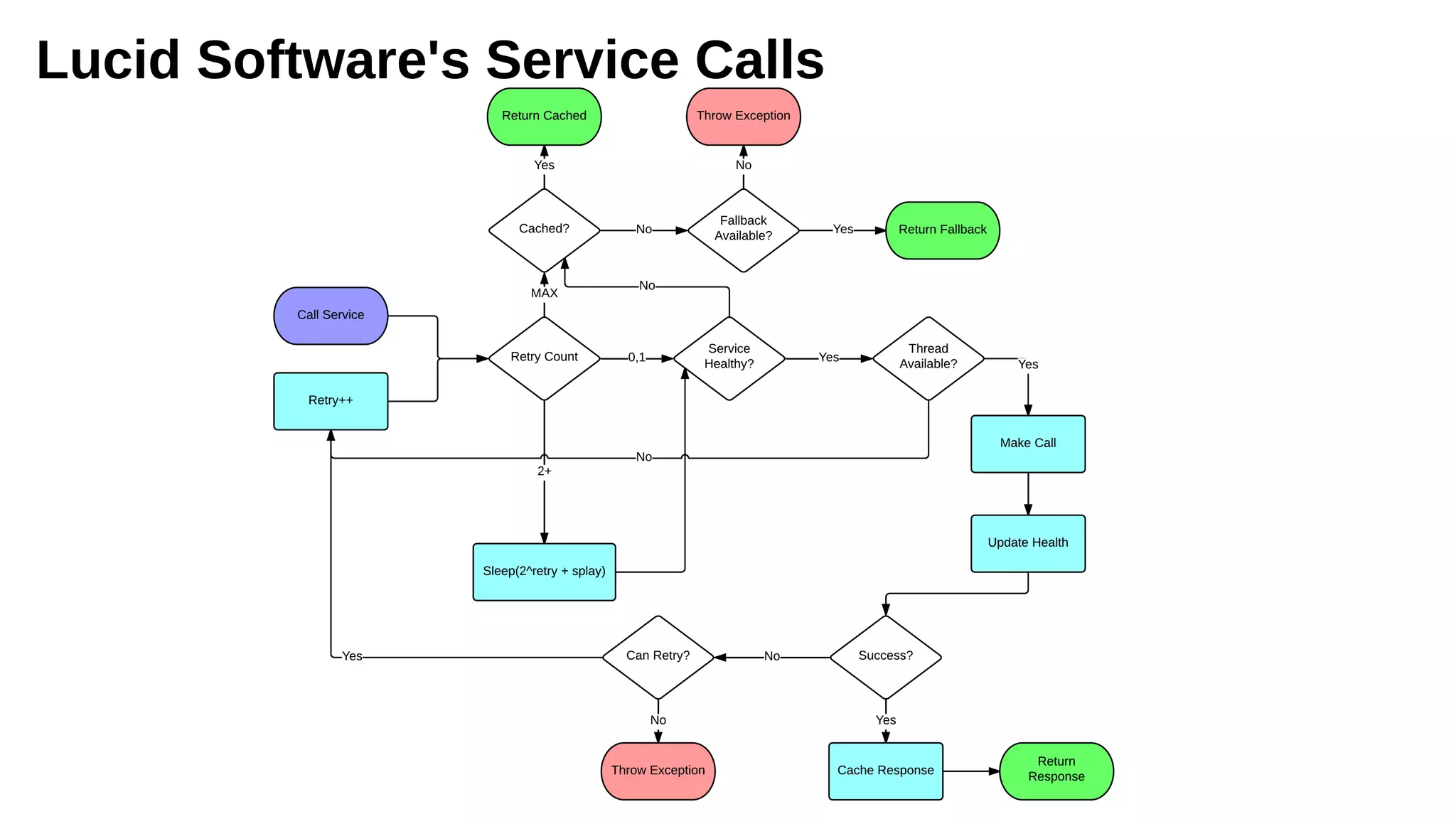


The document discusses the complexities and challenges of distributed systems, highlighting the importance of managing uptime and the trade-offs involved in service-oriented architecture (SOA). It emphasizes strategies for optimizing uptime, such as the use of timeouts, retries, caching, and the need for idempotence to ensure robust operations. It also outlines the implications of network failures and strategies for effective caching and degraded modes to enhance system availability.


































































