Download as PDF, PPTX





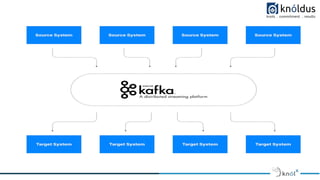



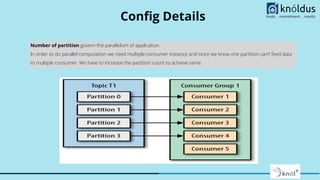


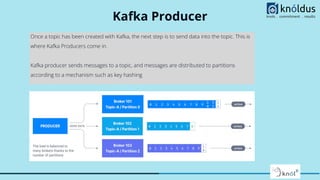




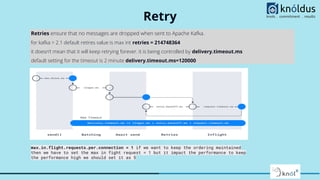


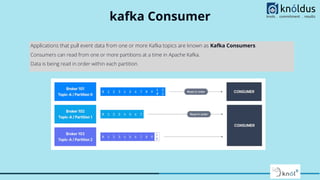

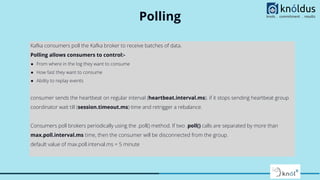



The document provides a comprehensive overview of Apache Kafka for big data applications, detailing its importance in real-time data streaming, features, and components. It discusses Kafka's producer and consumer APIs, message configurations, delivery semantics, and various operational settings like replication and retention policies. The guidelines emphasize maintaining etiquette during sessions and provide critical Kafka configurations for effective data management.














































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)








